
■はじめに
大規模言語モデル(LLM)は、人間のようなテキスト理解や生成を機械にもたらし、人工知能を大きく進歩させています。これらのモデルは最初に膨大なデータセットで事前学習し、一般的な言語パターンを身につけます。しかし、科学的発見や流行の話題など新しい情報が増えると、モデルはすぐに古くなってしまいます。継続的事前学習は、既存のLLMに新しいデータを追加学習させることで、最初からやり直す必要なく最新情報にアップデートできます。
この記事では、継続的事前学習の仕組みや課題、メリットについてわかりやすく解説します。また、FPT AI Studioを使った具体的な実験も紹介します。継続的事前学習には大きな計算資源と効率的なワークフローが必要なため、適切なプラットフォーム選びが重要です。
NVIDIAの技術を基盤にしたFPT AI Factory上のFPT AI Studioは、柔軟なGPUオプション、セキュリティ、インフラ準備不要の統合プラットフォームを提供します。そのため、大規模かつ複雑なトレーニングワークフローも簡単・高速に実行できます。
この記事を読み終える頃には、なぜ継続的事前学習が重要なのか、FPT AI StudioがどのようにLLMを柔軟かつ最新に保つのに役立つかが理解できるでしょう。
II. LLMにおける継続的事前学習
1. LLMの事前学習とは?
事前学習はLLMの基礎であり、ウェブテキストや書籍、記事など多様で大規模なデータセットを使ってモデルを訓練します。これにより、言語の構造や意味を学びます。次の単語を予測することで、ラベル付けされていない莫大なデータから学習します。こうして、チャットボットやコンテンツ生成など様々なタスクに使える多用途なモデルが出来上がります。
2. 事前学習の課題
- 計算資源:数千のGPUが必要で、膨大なエネルギーやコストがかかります。
- データ品質:多様で偏りのないデータセットが必要で、偏った出力や倫理的問題を回避しなければなりません。
- 拡張性:大規模なデータセットやモデルの管理は複雑で、効率的なシステムが求められます。
- 陳腐化:新しい知識が現れると、事前学習済みモデルはすぐに古くなってしまいます。
3. 事前学習から継続的事前学習へ
従来の事前学習は一度きりの作業ですが、現実の世界は日々変化しています。新しいトレンドや研究、言語パターンが絶えず生まれます。継続的事前学習はモデルを段階的にアップデートし、新しい分野や情報にも対応できるようにします。これにより、フルリトレーニングよりも資源を節約し、医療や技術など動きの激しい分野においてもモデルを最新に保てます。
4. 継続的事前学習とは
継続的事前学習とは、既に事前学習されたLLMに対して新しいデータや特定分野のデータを追加で学習させ、知識を強化する方法です。ファインチューニングが特定タスクへの適応を目的とするのに対し、継続的事前学習はモデルの全体的な能力を広げます。新しいデータを漸進的に学習しながら、過去の知識を失わないようバランスを取る技術が使われます。例えば、最新ニュースや科学論文でモデルをアップデートし、常に現状に合わせることができます。
5. 継続的事前学習の課題
- カタストロフィック・フォゲッティング(破滅的忘却):新しい学習で古い知識が上書きされ、以前のタスクの性能が落ちることがあります。
- データ選定:ノイズや偏りを避け、質の高いデータを選ぶことが重要です。
- モデルの安定性:モデルの堅牢性を維持し、慎重な監視が必要です。
6. 主なユースケース
継続的事前学習は以下のような場面で効果を発揮します:
- ドメイン適応:医療記録や法律文書、金融レポートなど特定分野のデータで追加学習することで、その分野でより正確で信頼性の高いコンテンツ生成が可能になります。
- 知識更新:新しい出来事や技術、科学的発見が現れると、従来の静的なデータセットで学習したモデルはすぐに古くなります。継続的事前学習で定期的・リアルタイムに最新情報を取り込み、モデルを常に最新状態に保てます。
- 多言語対応の強化:多くの言語モデルは主要な言語しか対応していませんが、継続的事前学習を通じてリソースの少ない言語や方言、専門用語などにも対応でき、多様な人々が使える技術に進化します。
7. なぜファインチューニングだけではだめなのか
ファインチューニングは特定タスクごとにラベル付きデータ(例:QAペア)でモデルを調整し、明確なタスクでの性能を高めます。
しかし限界もあります:
- タスク固有:汎用的な知識更新には向いていません。
- 過学習リスク:小規模データだとモデルが汎用性を失うこともあります。
III. FPT AI Studioでの継続的事前学習
ベトナム語LLMの関心が高まる中、FPT Smart Cloudが開発したノーコードプラットフォーム「FPT AI Studio」を使い、実際に継続的事前学習を実験しました。FPT AI Studioはパイプラインの設計・管理が簡単で、データ管理やリソース設定も容易なため、LLMの継続的事前学習に最適です。
主な特徴は以下の通りです:
- パイプライン作成・管理のための直感的なグラフィカルインターフェース
- S3バケットへの接続が簡単なデータ管理(Data Hub)
- 計算リソースやハイパーパラメータの簡単な設定
- モデルのファインチューニングでよく発生する課題にも対応
- 学習済みモデルを安全にModel Hubに保存
- トレーニングジョブの進捗や履歴を明確に管理
この記事では、meta-llama/Llama-3.2-1Bの継続的事前学習を行い、ベトナム語性能の強化を目指します。
1. データセットの準備
ベトナム語データセットで追加学習を行い、LLMのベトナム語対応力を高めます。使用した主なデータセット:
- vietgpt/wikipedia_vi – 5.6GB
- Uonlp/CulturaX(ベトナム語部分)– 6GB
- Ontocord/CulturaY(ベトナム語部分)– 2.4GB
- 1万冊のベトナム語書籍 – 1.7GB
合計で20.9GB、各サンプルは.txt形式で保存。データの0.1%を評価用、残り約99.9%をトレーニング用として使います(約28億トークン)。
トレーニング用・評価用データはFPT AI Studio形式に従い.jsonlファイルで保存します。これらをS3バケットにアップロードし、Data Hubに接続してください。

図1. FPT AI StudioのLLMトレーニングで必要な.jsonlファイル形式の例
S3バケットをFPT AI StudioのData Hubに接続する手順:
- ステップ1:Data Hubタブに移動
- ステップ2:「Create Connection」をクリック
- ステップ3:S3の設定情報を入力
- ステップ4:「Save」をクリック
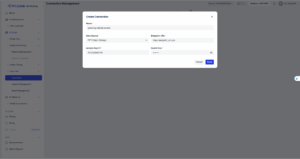
図2. Data Hubでの「接続の作成」ダイアログ
2. トレーニングの開始
NVIDIA H100 SXM5(8基、128CPU、1536GB RAM)と上記データで継続的事前学習を行います。ハイパーパラメータを設定し、以下の手順で進めます:
{
"batch_size": 8,
"checkpoint_steps": 1000,
"checkpoint_strategy": "epoch",
"disable_gradient_checkpointing": false,
"distributed_backend": "ddp",
"dpo_label_smoothing": 0,
"epochs": 2,
"eval_steps": 1000,
"eval_strategy": "epoch",
"finetuning_type": "full",
"flash_attention_v2": false,
"full_determinism": false,
"gradient_accumulation_steps": 16,
"learning_rate": 0.00004,
"logging_steps": 10,
"lora_alpha": 32,
"lora_dropout": 0.05,
"lora_rank": 16,
"lr_scheduler_type": "linear",
"lr_warmup_steps": 0,
"max_grad_norm": 1,
"max_sequence_length": 2048,
"mixed_precision": "bf16",
"number_of_checkpoints": 1,
"optimizer": "adamw",
"pref_beta": 0.1,
"pref_ftx": 0,
"pref_loss": "sigmoid",
"quantization_bit": "none",
"save_best_checkpoint": false,
"seed": 1309,
"simpo_gamma": 0.5,
"target_modules": "all-linear",
"weight_decay": 0,
"zero_stage": 1
}
FPT AI Studioでトレーニングパイプラインを設定
- ステップ1:Pipeline作成:Pipeline Managementで「Create Pipeline」をクリック
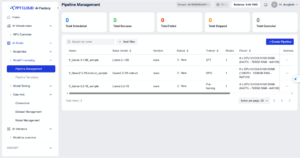
図3. モデルファインチューニングにおけるパイプライン管理インターフェース
- ステップ2:テンプレート選択:「Blank」テンプレートを選択し「Let’s Start」をクリック
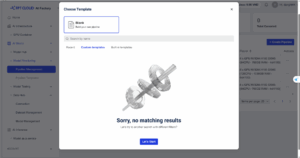
図4. FPT AI Studioのパイプライン作成プロセスにおける「テンプレート選択」ダイアログ
- ステップ3:ベースモデルとデータの設定:モデルとデータセット情報を入力し「Next Step」 をクリック
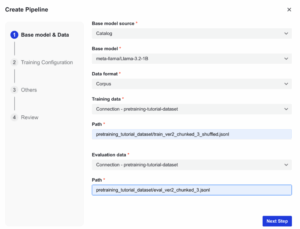
図5. 「パイプライン作成」における「ベースモデル&データ」
- ステップ4:トレーニング設定:「Built-in Trainer」から「Pre-training」を選び、詳細設定でJSONを貼り付け。インフラは「Single-node 8xGPU NVIDIA H200 SXM5」を選択し「Next Step」をクリック。
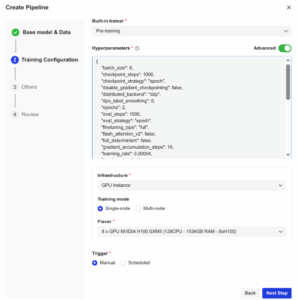
図6. 「パイプライン作成」における「トレーニング設定」
- ステップ5:その他設定:事前学習なのでテストデータは不要。「Send Email」をチェックしておくと完了通知が届く。「Next Step」をクリック。
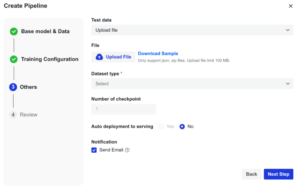
図7. 「パイプライン作成」における「その他」
- ステップ6:レビューと送信:パイプラインの名前と説明を入力し、設定内容を確認後「Submit」
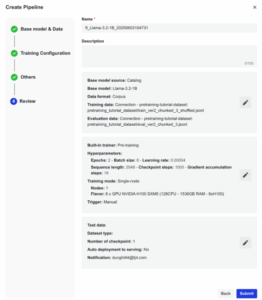
図8. 「パイプライン作成」における「レビュー」
- ステップ7:トレーニング開始:「Start」でトレーニングを実行
- ‘Start’ the training pipeline to begin the training process.

図9. FPT AI Studioでトレーニングパイプラインを開始
トレーニング中は、Model Metricsタブでlossやeval loss、学習率などを追跡できます。
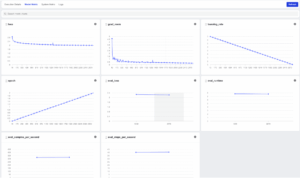
図10. トレーニング指標
学習後、継続的事前学習済みモデルはModel Hub → Private Modelに保存されます。個人利用のためにダウンロードも可能です。
図11. Model Hub内の継続的事前学習済みモデル
3. 結果
■結果
学習後、lossは2.8746から1.9966に、eval lossは2.2282まで低下し、ベトナム語への適応が進んだことを示します。
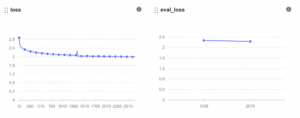
図12. 継続的事前学習プロセス中のLossおよびEval Loss指標
ViLLM-Evalのベトナム語ベンチマークで、EleutherAI EvalHarnessにより継続的事前学習モデルを評価し、ベースモデルと比較しました。すべてのタスクで指標が一貫して向上し、例えばlambada_viタスクの正答率は0.2397から0.3478に約11%上昇しました。
| Model | comprehension_vi | exams_vi | lambada_vi | wikipediaqa_vi |
| Baseline | 0.6156 | 0.2912 | 0.2397 | 0.321 |
| Continued Pretraining | 0.6178 | 0.3318 | 0.3478 | 0.397 |
表1. VILLM-Evalのベトナム語ベンチマークタスクにおける、ベースラインLlama-3.2-1Bモデルと継続的事前学習済みモデルの性能(正解率)比較
さらに、exams_viの数学・物理・生物・文学など各分野のサブセットでもベースラインより明確な改善を示しました。
| Model | exams_vi
_dia |
exams_vi
_hoa |
exams_vi_su
|
exams_vi_sinh
|
exams_vi_toan
|
exams_vi_van
|
exams_vi_vatly
|
| Baseline | 0.3235 | 0.2522 | 0.2897 | 0.2819 | 0.2572 | 0.3192 | 0.2976 |
| Continued Pretraining | 0.3791 | 0.2609 | 0.3563 | 0.3113 | 0.2653 | 0.3662 | 0.3 |
表2. exams_viのさまざまな分野のサブセットにおける、ベースラインモデルと継続的事前学習済みモデルの詳細な性能(正解率)比較
これらの改善は、コストを最小限に抑えつつ高性能なベトナム語LLMが構築可能であることを示しており、フィンテックやエドテックなど分野特化型応用の可能性を広げます。
IV. まとめ
言語と知識が急速に進化する時代、LLMも常に最新である必要があります。継続的事前学習は、既存知識を維持しつつ新しいデータを組み込む有効な解決策です。従来の事前学習やタスク特化型ファインチューニングと異なり、ヘルスケア・金融・教育など動的な分野やベトナム語のようなリソースが限られた言語にも持続的なパフォーマンス向上の道を提供します。
FPT AI Studioでの実験から、継続的事前学習は実現可能かつ非常に効果的であることがわかりました。Llama-3.2-1Bを厳選したベトナム語データセットで学習することで、多くのベンチマークで大きな性能向上を達成しました。適切なツールがあれば、高品質なベトナム語LLMの構築も十分に可能です。
FPT AI Studioの特長は、データセットの統合から強力なGPUの制御、効率的なパイプライン管理まで、シームレスなエンドツーエンド体験です。複雑さを排除し、モデル改善と価値提供に集中できます。ドメイン特化型チャットボットの開発、多言語強化、LLMの本番運用まで、FPT AI Studioは自信を持ってAIを構築できるツール・インフラ・柔軟性を提供します。
FPT AI Factoryの詳細はこちら:https://fptcloud.com/ja/product/fpt-ai-factory-ja/
ホットライン:0800-300-9739
メール:support@fptcloud.jp


