
2025年9月23日にベトナム、ホーチミンで開催された「NVIDIA AI Day Ho Chi Minh City」において、FPTスマートクラウド(FPT Corporation)のソリューションアーキテクト兼上級コンサルタントPham Vu Hung氏が、「AI Factory Playbook:開発者のための安全かつ高速なGen AIアプリケーション構築ガイド」と題した基調講演を行いました。
Hung氏は、国内で展開されたAIファクトリーを活用し、NVIDIA H100/H200 GPUクラウドプラットフォーム上で、生成AIモデルの構築からエンタープライズ向けAIエージェントのデプロイまで、エンドツーエンドのAI開発を実現する方法について解説。特に、迅速な開発と最適化された推論環境という自社開発AIファクトリーの利点に加え、具体的なユースケースも紹介されました。
- 国内FPT AI FactoryによるエンドツーエンドAI開発:データセンターという安全な環境で、生成AIからAIエージェントまでの完全な開発を実現。
- NVIDIA H100/H200 GPUによる加速:最新GPUによって学習・推論を高速化し、開発期間を大幅に短縮。
- 生成AI構築とファインチューニング:最先端モデル構築と個別データによるチューニングで高精度なモデルを実現。
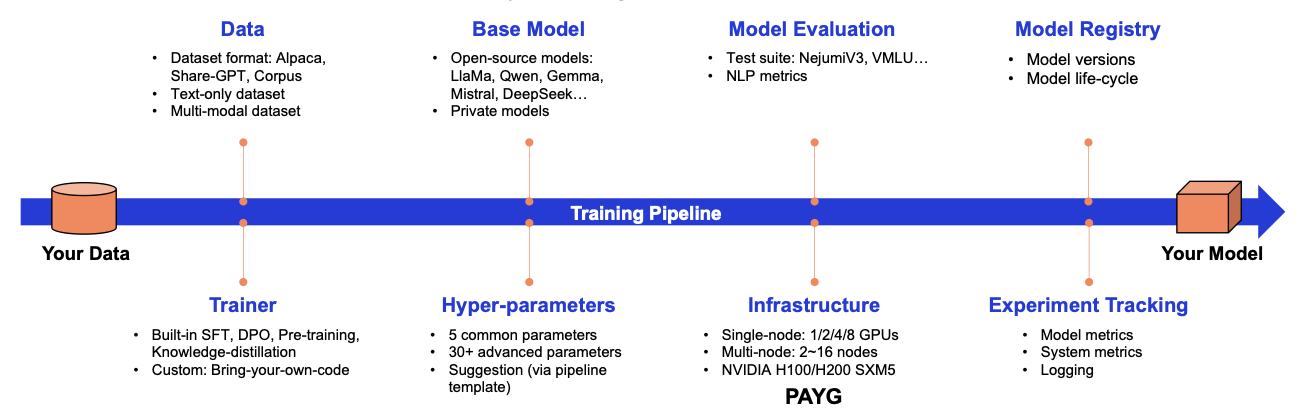
AI/MLスタックの構築
FPT AI Factoryは、NVIDIA認定のTier 3 & 4データセンター(2025年6月版TOP500リストで36位・38位)上に構築された包括的なAI/MLインフラストラクチャスタックを提供しています。主なサービスには、GPUコンテナ、GPU仮想マシン、FPT AI Studioなどがあり、Bare MetalやGPUクラスタ、AIノートブック、FPT AI Inferenceも利用可能です。
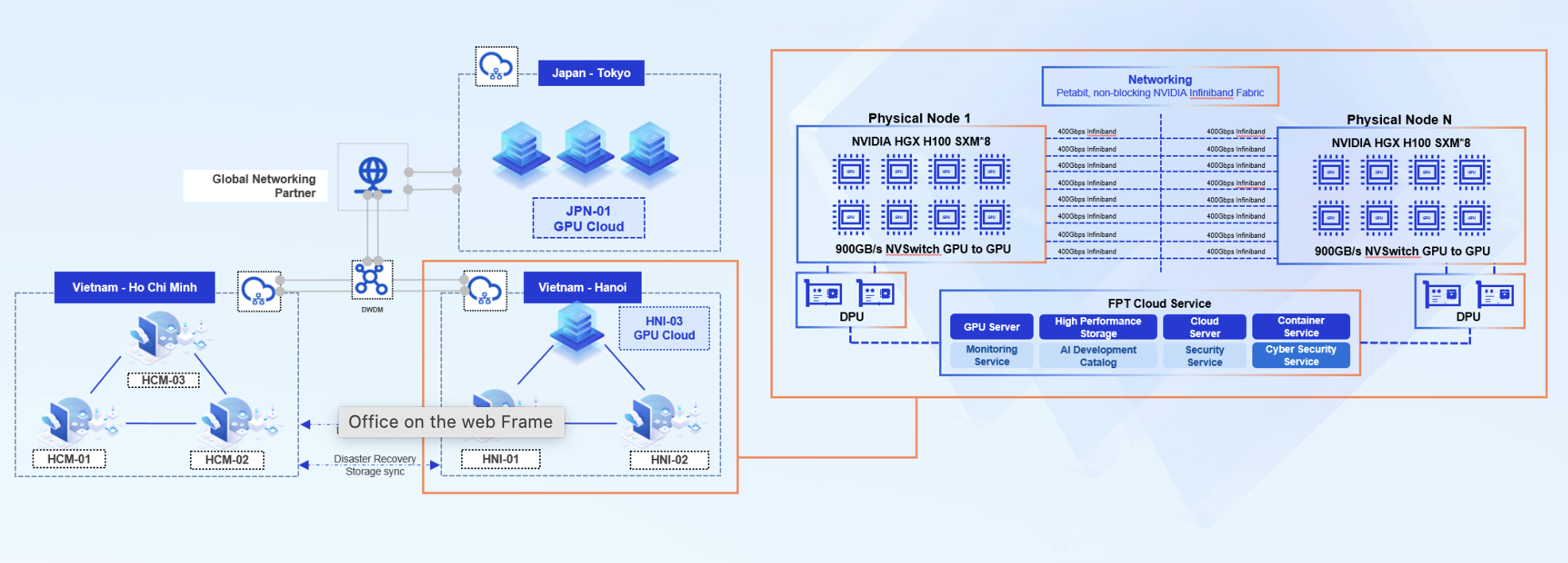
- 画像: FPT AI Factory における AI/ML スタックアーキテクチャ。
- GPUコンテナ:実験ワークロード向けに設計されており、モニタリング・ロギング・協働型ノートブックを内蔵。データ共有、コード作成、ユニットテスト、実行が柔軟な環境で容易に可能。
- GPU仮想マシン:学習・推論両対応の多目的VM。1~8GPU/VM、最大141GB VRAM/GPUなど柔軟な構成。
- GPUクラスタ:分散学習・大規模推論向け拡張性インフラ。NVLink、MIG/MPS/タイムスライスGPU共有、監査ログやCISベンチマークなど高度なセキュリティアドオン付き。
- AIノートブック:主要AI/MLライブラリプリインストール済みの管理型JupyterLab環境。エンタープライズグレードGPU上でセットアップ不要で即コーディング可能。従来のノートブック環境比で最大70%のコスト削減。
- FPT AI Studio:ノーコード/ローコードMLOpsプラットフォーム。データパイプライン、ファインチューニング戦略(SFT、DPO、継続学習)、実験追跡、モデルレジストリを統合。ドラッグ&ドロップGUIでモデルを迅速にチューニングし、中央モデルハブに保存可能。
- FPT AI Inference:競争力のあるトークン単価の即利用API。ファインチューニング済みモデルを迅速かつ低コストでデプロイ可能。
講演では、Hung氏はAI Factoryの広範な機能だけでなく、顧客事例を通じてその実用性も強調しました。 例えば、FPTは日本のIT企業と協力し、300GB超のデータセットでDonut(Document Understanding Transformer)モデルをファインチューニング。GPUコンテナとFPT Object Storageの組み合わせにより、大規模な文書データを効率的に処理しコストも最適化。これは、企業がFPT AI Factoryのインフラを実際のワークロードに活用できる実例です。

- 画像: FPT AI Factory における AI/ML スタックアーキテクチャ。
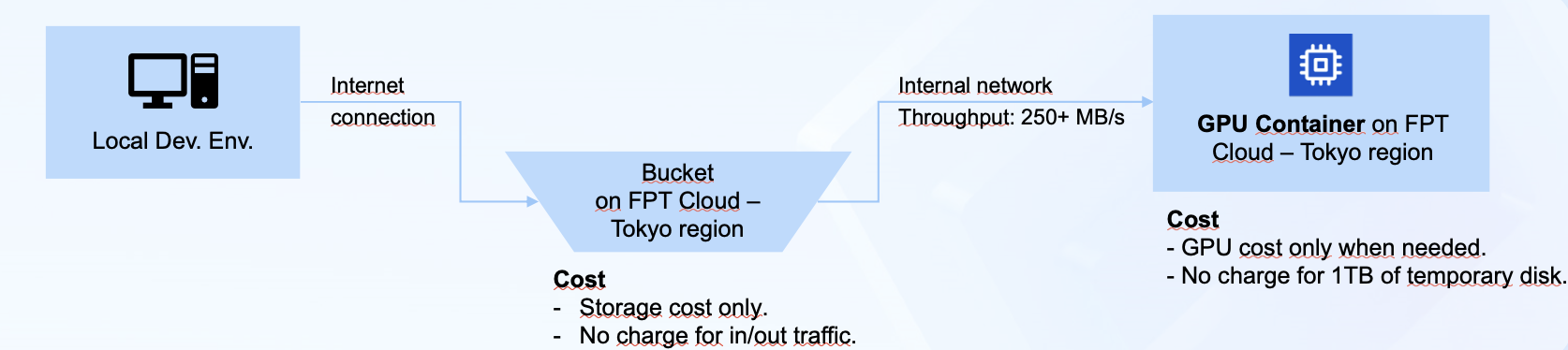
実運用AIソリューションの展開加速
特に注目されたのは、動画検索・要約AIカメラエージェントのライブデモ。ワークフローはシンプルながら強力です。動画を選択し、探したい内容の簡単な説明を入力するだけで、エージェントが関連セグメントを自動判別し、リアルタイムで要約を生成します。
これを可能にしているのがNVIDIA Blueprintsの統合です。あらかじめ検証済みのソリューションアーキテクチャとツール群で、プロトタイプをゼロから数ヶ月かけて構築する代わりに、1日でコンセプトから稼働するデモまで到達できました。この加速はソリューションの実現可能性の検証だけでなく、企業が自社動画課題にAIをどう応用できるかを具体的にイメージする助けとなります。

- 画像:The architecture of the AI Camera Agent solution (NVIDIA)
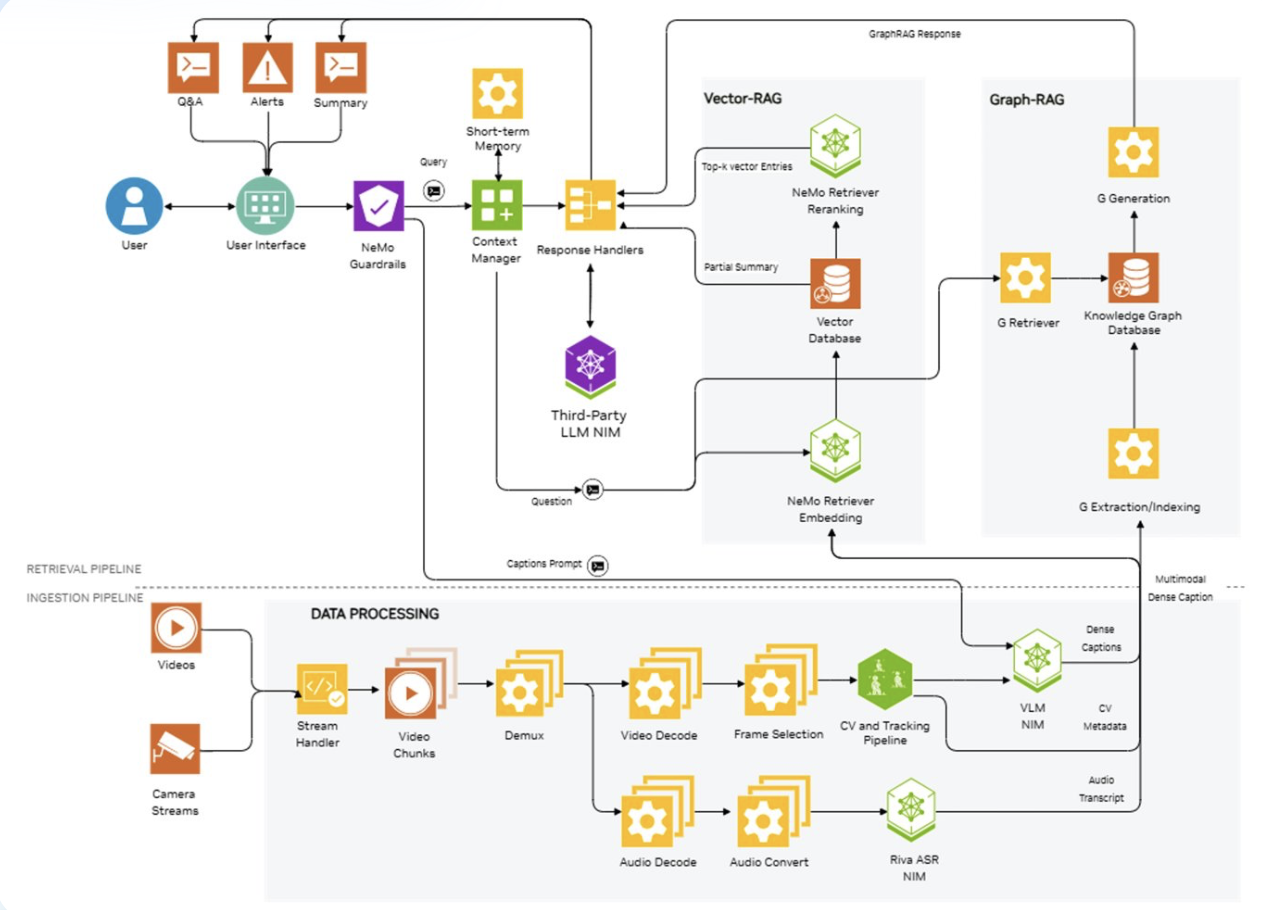
FPT AI Factoryは、GPU、VM、Kubernetesなどのインフラ要素から必要な開発ツールまでフルスタック環境を提供し、AIソリューションの迅速かつ効率的な展開を可能にします。柔軟なアーキテクチャと即利用可能なモデルにより、NVIDIA H100 GPU1台でも性能・拡張性・コスト効率を両立したソリューション構築が可能です。
例えば、FPT AI Inferenceは即利用可能なモデルライブラリを提供しており、開発者はシンプルなAPIコールで統合できます。競争力あるトークン単価で、推論ワークロードを高速化しつつコストも大幅削減し、AIアプリケーションの市場投入を効率化します。
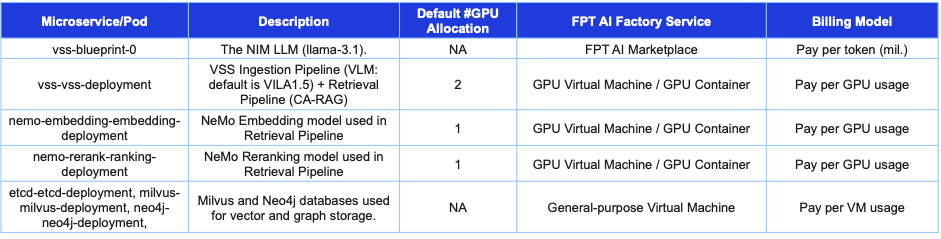
AIモデルファインチューニングの新たな段階へ
GPUコンテナ上でモデルのファインチューニングが可能ですが、これは実験用途に最適です。実運用には、ファインチューニングを自動化できるソリューションが必要です。
FPT AI Studioは、AIノートブック、データ処理などMLOpsの主要コンポーネントを統合。データ、ベースモデル、継続学習など多様なファインチューニング戦略を組み込めます。 GUIは使いやすいドラッグ&ドロップ式。ファインチューニングしたモデルはモデルハブに保存可能。その後FPT AI Inferenceに移行し、本番環境でスケーラブルかつ低遅延で提供できます。
開発者は現在、GPUコンテナ上で直接モデルをファインチューニングでき、実験や迅速な試行にとても便利です。しかし、実験から本番対応のソリューションに移行するには、計算力だけでなく、自動化・再現性・MLOpsパイプラインへの統合が不可欠です。
FPT AI Studioは、ファインチューニングと展開を効率化する最適な環境を提供。ドラッグ&ドロップGUIでワークフローを速やかに構築でき、上級者には高度なカスタマイズも可能。
主なMLOpsコンポーネントは以下の通りです:
- コード駆動型実験用AIノートブック
- 前処理や特徴量エンジニアリングなどのデータ処理パイプライン
- 継続学習、ドメイン適応、転移学習などのファインチューニング戦略
AI Studioでファインチューニングされたモデルはモデルハブに保存され、バージョン管理・共有・再利用が可能。そこからFPT AI Inferenceへシームレスに移行し、スケーラブルかつ低遅延な本番運用ができます。

- 画像: FPT AI Studio の トレーニングパイプライン。
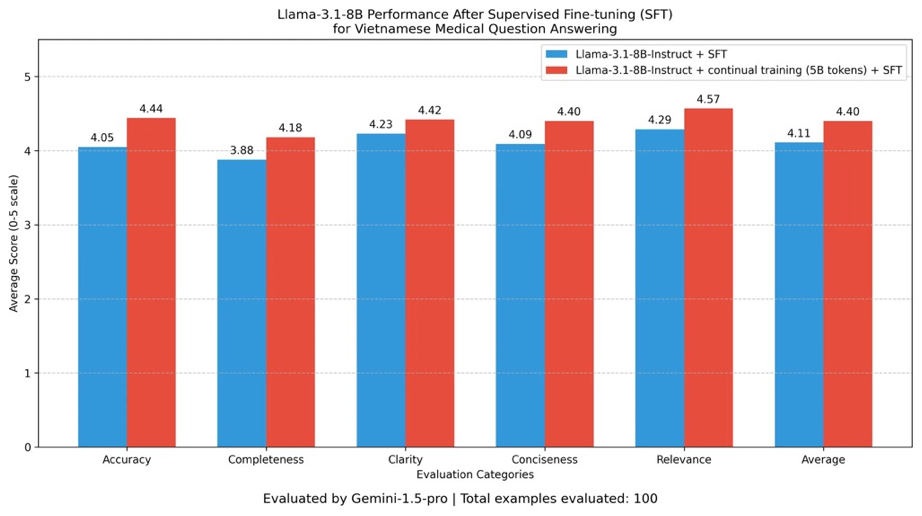
Hung氏は、FPT AI Studioがベトナム医療分野向けLLM適応に活用された事例も紹介しました。ベースモデルはLlama-3.1-8Bで、容量と効率のバランスに優れています。医療Q&A用にドメイン特化適応しつつ、汎用推論能力も保持することが課題です。データセットはベトナム語医療文書で、臨床Q&Aでの事実記憶・ドメイン精度・応答品質向上が目標です。
第1の手法は継続事前学習。24台のNVIDIA H100 GPU(3ノード)で、医療データセットを3エポック学習。全パイプラインは約31時間。
第2の手法はLoRAアダプタによる教師ありファインチューニング。1ノードでNVIDIA H100 GPU4台、5エポック学習。全体で約3時間。計算負荷は小さいが、Q&Aタスクで大きな改善が得られます。

- 画像:医療データセットによる事前学習およびSFT(教師ありファインチューニング)LLMの結果
ベストプラクティス
まず最初に、パフォーマンスとコスト効率を最大限に高めるためには、ワークロードに適したツールを選択することが重要です。FPT AI Factoryでは、あらゆるAI/MLワークロードに対応できる必要なツールが揃っており、より速く・効率的なAIイノベーションを実現できます。初期の実験段階では、GPU ContainerやAI Notebookがアイデアの検証や素早いプロトタイプ作成に適した柔軟な環境を提供します。デプロイメントの際は、ワークロードに応じて最適な選択が重要となります。GPU Containerは軽量な推論に理想的ですが、GPU Virtual Machineはリアルタイムやバッチ推論に必要なパフォーマンスを発揮します。高性能コンピューティング(HPC)が必要な場合は、Metal Cloudが集約型で高いパフォーマンスを提供します。最後に、すぐに使えるモデルを求める企業はAI Marketplaceを利用することができ、追加のファインチューニングなしで事前学習済みLLMや各種サービスの導入を加速できます。

- 画像: さまざまな AI/ML ワークロードに対応する FPT AI Factory のソリューション。

次に、開発者は学習ワークロードの最適化にも注意を払うべきです。大規模な生成AIモデルの学習最適化には、ハードウェアに配慮した技術とワークフロー設計の組み合わせが必要となります。特に有効な手法の一つが混合精度学習であり、FP16やBF16などのフォーマットを活用することで、NVIDIA GPU上で計算を高速化しつつ、メモリ使用量を最大半分まで削減することが可能です。これにより学習時間が短縮されるだけでなく、自動スケーリングによって精度も維持されます。PyTorch DDPやパイプライン並列化などの分散学習も同様に重要で、ワークロードを複数GPUやノードに拡張することでスループットが向上し、開発サイクルの加速につながります。
マルチノード環境では、NVLinkやInfiniBandによるクラスタ間接続の最適化で、学習速度を最大3倍まで向上させ、大規模AIタスクの効率的な同期を実現できます。データパイプラインやストレージもNVIDIA DALIやスケーラブルなI/Oを活用してボトルネックを回避する必要があります。最後に、FPT AI FactoryのGPU性能テストやNVIDIAのMLPerf結果などのベンチマークツールを使って構成を検証することで、ファインチューニングのコスト効率的なスケールアップが可能となります。
さらに、スケーラブルかつ低遅延な生成AIサービスを提供するためには、推論ワークロードの最適化も不可欠です。効果的な手法としては、NVIDIA TensorRTによる量子化と低精度化を適用し、モデルをFP8やINT8に変換することで、精度の犠牲を最小限に抑えつつ最大1.4倍のスループットを実現できます。大規模言語モデルでは、KVキャッシュの効率的な管理も重要です。
PagedAttentionやチャンクプリフィルなどの技術により、メモリ断片化を減らし、複数ユーザー環境で最初のトークン生成時間を2~5倍短縮できます。Speculative decodingでは、小型ドラフトモデルとメインLLMを組み合わせて複数トークンを同時に予測することで、スループットが1.9~3.6倍向上し、特に動画要約などリアルタイム用途で高い効果を発揮します。マルチGPUによる並列化も重要な役割を果たし、分散推論タスクで最大1.5倍の性能向上が可能です。最後に、モデル蒸留やプルーニングによってモデルサイズを縮小し、品質を維持しつつコストや遅延を20~30%削減できます。
主なポイント
- 安全なエンドツーエンドAIワークフローのアーキテクチャ設計方法
本番運用の「AIファクトリー」のアーキテクチャを分解し、ローカルデータセンター内で安全な開発ライフサイクルを設計するための原則に焦点を当てます。データの分離や安全なモデルホスティングの管理、モデルのファインチューニングからエンタープライズグレードのAIエージェント展開までの信頼性あるプロセスについて、具体的な技術的なステップを学ぶことができます。
- GPU加速LLM業務の実践的な技術
スペックの理解を超えて、NVIDIA H100/H200などの高性能GPUを実際に活用する方法を学びます。このセッションでは、学習・推論ワークロード双方の最適化に関する具体的かつ実践的なベストプラクティスを紹介し、スループット最大化、遅延最小化、生成AIアプリケーションの開発サイクル大幅短縮に役立つ内容を解説いたします。
FPT AI Factoryの詳細はこちら:https://fptcloud.com/ja/product/fpt-ai-factory-ja/
ホットライン:0800-300-9739
メール:support@fptcloud.jp


