AI開発を包括的に支える統合プラットフォーム
データハブ

モデルファインチューニング

モデルハブ
ファインチューニング済みモデルを保存・バージョン管理し、チーム内でのスムーズな共有を実現します。

インタラクティブセッション
本番環境への展開前に、GPU環境を即座に立ち上げてモデルをインタラクティブに検証可能。チャット生成や出力品質の評価を通じて、反復開発を加速します。

モデルテスト
業界標準のNLP評価指標を用いてテストデータを自動評価し、本番展開前にモデルのバージョンを客観的に比較できます。


ノーコード
学習データと評価データを用意するだけで、すぐに利用を開始できます。
スケーラブルなAIインフラ
柔軟なGPU構成と標準搭載のマルチモーダル機能により、多様な基盤モデルや大規模データセットに対応します。
セキュア&プライベート
専用コンテナ、専用GPU、暗号化されたデータセットにより、安全に保護されています。
高速ファインチューニング|成果を可視化|スケーラブルで手頃なコスト
SLA
99.90%

GPU運用モデル
各トレーニングジョブに専用GPUを割り当て、
それぞれ独立したトレーニングコンテナ上で実行されます。

パッケージ
1 GPU / トレーニングジョブから

AIの可能性を最大化するファインチューニングの役割
![]()
ドメイン特化
医療、法務、金融などの業界特化データセットでのトレーニングにより、モデルは専門的な知識を習得します。これにより、信頼性の高い、コンプライアンスに沿った応答を実現し、誤情報のリスクを最小化します。
![]()
カスタマーサポートの自動化
過去の顧客対応データを用いてファインチューニングを行うことで、適切なトーンや専門用語、ワークフローに基づいた応対が可能となり、サポート業務の負荷削減、回答精度の向上、そして顧客満足度の向上につながります。
![]()
指示追従能力の強化
詳細な指示、書式ルール、複数ステップにわたる処理を正確に遵守できるよう、モデルの指示追従能力を向上させます。マルチエージェント環境においては、リクエストを適切なエージェントまたはモジュールへ振り分けるようモデルを最適化することが可能です。
![]()
コンプライアンスおよび安全性の確保
組織の基準、各種規制ポリシー、または社内の安全ガイドラインにモデルが確実に従うよう学習させることで、生成結果がリスク管理およびガバナンス要件に確実に適合する状態を維持します。
AIモデルを手軽にファインチューニング
モデルファインチューニングでは、ダッシュボードまたは API を通じて、ファインチューニング済みモデルを容易に作成できます。
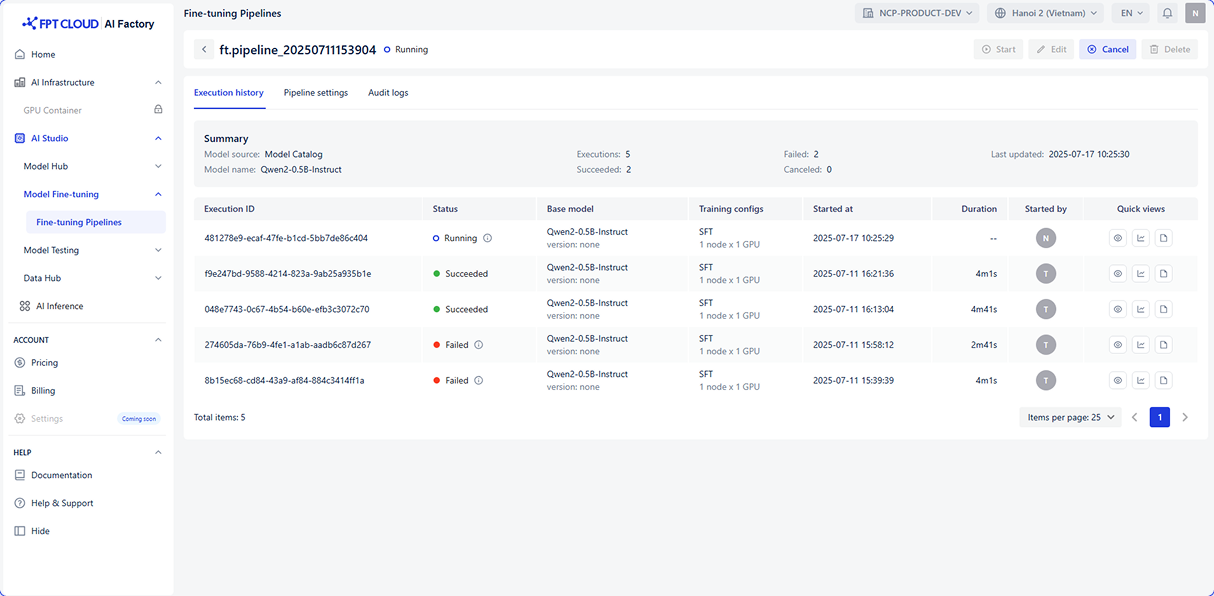
ファインチューニングの全体的な流れは、次のとおりです。
パイプラインの作成
パイプラインの実行
パイプラインの監視
ファインチューニング済みモデルの取得
目的に応じて、教師ありファインチューニング(Supervised Fine-tuning)、直接嗜好最適化(Direct Preference Optimization)、事前学習(Pre-training) のいずれかの手法を用いて、ファインチューニング用パイプラインを作成します。
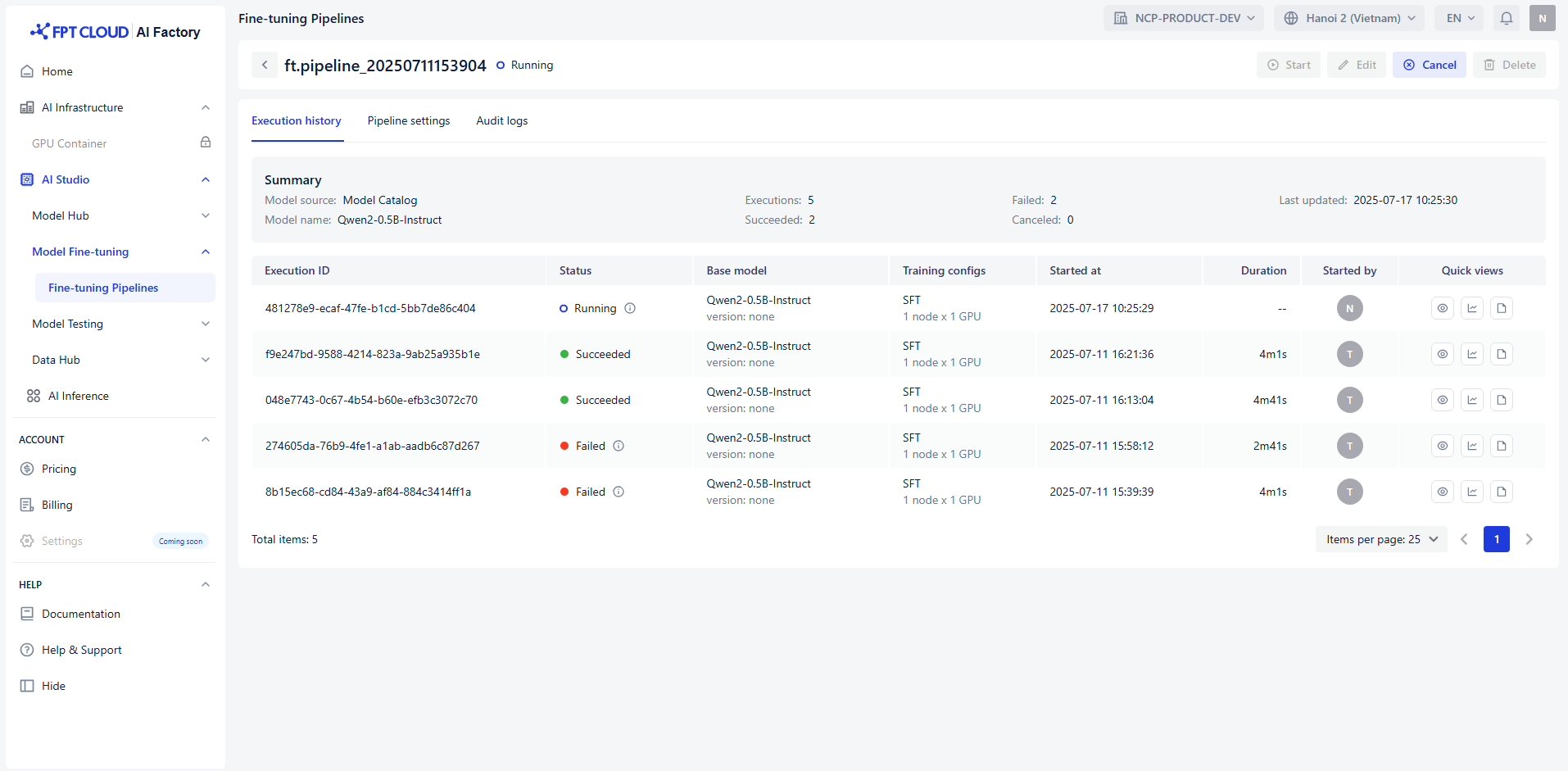
作成が完了したら、「Start」をクリックしてファインチューニングを開始します。
これにより、データ準備からモデル学習まで、各ステップが自動的に実行されます。
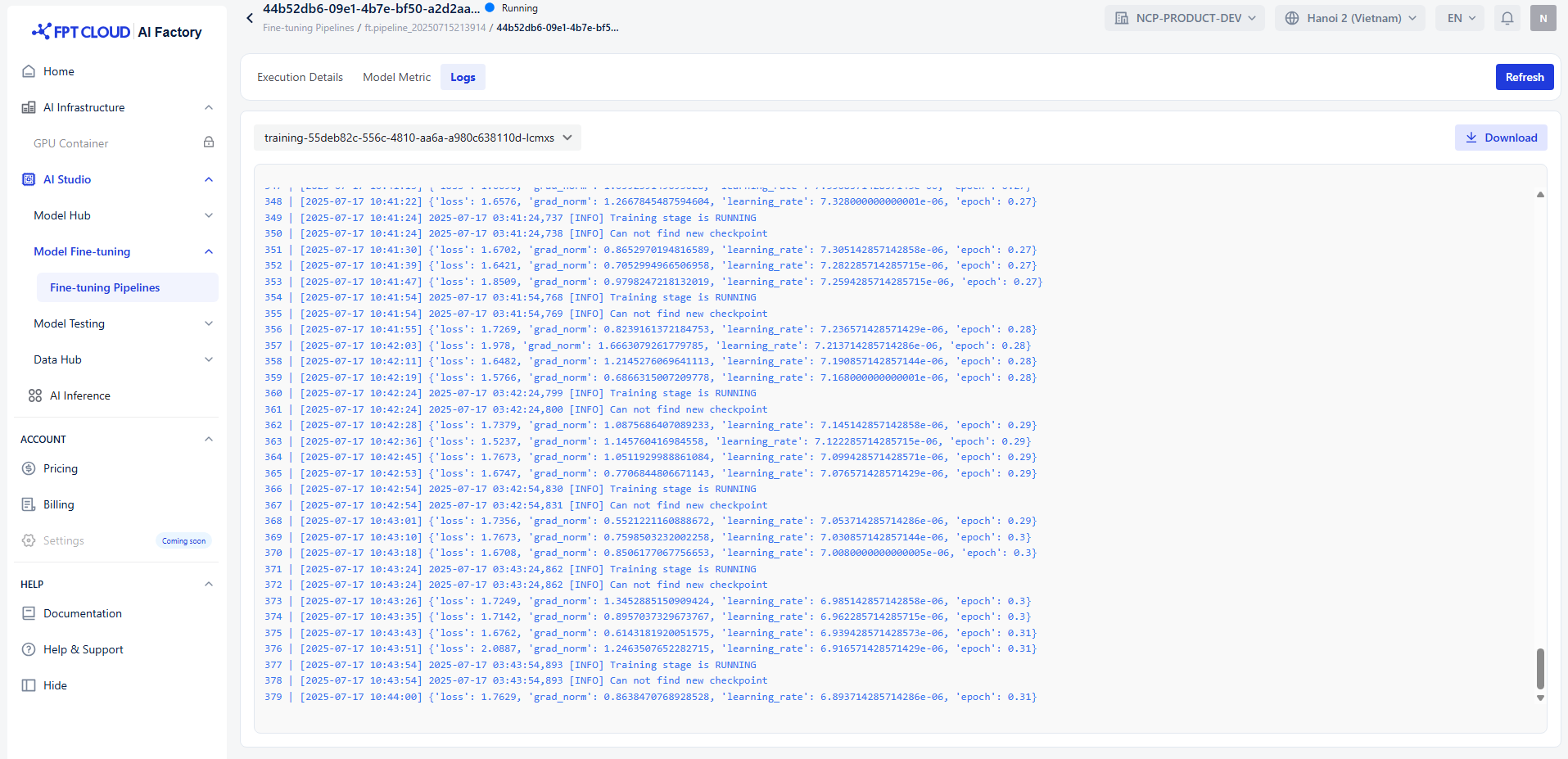
ファインチューニングは、データ準備(train-preparing)、事前学習(pre-training)、学習(training)、後処理(post-training) の 4 つのステージで構成されており、すべての進行状況は “Logs” に記録されます。パイプラインが学習ステージに到達すると、各種メトリクスを用いてモデルおよびシステムの状態を監視し、性能を評価できます。
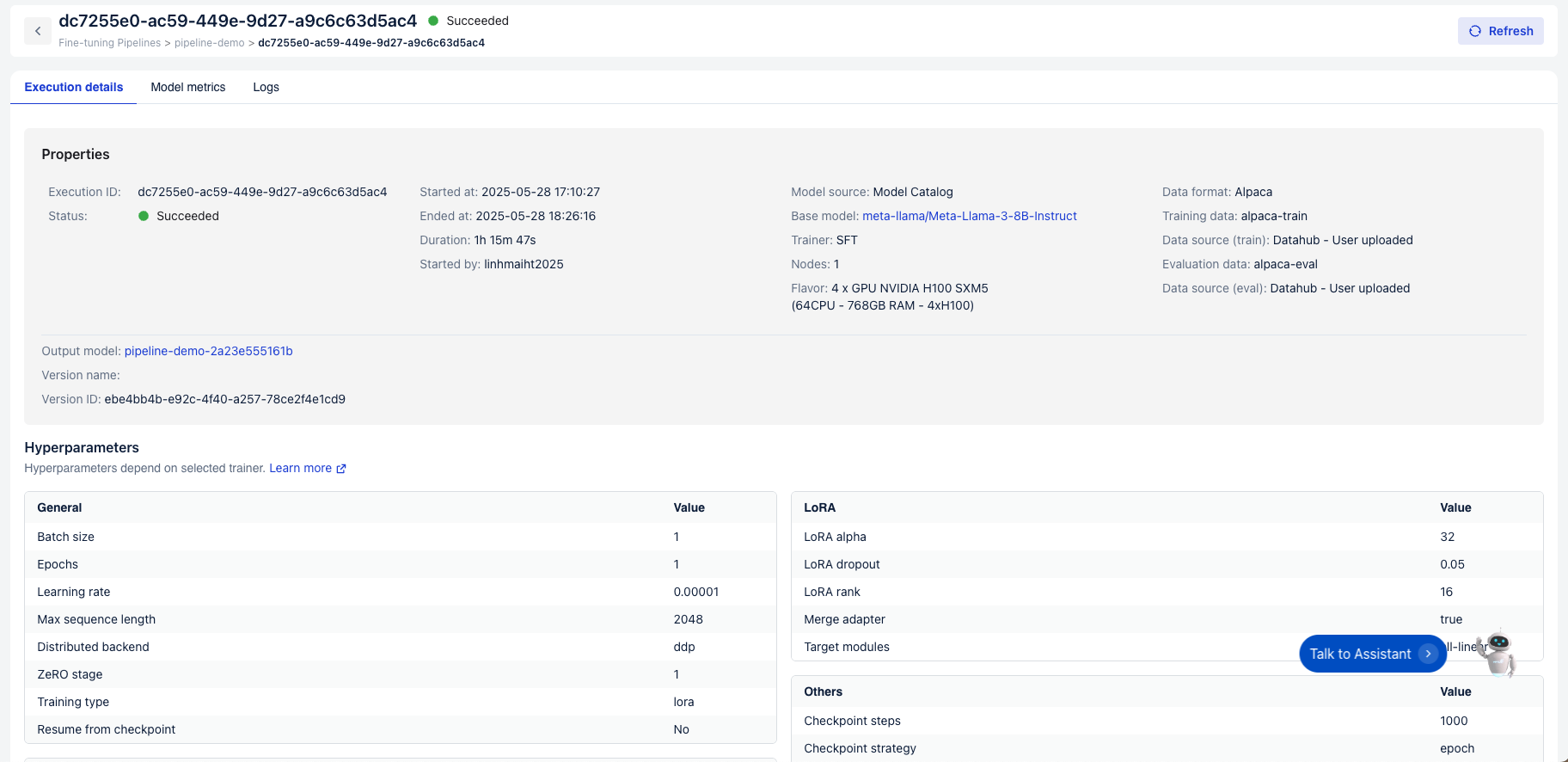
ファインチューニングが完了した後、システムからカスタマイズ済みモデルを取得できます。
このステップでは、モデルのアーティファクトをダウンロードするか、API を通じて直接アクセスし、デプロイ、テスト、さらなる学習に活用することが可能です。ファインチューニング済みモデルを取得することで、最適化されたバージョンをすぐにアプリケーションに統合できる状態に保つことができます。