
What is hyperparameter tuning and why is it essential for building high-performing AI models? Understanding how to optimize hyperparameters helps improve accuracy, efficiency, and scalability in real-world applications. At FPT AI Factory businesses can leverage powerful AI infrastructure and tools to accelerate hyperparameter tuning and model development.
1. What is hyperparameter tuning?
Hyperparameters are configuration settings defined before training that control how a machine learning model learns, while model parameters are internal values such as weights that are updated automatically during training. This distinction is important because hyperparameters shape the learning process, whereas parameters reflect what the model has learned from data.
Hyperparameter tuning is the process of selecting the most suitable set of these configurations to optimize model performance. By testing different values and evaluating results, this process helps improve accuracy, enhance generalization, and ensure the model performs well on new data.
Common examples of hyperparameters include learning rate, batch size, number of layers in a neural network, and regularization strength, each influencing different aspects of training and overall model behavior.
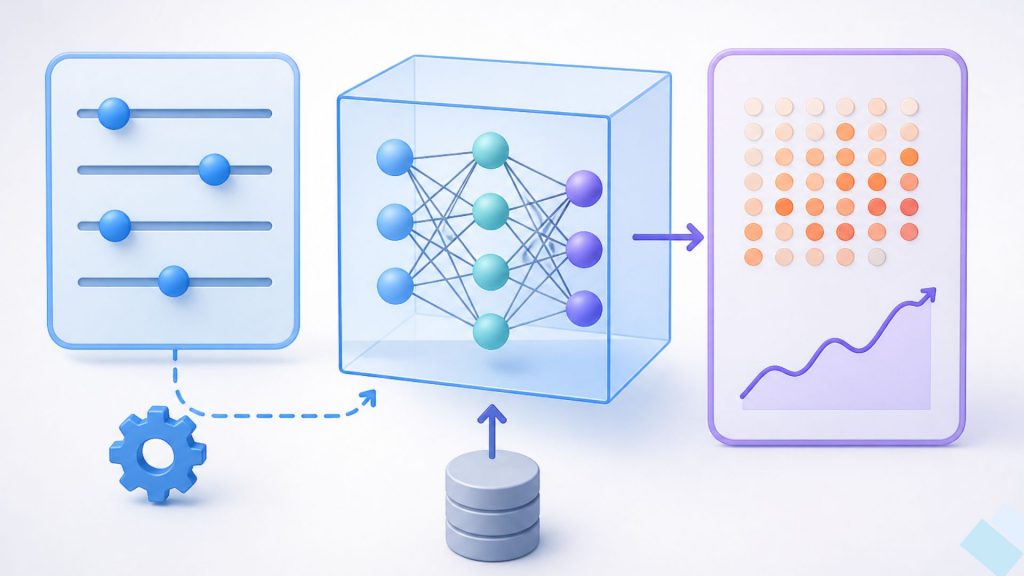
Hyperparameters guide the learning process, while parameters are what the model learns from data
>>> Read more: What is Fine-Tuning? An In-Depth Guide for When to Use
2. Hyperparameters vs model parameters
Hyperparameters and model parameters both influence how a machine learning model performs, but they play different roles in the training process. Hyperparameters control how the model is trained, while model parameters are the values learned from data. The key differences between them are summarized in the table below.
| Aspect | Hyperparameters | Model parameters |
| Definition | External configuration settings that control the training process | Internal values learned from data during training |
| When they are set | Defined before training begins | Determined and updated during training |
| How they are updated | Tuned manually or automatically through optimization methods | Updated automatically using learning algorithms such as gradient descent |
| Examples | Learning rate, batch size, number of layers, regularization | Weights, biases, coefficients |
| Impact on model performance | Influence how efficiently and effectively the model learns | Directly determine the model’s predictions and accuracy |
3. Why hyperparameter tuning matters
Hyperparameter tuning is a critical step in building effective machine learning models because it directly influences how a model learns, performs, and adapts to real-world data. Since hyperparameters often interact in complex and non-linear ways, even small changes can lead to significant differences in model performance across datasets. This makes systematic tuning essential for achieving reliable results.
- Improves model accuracy and generalization on unseen data
- Prevents overfitting and underfitting by balancing bias and variance
- Optimizes training efficiency and reduces computational cost
- Helps models adapt to different datasets and problem types
- Improves training stability and convergence behavior
- Supports better decision-making under computational and performance trade-offs
- Optimizes inference performance by reducing latency during real-time model responses.
- Increases token throughput to support higher request volumes more efficiently.
- Reduces VRAM usage and memory consumption during model deployment.
- Enables scalable model serving across cloud and distributed infrastructure environments.

Hyperparameter tuning improves model performance and generalization
4. Common hyperparameter tuning methods
Hyperparameter tuning can be approached using different strategies depending on model complexity, search space size, and available computational resources. Each method offers a different balance between accuracy, speed, and efficiency when searching for the optimal configuration.
4.1. Grid search
Grid search systematically tests all predefined hyperparameter combinations to identify the best-performing configuration. While simple and reliable, it can become computationally expensive as the search space grows.
Best for:
- Small datasets where computational cost is not a major constraint.
- Scenarios with only a few hyperparameters and limited value ranges.
- Baseline model development requiring exhaustive but simple tuning.
4.2. Random search
Random search samples hyperparameter combinations randomly instead of evaluating every possible option. It often finds strong configurations faster than grid search, especially in large search spaces.
Best for:
- High-dimensional search spaces with many hyperparameters.
- Cases where only a subset of parameters strongly influences performance.
- Early-stage experimentation and model exploration.
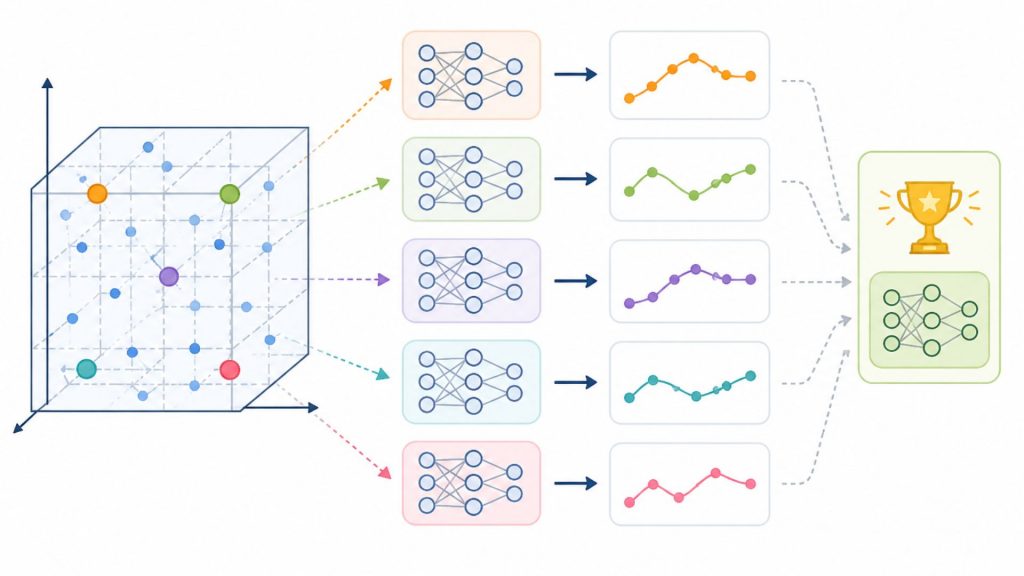
Random search tests hyperparameter combinations randomly to quickly find good model settings
4.3. Bayesian optimization
Bayesian optimization builds a probabilistic model of the objective function and uses past evaluations to predict promising hyperparameter configurations. It iteratively improves the search direction.
Best for:
- Models that are expensive to train.
- Scenarios with limited computational resources.
- Tasks requiring high performance with fewer experiments.
4.4. Hyperband and early stopping
Hyperband evaluates many configurations quickly and eliminates poor-performing ones early using a resource allocation strategy combined with early stopping.
Best for:
- Large-scale deep learning training tasks.
- Environments with limited or expensive computational resources.
- Rapid prototyping and large-scale experimentation.
Hyperband rapidly tests multiple model configurations and stops weak performers early to save computational resources
4.5. Evolutionary algorithms
Evolutionary algorithms optimize hyperparameters by evolving a population of candidate solutions through selection, mutation, and crossover mechanisms.
Best for:
- Highly complex and non-convex optimization problems.
- Large and poorly understood search spaces.
- Research scenarios prioritizing exploration over computational speed.
5. How hyperparameter tuning works
Hyperparameter tuning follows a structured workflow that systematically explores different configurations to identify the best-performing model setup. The process combines experimentation, evaluation, and selection to ensure the model achieves optimal accuracy, efficiency, and generalization on unseen data.
5.1. Define the search space
The first step is to determine which hyperparameters should be tuned and what values they can take. Common examples include learning rate, batch size, number of layers, and regularization strength. Each hyperparameter is assigned a range or a set of possible values, depending on the model and task. Defining a well-structured search space is important because it directly affects both the efficiency and effectiveness of the tuning process.

Define search space for selecting key hyperparameters and their value ranges before tuning
5.2. Choose a tuning method
Once the search space is defined, the next step is selecting a tuning strategy such as grid search, random search, or more advanced methods like Bayesian optimization. Each method explores the search space differently, balancing between exploration and computational cost. The choice of method often depends on available resources, model complexity, and how quickly results are needed.
5.3. Train multiple model versions
In this step, multiple models are trained using different hyperparameter combinations. Each configuration represents a unique experiment, allowing comparison of how different settings influence learning behavior and model performance. To speed up this process, GPU Virtual Machine from FPT AI Factory provides scalable compute data infrastructure that supports running multiple experiments in parallel. This parallelization helps reduce training time and accelerates the search for optimal hyperparameters.

GPU Virtual Machine enables scalable parallel experiments to accelerate model training (Source: FPT AI Factory)
5.4. Evaluate performance metrics
After training, each model version is evaluated using predefined metrics such as accuracy, F1-score, or mean squared error. These evaluations are typically performed on a validation dataset to ensure the model generalizes well to unseen data. Consistent evaluation criteria are essential to fairly compare different configurations and avoid misleading results.
5.5. Select the best configuration
Finally, the hyperparameter combination that delivers the best performance is selected for the final model. This configuration is then used for retraining or deployment in production environments. In many cases, this step may involve additional fine adjustments or repeated iterations to further refine results and ensure optimal performance in real-world scenarios.
6. Hyperparameter Tuning for Modern LLM Systems
Hyperparameter tuning for Large Language Models (LLMs) differs significantly from traditional machine learning because modern LLM systems must optimize not only model quality but also GPU memory usage, inference throughput, training scalability, and deployment latency. Small changes in hyperparameters can strongly affect training stability, hardware utilization, operational cost, and real-time serving performance. As a result, hyperparameter tuning in LLM environments is both a model optimization and systems engineering challenge.
Key objectives of LLM hyperparameter tuning include:
- Improving model quality and response accuracy.
- Reducing GPU memory and VRAM consumption during training and inference.
- Increasing inference throughput to support large-scale serving workloads.
- Improving training scalability across distributed infrastructure.
- Minimizing deployment latency for real-time applications.
- Balancing performance gains against computational and operational costs.
Important Hyperparameters in LLM Tuning
| Hyperparameter |
Role |
| Learning rate | Controls how quickly model weights are updated during training and strongly affects convergence stability and final model quality. |
| Context length | Determines the maximum input sequence size the model can process and directly impacts memory usage and inference cost. |
| LoRA rank | Defines the dimensionality of low-rank adaptation layers and affects both fine-tuning efficiency and model capability. |
| Batch size | Controls the number of training samples processed simultaneously and influences GPU utilization, training stability, and throughput. |
| Gradient checkpointing | Reduces GPU memory usage by recomputing intermediate activations during backpropagation at the cost of additional computation time. |
| Quantization config | Determines how model weights are compressed to lower precision formats in order to reduce VRAM usage and improve inference efficiency. |
| Warm Up steps | Gradually increases the learning rate during early training stages to improve optimization stability. |
| Sequence packing | Combines multiple shorter sequences into a single batch to improve token utilization and training efficiency. |
7. Infrastructure for hyperparameter tuning
Effective hyperparameter tuning requires more than just algorithms; it also depends on a strong supporting infrastructure. A well-designed system ensures experiments run efficiently, results are traceable, and resources are optimally utilized throughout the tuning process.
7.1. Compute resources
Training multiple model variations requires significant computational power, especially in deep learning scenarios. Relying on a single local machine can slow down experimentation and limit scalability. High-performance GPUs and distributed systems such as GPU clusters enable teams to scale training workloads efficiently across multiple nodes. This approach significantly reduces iteration time and allows organizations to handle large-scale tuning tasks more effectively.

High-performance GPUs and distributed systems speed up training by enabling scalable, efficient model experimentation (Source: FPT AI Factory)
7.2. Experiment tracking and logging
As the number of experiments increases, manual tracking quickly becomes inefficient and error-prone. Experiment tracking systems automatically record hyperparameters, training results, and evaluation metrics for each run. This allows teams to compare different configurations more effectively and identify the best-performing setup. It also ensures reproducibility, making it easier to revisit and validate past experiments.
7.3. Parallelization and orchestration
Running experiments sequentially can significantly slow down the tuning process. Parallelization enables multiple training runs to execute at the same time across different GPU computing resources. An orchestration layer helps manage these workloads by distributing tasks efficiently and maintaining system stability. This approach not only speeds up experimentation but also improves overall resource utilization.
7.4. Data management
Reliable results depend on consistent and well-managed data. All tuning experiments should use standardized and properly versioned datasets to ensure fair comparisons. A centralized data management system helps maintain a single source of truth, reducing the risk of inconsistencies. This ensures that any performance improvements are due to better hyperparameters rather than unintended data variations.
7.5. Monitoring and optimization
Real-time monitoring provides visibility into training progress and system performance. It helps detect issues such as stalled training runs or models that fail to converge. Techniques like early stopping can automatically terminate underperforming experiments, saving both time and computational resources. This allows teams to focus on the most promising configurations while optimizing overall efficiency and cost.
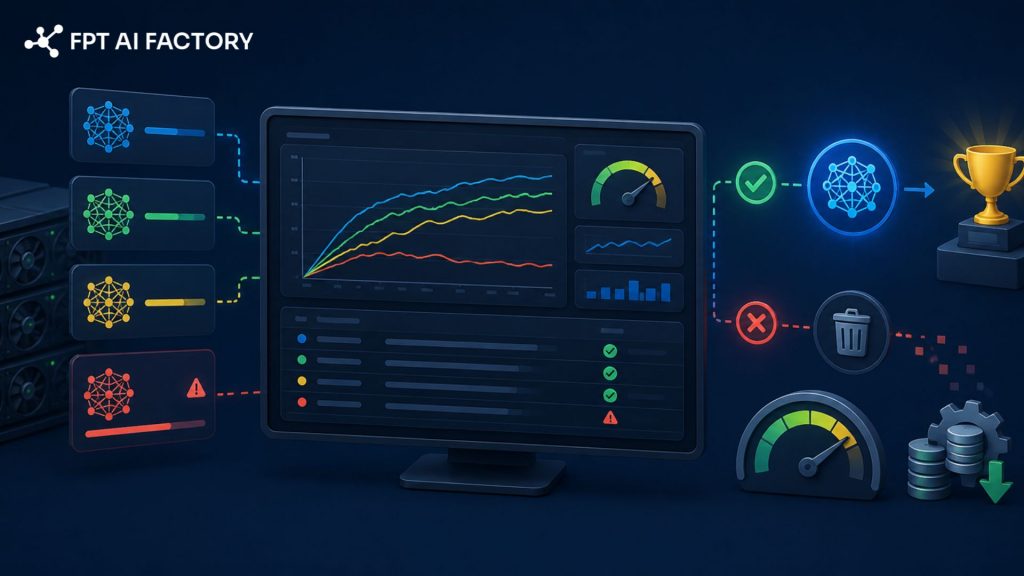
Real-time monitoring optimizes performance and automatically stops underperforming experiments
8. Common use cases of hyperparameter tuning
Hyperparameter tuning is widely used across machine learning applications to improve model accuracy, stability, and efficiency. By adjusting key configuration settings before training, models can better adapt to different datasets and deliver more reliable performance in real-world scenarios.
8.1. Deep learning model optimization
Deep learning models are complex and sensitive to hyperparameter settings. Without proper tuning, they can overfit or fail to learn important patterns. Adjusting values such as learning rate, batch size, and regularization helps improve training stability and overall performance. This ensures models generalize better to new data.
Case Study: Waymo (Alphabet) utilizes Hyperparameter Tuning for autonomous driving neural networks.
- Detail: They implement Population Based Training (PBT) to dynamically adjust learning rates and data augmentation parameters during the training process.
- Result: Research from DeepMind showed that Population Based Training could significantly reduce training costs while improving model performance compared to manual tuning
8.2. Computer vision and NLP tasks
In computer vision and NLP, tuning helps models handle complex data more effectively. It improves tasks like image classification, object detection, and text understanding. By optimizing parameters such as dropout rates or sequence length, models can deliver more accurate and consistent results across different scenarios.
Case Study: Pinterest applies parameter tuning for its visual search engine.
- Detail: By using Bayesian Optimization to find the ideal dropout rates and embedding dimensions, Pinterest ensures high-quality visual matches.
- Result: Optimization efforts led to a 10%+ increase in image matching precision, significantly improving user discovery experiences.
8.3. Recommendation systems
Recommendation systems rely on tuning to deliver relevant and personalized suggestions. Optimizing parameters like learning rate and regularization helps balance between familiar and new content. This directly impacts user engagement, retention, and conversion rates across digital platforms.
Case Study: Netflix optimizes its movie recommendation algorithms.
- Detail: They tune Regularization parameters to strike a balance between suggesting familiar content and introducing new genres, preventing model overfitting.
- Result: Netflix has estimated that its recommendation system contributes over $1 billion annually in value by improving user retention and reducing churn.
Parameter tuning improves recommendation accuracy and user engagement
8.4. LLM fine-tuning and adaptation
For large language models (LLMs), hyperparameter tuning is essential for adapting pre-trained models to specific domains or tasks. Fine-tuning requires careful adjustment of parameters such as learning rate schedules, batch sizes, and adaptation techniques. This helps the model generate more accurate, relevant, and context-aware outputs. When done correctly, tuning allows LLMs to perform effectively in specialized fields while maintaining stability and consistency in their responses.
Case Study: OpenAI’s implementation of GPT-4 fine-tuning for specialized tasks.
- Detail: Using techniques like LoRA (Low-Rank Adaptation), engineers tune specific parameters like rank and alpha to adapt the model to niche domains.
- Result: This optimization reduces training memory requirements by 3-10x while maintaining 99% of the original model’s performance on specialized benchmarks.
Hyperparameter tuning improves LLM performance by optimizing key parameters for better accuracy and stability
9. FAQ
9.1. Is hyperparameter tuning necessary for all models?
Hyperparameter tuning is not required for all models. While it is an important step in improving performance for many machine learning systems, its necessity depends on the type of model, the quality of the data, and the specific goals of the project.
9.2. Which method is best for hyperparameter tuning?
There is no single best method for hyperparameter tuning, as it depends on the problem and resources. Bayesian optimization is often preferred for efficiency, random search works well for large search spaces, while grid search is suitable for small and simple cases where full exploration is possible.
9.3. Can hyperparameter tuning be automated?
Yes, hyperparameter tuning can be fully automated using optimization algorithms and machine learning frameworks that systematically explore different configurations. Instead of manually testing and adjusting parameters, automated methods run experiments, evaluate results, and select the best-performing settings based on defined metrics.
What is hyperparameter tuning is a fundamental concept in machine learning that directly impacts model accuracy, stability, and overall performance. By selecting the right configurations and applying suitable optimization methods, models can train more efficiently and adapt better to real-world data.
Harness the power of hyperparameter tuning to improve AI model performance, efficiency, and scalability. With FPT AI Factory, organizations can accelerate experimentation and optimization using enterprise-grade GPU infrastructure and AI development tools.
To summarize:
- Hyperparameter tuning is the process of optimizing model configuration settings such as learning rate, batch size, and regularization to improve accuracy, generalization, and training efficiency.
- Popular tuning methods, including grid search, random search, Bayesian optimization, Hyperband, and evolutionary algorithms, offer different trade-offs between performance, speed, and computational cost.
- Modern LLM environments require tuning not only for model quality but also for GPU utilization, inference throughput, latency, memory consumption, and deployment scalability.
- Successful hyperparameter tuning depends on robust infrastructure, including high-performance GPUs, experiment tracking, orchestration, data management, and real-time monitoring.
- FPT AI Factory provides scalable GPU Virtual Machines, AI notebooks, and AI infrastructure services that help teams run large-scale tuning experiments and accelerate AI model development.
To get started, FPT AI Factory offers a $100 free credit for new users, giving immediate access to GPU containers, GPU virtual machines, AI notebooks, and Serverless Inference services. This allows you to run hyperparameter tuning workflows without any upfront infrastructure investment. The credit is available right after registration and can be used immediately upon login, so you can begin experimenting right away.
For organizations with advanced needs, such as customized solutions or large-scale deployments, we recommend reaching out through the contact form. Our team will provide tailored consultation and support to help you design and scale AI systems that fit your specific requirements.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more articles:
Transfer Learning vs. Fine-Tuning: Key Differences Explained
Prompt Engineering vs Fine-tuning: A Guide to better LLM


