
As large language models (LLMs) become a core part of modern AI applications, businesses need practical ways to improve accuracy, consistency, and output quality. Two common approaches are prompt engineering vs fine-tuning. Prompt engineering improves results by changing how instructions are written, while fine-tuning adapts the model itself using task-specific or domain-specific data. In this guide, FPT AI Factory explains the key differences between prompt engineering vs fine-tuning, when to use each method, when to combine them, and how businesses can choose the right optimization strategy for LLM applications.
1. What is Prompt Engineering?
Prompt Engineering is the process of designing and refining how you “ask questions” or provide instructions to a large language model (LLM) in order to get the most accurate and relevant responses. Instead of modifying the model itself, you adjust how prompts are written, for example: by adding context, specifying roles, defining output formats, or providing examples to guide the model toward the intended result.
In simple terms, Prompt Engineering is like communicating effectively with AI: the clearer, more specific, and more structured your input is, the better the output will be. This approach is especially useful when you want to quickly improve response quality without the cost or time required for retraining the model.

Prompt Engineering is like communicating effectively with AI
2. What is Fine-Tuning?
Fine-tuning is the process of “retraining” an AI model using your own data so it can provide more accurate and relevant responses for specific needs. Instead of relying only on general knowledge, a fine-tuned model becomes familiar with the writing style, terminology, and scenarios within your domain.
For example, if you have a customer support chatbot, you can fine-tune it using real company Q&A data. As a result, the AI can respond with the correct brand tone and more precise information, rather than giving generic answers like the original model.

Fine-tuning is the process of “retraining” an AI model using your own data
3. Differences between Prompt Engineering vs Fine-tuning
Prompt engineering and fine-tuning both aim to improve LLM performance, but they solve different problems. Prompt engineering changes the input given to the model, while fine-tuning changes how the model behaves after additional training. In practical terms, prompt engineering is faster and easier to test, while fine-tuning is more suitable when a business needs stable, repeatable, and domain-specific outputs at scale.
| Criteria | Prompt Engineering | Fine-tuning |
| Optimization Approach | Optimizes by adjusting prompts (how you ask questions or give instructions) | Optimizes by retraining the model with custom data |
| Performance | Suitable for general tasks, delivers quick results | Higher performance for specialized tasks |
| Knowledge Integration | Does not add new knowledge, leverages existing model knowledge | Can incorporate new knowledge from custom datasets |
| Consistency | May vary between runs | More stable and consistent |
| Technical Complexity | Low, easy to implement | High, requires ML/AI expertise |
| Resource Requirements | Minimal resources, no training needed | Requires data, compute, and training time |
| Flexibility in Customization | Highly flexible and easy to adjust | Deep customization but slower to update |
| Time to Deploy | Fast, can be used immediately | Slower due to training and testing |
| Best Use Cases | Basic chatbots, content generation, general Q&A | Domain-specific tasks (healthcare, finance, enterprise data) |
| Cost | Low | Higher due to training and operational costs |
4. When to use Prompt Engineering and Fine-tuning?
Choosing between Prompt Engineering and Fine-tuning depends on your goals, the complexity of the task, and available resources. Each approach is suited to different scenarios, and in many real-world cases, combining both can deliver the best results.
4.1. Using Prompt Engineering only
Prompt Engineering is a suitable choice in the following cases:
- When you need to deploy quickly without investing time in model training
- When you do not have, or lack, high-quality proprietary data
- For general tasks such as content writing, basic chatbots, translation, or summarization
- When flexibility is needed to adjust responses based on different contexts
This approach improves output by optimizing prompt design without modifying the model itself, making it cost-effective and easy to experiment with.
4.2. Using Fine-tuning only
Fine-tuning is suitable for cases that require high accuracy and consistency:
- When proprietary or domain-specific data is available
- When the model needs deep understanding of a specific field such as finance, healthcare, or legal
- When outputs must follow a fixed format or tone
- When consistent and stable responses are required
Businesses can consider the FPT Model Fine-Tuning service to quickly deploy without building complex infrastructure. This solution is designed to be flexible, scalable, and easy to get started, whether you need full control or a streamlined workflow. Businesses can choose between two powerful options:
- Rent GPU resources, such as GPU Container or GPU Virtual Machine, from FPT AI Factory to unlock high-performance computing for large-scale fine-tuning, giving you full control over model optimization while ensuring cost efficiency.
- Use FPT AI Factory’s AI Notebook for a seamless, all-in-one environment where you can develop, train, and fine-tune models faster, without complex setup or infrastructure management.
With these options, businesses can accelerate AI deployment, reduce operational overhead, and bring customized AI models into production more efficiently than ever.
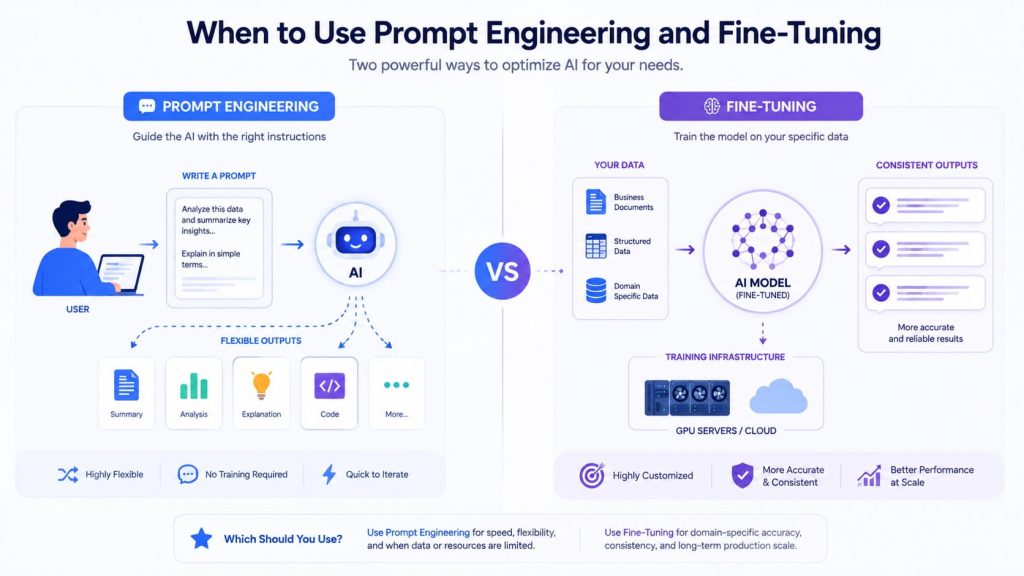
Prompt Engineering improves AI outputs through better instructions, while Fine-Tuning adapts the model using domain-specific data for more consistent performance
4.3. Combine Prompt Engineering and Fine-tuning
In practice, many modern AI systems combine both approaches:
- Fine-tuning builds the model’s foundational knowledge and behavior
- Prompt Engineering adjusts outputs flexibly for specific situations
This combined approach ensures high accuracy while maintaining flexibility, ultimately optimizing the overall performance of AI systems.
5. FAQs
5.1. Is Fine-Tuning the same as Prompt Engineering?
No. Prompt Engineering focuses on optimizing how prompts are written to guide model outputs, while Fine-tuning involves retraining the model with custom data. They differ in both approach and the level of intervention applied to the model.
5.2. Can Prompt Engineering replace Fine-Tuning?
Not entirely. Prompt Engineering works well for simple or general tasks and can be implemented quickly. However, for more complex requirements that demand high accuracy and domain expertise, fine-tuning is still necessary.
5.3. Is Prompt Engineering expensive?
No. Prompt Engineering does not require training resources, making it significantly more cost-effective than Fine-tuning. Most of the cost comes from time spent experimenting and optimizing prompts.
Prompt Engineering and Fine-tuning are two core approaches to unlocking the full potential of large language models (LLMs). While Prompt Engineering enables quick optimization and flexible interaction at low cost, Fine-tuning provides deeper customization, higher accuracy, and better consistency for specialized tasks. In practice, combining both methods often delivers the best results, creating AI systems that are both powerful and adaptable.
To get started easily, you can take advantage of the Starter Plan Free $100 from FPT AI Factory, which offers $100 in credits for new users immediately when you register. This plan provides sufficient resources to experiment with both Prompt Engineering and Fine-tuning across models like Llama-3.3, allowing you to build, test, and optimize AI solutions without significant upfront investment.
For businesses with more advanced needs, such as customized solutions or large-scale deployments, we recommend reaching out via our contact form. Our team will provide tailored consultation and support to match your specific requirements.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore related article:
What Is Supervised Fine-Tuning? Process, Use Cases, Benefits
What is LoRA? A Complete Beginner’s Guide on How It Works
What is JupyterHub? Characteristic and practical application
What Is Feature Engineering? Techniques, Benefits & Examples


