
1. GPUコンテナの紹介
GPUコンテナの概要
GPUコンテナは、機械学習やデータサイエンスワークフローを加速するために設計された、事前構成済みのエンタープライズ向けソリューションです。GPUコンテナを利用することで、Jupyter Notebookとシームレスに統合されたGPU対応コンテナを展開でき、機械学習モデルの開発やトレーニングに最適な堅牢な環境を提供します。NVIDIA GPUとコンテナ技術を活用することで、高い柔軟性とスケーラビリティを持つ高性能なコンピューティングを実現します。
GPUコンテナプラットフォームの主な利点
- 高性能コンピューティング:1~8台のNVIDIA GPUを利用して、複雑なモデルの学習時間を大幅に短縮可能。
- 環境の一貫性:事前構成済みコンテナにより、さまざまなプロジェクトで再現性のあるセットアップを保証し、構成の衝突を排除。
- インタラクティブなワークフロー:Jupyter Notebookによる洗練されたコーディング・可視化・ドキュメンテーション環境。
- リソース最適化:GPUリソースを正確に割り当て、スケーラブルな利用におけるコスト効率を向上。
- 多様なフレームワーク対応:組み込みイメージやカスタムイメージを利用可能。
このガイドでは、GPUコンテナの概要と、Jupyter Notebookを用いて機械学習モデルを開発するためのセットアップ・利用方法を順を追って解説します。
2. GPUコンテナの起動
前提条件:
AI Factoryアカウントを持ち、アカウント残高が最低$5以上あること(1~2時間のGPUコンテナ実験を中断なく行うため)
GPUコンテナは現在FPT AI Factoryで利用可能です。以下の手順に従い、FPT AI FactoryでGPUコンテナを起動してください。
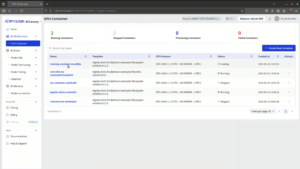
ai.fptcloud.com にアクセスし、GPUコンテナダッシュボードに切り替えると、稼働中・一時停止中・停止中のコンテナが一目で確認できます。
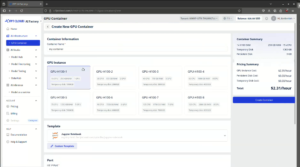
ステップ 1: GPUフレーバーの選択
GPUコンテナ機能では、計算ニーズに応じて1~8台のH100 NVIDIA GPUから選択できます。軽量なタスクには1GPU、大規模モデルのトレーニングには8GPUを選ぶなど、用途に合わせて構成可能です。
AI Factoryのインターフェースで「Create New Container」セクションに進み、パネルから希望するGPU構成(1~8GPU)を選択します。
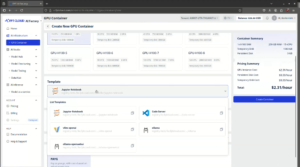
ステップ 2: コンテナイメージの選択
プラットフォームには機械学習用に最適化された複数の組み込みイメージが用意されており、カスタムイメージも利用できます。組み込みイメージを選択する場合は「Template」パネルで選びます。
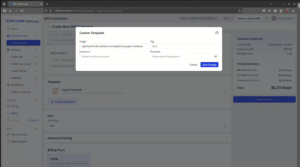
特定のライブラリや構成が必要な場合は、「Custom Template」ボタンをクリックし、カスタムイメージのURLを入力してください。
ステップ 3: 環境変数と起動コマンドの設定
必要に応じて環境変数や起動コマンドを設定し、コンテナの挙動をカスタマイズできます。
- 環境変数:Jupyter用のUSERNAMEやPASSWORD、またはフレームワーク固有の設定などを指定
- 起動コマンド:必要に応じてデフォルトコマンドを上書き可能(例:jupyter notebook –ip=0.0.0.0 –port=8888)
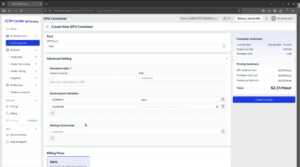
本ガイドでは、組み込みJupyter Notebookイメージのデフォルト設定(自動的にJupyter Notebookが起動)を使用します。
ステップ4:コンテナの起動と待機
GPUコンテナインスタンスの設定や料金が要件を満たしていることを確認し、「Create Container」を選択してコンテナを起動します。
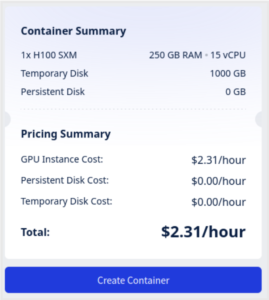
コンテナの準備が整うまで待機します。プラットフォームがコンテナをプロビジョニングし、選択したGPUを割り当て、Jupyter Notebookサーバーを起動します。GPUコンテナダッシュボードでステータスを確認できます。
また、ダッシュボード上でコンテナ名をクリックすると、セットアップの詳細情報を確認できます。
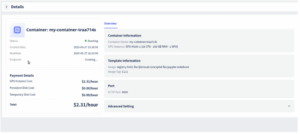 準備ができると、プラットフォームからJupyterインターフェースへのダイレクトリンクが提供されます。
準備ができると、プラットフォームからJupyterインターフェースへのダイレクトリンクが提供されます。
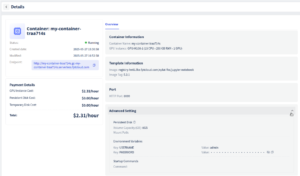
そのエンドポイントをクリックしてJupyter Notebookにアクセスしてください。
3. GPUコンテナでJupyter Notebookを用いてYOLOv11の学習
このセクションでは、既存のJupyter NotebookをGPUコンテナにアップロードし、脳腫瘍検出用YOLOv11モデルの学習を実演します。
GPUコンテナの機械学習/深層学習能力を示すためのノートブックを用意しています。現行のセットアップをご確認ください。
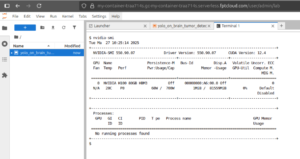
現在、コンテナ内には1枚のH100 NVIDIA GPUが割り当てられています。
 Jupyter Notebookインターフェースにアクセス可能で、操作の準備ができています。まずモデル学習に必要なパッケージをインストールします。
Jupyter Notebookインターフェースにアクセス可能で、操作の準備ができています。まずモデル学習に必要なパッケージをインストールします。
パッケージのインストールが完了したら、学習プロセスを開始してください。
以下のコードスニペットを実行してモデル学習を開始します。
from ultralytics import YOLO
# Load a model
model = YOLO("yolo11m.pt") # load a pretrained model (recommended for training)
# Train the model
results = model.train(data="brain-tumor.yaml", epochs=10, imgsz=640, workers=0)
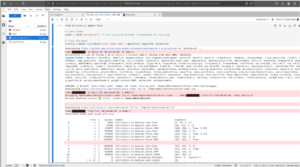
指定されたパラメータでモデルの学習が進行中です。
学習完了後、サンプル入力で推論を実行し、モデル性能を検証します。
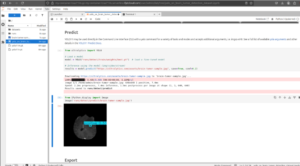
モデルはエラーなく学習を完了しました。学習済みモデルをデプロイや今後の推論タスクのためにエクスポートします。
以下のコマンドでモデルをONNX形式でエクスポートできます。
from ultralytics import YOLO
# Load a model
model = YOLO("runs/detect/train/weights/best.pt") # load a custom trained model
# Export the model
model.export(format="onnx")

モデルのエクスポート後は、ローカル環境にダウンロードしてさらなる活用が可能です。
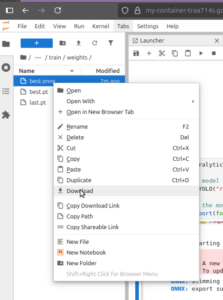
4. まとめ
ワークフローのサマリー
このガイドでは以下を実演しました。
- FPT AI FactoryでGPU構成の選択、イメージ選択、環境変数設定によるGPUコンテナの起動
- Jupyter Notebookのコンテナへのアップロードと機械学習モデルの実行
- モデルやノートブックの永続化による継続利用
GPUコンテナは、GPUアクセラレーションとコンテナ化、Jupyter Notebookの柔軟性を組み合わせた、エンタープライズ用途に最適な高性能・スケーラブルな機械学習ソリューションです。
おすすめの次のステップ
GPUコンテナを最大限に活用するために:
- Visual Studio Codeとの連携:Remote – Containers拡張機能で統合開発環境を実現
- vLLMでLLMを提供:vLLM(大規模言語モデルの高性能推論ライブラリ)統合でワークフローを強化
- 高度なフレームワークの活用:PyTorchやカスタムイメージ対応で複雑なML課題にも対応
- モデルのデプロイ:学習・評価後、Model Hubサービスを使い本番環境でモデルを提供
GPUコンテナ機能を活用し、エンタープライズ環境下で機械学習ワークフローを加速しましょう。
FPT AI Factoryの詳細はこちら:https://fptcloud.com/ja/product/fpt-ai-factory-ja/
ホットライン:0800-300-9739
メール:support@fptcloud.jp


