
人工知能の進化が目覚ましい現代において、大規模言語モデル(LLM)は医療からクリエイティブライティングまで産業を大きく変えています。しかし、こうしたモデルをゼロから訓練するには膨大なリソースが必要となり、多くの場合非現実的です。そこで登場するのが「パラメータ効率的ファインチューニング(PEFT)」です。これは、すでに事前学習済みのモデルを自分の用途に合わせて効率よく調整し、時間・計算資源・地球環境まで節約できる手法です。計算負荷を減らすことで、PEFTはノートパソコンやエッジデバイスなど幅広いハードウェアでAIを利用可能にし、エネルギー使用量やCO2排出削減など持続可能な技術への社会的要請にも応えます。準備はできましたか?早速始めましょう!
前提条件
ファインチューニングを始める前に、必要なツールや環境を確認しましょう。
【ハードウェア】
- PEFTタスクに十分対応するため、最低でもNVIDIA A100 80GB GPUが1枚必要です(Llama 3.1–8Bのようなモデルでは特にメモリ・計算力が重要です)。
【ソフトウェア】
- NVIDIA NeMo:バージョン24.07以降をインストールしてください。Docker経由で利用しますので、Dockerの基本操作も理解しておきましょう。
- Python 3.8以上:NeMoやその依存パッケージ(PyTorchやHugging Face Transformersなど)が必要とします。
- Hugging Face CLIまたはAPI:Llama 3.1–8Bのダウンロードに必要です(有効なトークンも取得してください)。
- Weights & Biases(WandB):任意ですが、学習進捗の可視化に推奨されます。無料アカウント登録とAPIキー取得を行ってください。
- NVIDIAドライバーとCUDA Toolkit:A100/H100にはバージョン535以上、CUDA 12.1以上が必要です。
【アクセスと権限】
- Hugging Face上でLlama 3.1–8Bモデルへのアクセス申請を行い、Metaから承認を得てください。
これらの準備ができれば、A100でもH100でも問題なく進められます。それでは手順に進みましょう!
PEFTとは?その重要性と意味
手順解説の前に、パラメータ効率的ファインチューニング(PEFT)とは何かを簡単に説明します。Llama 3.1–8Bのような巨大な事前学習済みモデル(80億パラメータ)を思い浮かべてください。これらは膨大な知識を持っていますが、日本語の創作や技術質問回答など特定用途で活躍してほしい場合、全パラメータを再学習するのは非効率です。
PEFTは、モデル全体ではなくごく一部のパラメータだけを微調整します(わずか0.1%程度も可能)。これにより大幅な計算・メモリ節約が可能で、1枚のGPUや場合によってはノートパソコンでもファインチューニングできます。結果として学習は高速・省メモリ、環境負荷も小さくなります。
代表的なPEFT手法とパラメータ
PEFTにはさまざまな手法とパラメータがあります:
- LoRA(Low-Rank Adaptation):特定層(例:attention_qkv)に小さな学習可能なアダプタ行列を追加します。
- Rank(r):アダプタ行列のサイズ。小さければ効率的、大きければ表現力が高まります(例:8や16)。
- Target Modules:どの層にアダプタを入れるか(多いほど柔軟ですが計算量も増えます)。
- P-Tuning:重みではなく、モデルへの“プロンプト”埋め込みを学習します。
- Prompt Length:調整用トークンの長さ(例:20)。長いほど文脈把握力が増しますが複雑化します。
- Adapter Tuning:モデル内に軽量なニューラル層を追加します。
- Adapter Size:層内ニューロン数(例:64)。小さいほど軽量です。
本ガイドではバランスの良いLoRAを採用しますが、NeMoは他手法もサポートしていますので好みに応じてどうぞ。
ハードウェア要件
PEFTタスクにはA100 80GB GPUが推奨されます。その理由は、巨大なテンソル演算やNeMoの並列処理にA100のメモリ・計算力が最適だからです。予算が限られる場合はRTX 3090(24GB)などでも小規模モデルなら可能ですが、学習時間やメモリ制約に注意してください。
ステップ1:Llama 3.1–8Bモデルのダウンロード
まずはHugging Face形式のLlama 3.1–8Bモデル(Meta AI製、80億パラメータ)を取得します。事前にMetaのHugging Faceページで利用申請・規約同意を済ませてください。承認後、モデル格納用ディレクトリを作成します。
mkdir llama31-8b-hf
ダウンロード方法は2つあります。
オプション 1: CLIツール
Hugging Faceにログインし、提供されているCLIを使用します。
huggingface-cli login huggingface-cli download meta-llama/Llama-3.1-8B --local-dir llama31-8b-hf
オプション 2: Python API
Python APIによる方法 スクリプト派の方はPythonスニペットを利用(<YOUR HF TOKEN>を自身のトークンに置き換えてください)。
from huggingface_hub import snapshot_download
snapshot_download( &nbsp;&nbsp; repo_id="meta-llama/Llama-3.1-8B", &nbsp;&nbsp; local_dir="llama31-8b-hf", &nbsp;&nbsp; local_dir_use_symlinks=False, &nbsp;&nbsp; token="&lt;YOUR HF TOKEN&gt;" )
ダウンロードが完了したら、pytorch_model.binやmodel.safetensorsなど主要ファイルが揃っているか確認しましょう。
ステップ2:NeMo形式への変換
NeMoは独自の.nemo形式を使います。これにより分散チェックポイントや柔軟な並列処理が可能になります。
NeMoコンテナの起動
NVIDIAのNeMo DockerコンテナをGPU対応で起動します。
docker run --gpus device=1 --shm-size=2g --net=host --ulimit memlock=-1 --rm -it -v ${PWD}:/workspace -v ${PWD}/results:/results nvcr.io/nvidia/nemo:24.07 bash
このコマンドで現在のディレクトリを/workspaceとしてマウントし、GPUアクセスを有効にします。
変換の実行
コンテナ内で変換コマンドを実行します。
python3 /opt/NeMo/scripts/checkpoint_converters/convert_llama_hf_to_nemo.py --input_name_or_path=./llama31-8b-hf/ --output_path=llama31-8b.nemo
変換後のllama31-8b.nemoファイルは、あらゆるテンソル並列・パイプライン並列構成でそのまま利用でき、後からの拡張も容易です。
データの準備
ファインチューニングの成否はデータにかかっています。本ガイドでは、日本語に翻訳されたDatabricks Dolly 15kデータセットを例に使いますが、医療QAやカスタマーサポートなど、用途に合うデータセットで置き換えても構いません。
ステップ 1: データセットのダウンロード
データセットのダウンロード Hugging Faceからデータセットを取得します。
# load_dataset.py
from datasets import load_dataset
# Load dataset
ds = load_dataset("llm-jp/databricks-dolly-15k-ja")
df = ds["train"].data.to_pandas()
df.to_json("databricks-dolly-15k-ja.jsonl", orient="records", lines=True)
データの前処理 NeMoが扱える形式に整形します。instructionとcontextをinputに統合し、responseをoutputとしてペアにするスクリプト例を用意してください。
ステップ 2: データの画処理
データを、NeMoが読み込める形式に整形する必要があります。以下は、命令 (instruction) とコンテキスト (context) を結合して入力フィールドを作成し、それを出力レスポンス (output response) とペアにするための前処理スクリプトです。
# preprocess.py
import json
import argparse
import numpy as np
def to_jsonl(path_to_data):
print("Preprocessing data to jsonl format...")
output_path = f"{path_to_data.split('.')[0]}-output.jsonl"
with open(path_to_data, "r") as f, open(output_path, "w") as g:
for line in f:
line = json.loads(line)
context = line["context"].strip()
instruction = line["instruction"].strip()
if context:
# Randomize order of context and instruction for variety
context_first = np.random.randint(0, 2) == 0
input_text = f"{context}\\\\n\\\\n{instruction}" if context_first else f"{instruction}\\\\n\\\\n{context}"
else:
input_text = instruction
output = line["response"]
g.write(
json.dumps(
{"input": input_text, "output": output, "category": line["category"]},
ensure_ascii=False
) + "\\\\n"
)
print(f"Data saved to {output_path}")
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument("--input", type=str, required=True, help="Path to jsonl dataset")
return parser.parse_args()
if __name__ == "__main__":
args = get_args()
to_jsonl(args.input)
次のように実行してください:
python preprocess.py --input=databricks-dolly-15k-ja.jsonl
ステップ 3: データセットの分割
次に、前処理済みのデータを学習用(training)、検証用(validation)、テスト用(test)のセットに分割します。
# split_train_val.py import json import random input_file = "databricks-dolly-15k-ja-output.jsonl" train_file = "training.jsonl" val_file = "validation.jsonl" test_file = "test.jsonl" train_prop, val_prop, test_prop = 0.80, 0.15, 0.05 with open(input_file, "r") as f: lines = f.readlines() random.shuffle(lines) total = len(lines) train_idx = int(total * train_prop) val_idx = int(total * val_prop) train_data = lines[:train_idx] val_data = lines[train_idx:train_idx + val_idx] test_data = lines[train_idx + val_idx:] for data, filename in [(train_data, train_file), (val_data, val_file), (test_data, test_file)]: with open(filename, "w") as f: for line in data: f.write(line.strip() + "\\\\n")
データセットの分割 前処理済みデータを訓練・検証・テスト(8:1.5:0.5の比率)に分割します。
{
"input": "若い頃にもっと時間をかけてやっておけばよかったと思うことは?",
"output": "健康とウェルネスへの投資だ。若い頃に運動やバランスの取れた食事、家族との時間をもっと大切にしていれば、今後の人生がもっと豊かで楽になっていただろう。",
"category": "creative_writing"
}
ステップ3:PEFTによるファインチューニング
いよいよファインチューニングです。LoRA方式(PEFT_SCHEME=”lora”)を使いますが、変数を変えればP-Tuningなども可能です。以下が全体のスクリプトです。
MODEL="llama31-8b.nemo"
TRAIN_DS="[training.jsonl]"
VALID_DS="[validation.jsonl]"
TEST_DS="[test.jsonl]"
TEST_NAMES="[data]"
PEFT_SCHEME="lora"
CONCAT_SAMPLING_PROBS="[1.0]"
TP_SIZE=1
PP_SIZE=1
huggingface-cli login --token <HF_TOKEN>
export WANDB_API_KEY=<WANDB_TOKEN>
wandb login
torchrun --nproc_per_node=1 \\\\
/opt/NeMo/examples/nlp/language_modeling/tuning/megatron_gpt_finetuning.py \\\\
trainer.devices=1 \\\\
trainer.num_nodes=1 \\\\
trainer.precision=bf16 \\\\
trainer.val_check_interval=20 \\\\
trainer.max_steps=50 \\\\
model.megatron_amp_O2=True \\\\
++model.mcore_gpt=True \\\\
++model.flash_attention=True \\\\
model.tensor_model_parallel_size=${TP_SIZE} \\\\
model.pipeline_model_parallel_size=${PP_SIZE} \\\\
model.micro_batch_size=1 \\\\
model.global_batch_size=32 \\\\
model.optim.lr=1e-4 \\\\
model.restore_from_path=${MODEL} \\\\
model.data.train_ds.file_names=${TRAIN_DS} \\\\
model.data.train_ds.concat_sampling_probabilities=${CONCAT_SAMPLING_PROBS} \\\\
model.data.validation_ds.file_names=${VALID_DS} \\\\
model.peft.peft_scheme=${PEFT_SCHEME} \\\\
model.peft.lora_tuning.target_modules=[attention_qkv] \\\\
exp_manager.create_wandb_logger=True \\\\
exp_manager.explicit_log_dir=/results \\\\
exp_manager.wandb_logger_kwargs.project=peft_run \\\\
exp_manager.wandb_logger_kwargs.name=peft_llama31_8b \\\\
exp_manager.create_checkpoint_callback=True \\\\
exp_manager.checkpoint_callback_params.monitor=validation_loss
【ポイント】
- LoRAのターゲットはattention_qkvモジュール。効率的に小型アダプタを追加します。
- WandBで学習進捗を可視化。
- 精度はbf16(bfloat16)を使用し、現代GPUで高速かつ省メモリ学習を実現。
max_stepsやglobal_batch_sizeはデータ量・ハードウェアに応じて調整してください。
パラメータの詳細解説
- trainer.precision=bf16:A100/H100などで高速・省メモリ学習(精度低下は最小限)。PEFTの強力な武器です。
- trainer.max_steps=50:学習ステップ数。サンプル小規模なら短時間で終わります。大規模データには増やしてください。
- model.micro_batch_size=1 & model.global_batch_size=32:1GPUあたりバッチサイズ1、全体で32。少量設定で省メモリ化、H100のような大容量なら増やしてもOK。
- model.optim.lr=1e-4:学習率。LoRAアダプタなど微妙なパラメータ調整には小さめの値が最適。
- model.peft.peft_scheme=lora & model.peft.lora_tuning.target_modules=[attention_qkv]:LoRAを使い、クエリ・キー・バリュー層のみを対象に。最小限のパラメータ更新で高効率。
- exp_manager.create_wandb_logger=True:Weights & Biasesで進捗を可視化。Metal Cloudのような強力環境でもモニタリング・チューニングが簡単です。
これらのパラメータが連携し、PEFTを高速・効率的・スケーラブルにします。ハードウェアやデータセット、目的に応じて調整してください。
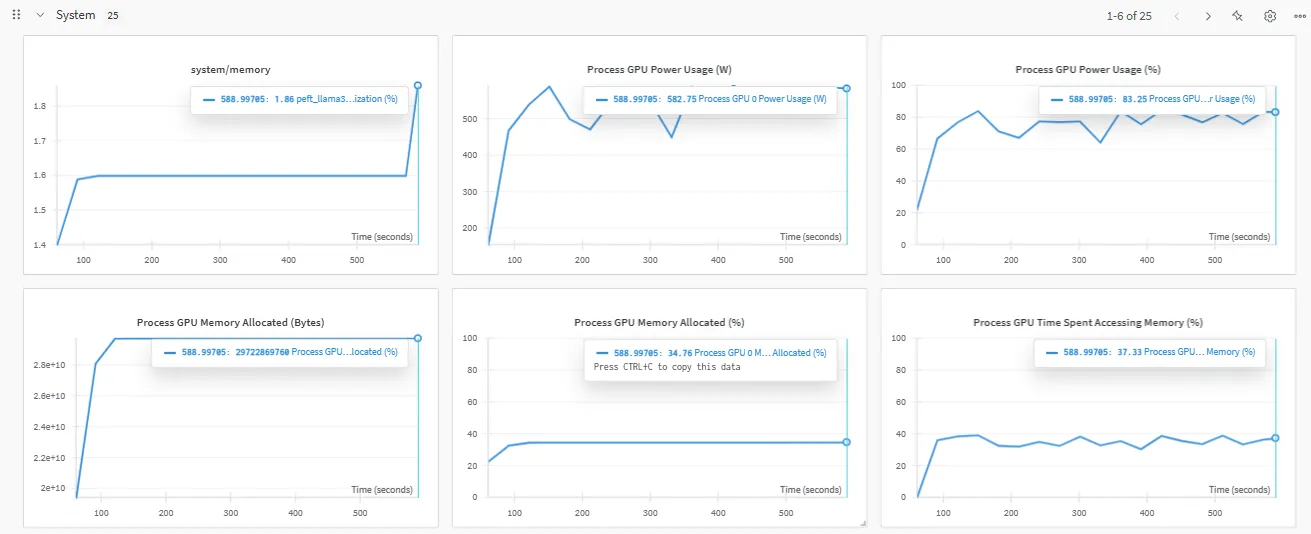
PEFTのリソース使用状況可視化
PEFTファインチューニング中のリソース使用状況について、500秒間の実測例を紹介します(以下グラフ参照)。
- メモリ使用率:システムメモリは低く(最大1.8%)、GPUメモリは最大26GB(A100の80GB中34~40%)程度。巨大モデルとPEFTアダプタの読み込み・処理に応じた挙動です。
- GPU電力・利用率:最大500W消費、利用率は80~85%。A100の並列・テンソル演算効率を示します。PEFTはフルファインチューニングより省リソースであることが分かります。
- メモリアクセス時間:GPUのメモリアクセスは30~40%で推移し、計算とメモリ負荷のバランスが取れています。
これらの指標から、PEFTがLlama 3.1–8Bのような大規模モデルでも単一GPUで現実的にファインチューニングできることが分かります。ハイパーパラメータ調整やスケールアップ時には挙動も変化するので、都度モニタリングしましょう。
ステップ4:推論の実行
最後に、ファインチューニングしたモデルをテストしてみましょう!このスクリプトはテストセットでモデルの性能を評価します。
MODEL="llama31-8b.nemo"
PATH_TO_TRAINED_MODEL="/results/llama31-8b_lora.nemo" # Adjust based on output from training
TEST_DS="[test.jsonl]"
TEST_NAMES="[data]"
OUTPUT_PREFIX="./results/peft_results"
TP_SIZE=1
PP_SIZE=1
[ ! -d ${OUTPUT_PREFIX} ] && mkdir -p ${OUTPUT_PREFIX}
python3 \\\\
/opt/NeMo/examples/nlp/language_modeling/tuning/megatron_gpt_generate.py \\\\
model.restore_from_path=${MODEL} \\\\
model.peft.restore_from_path=${PATH_TO_TRAINED_MODEL} \\\\
trainer.devices=1 \\\\
model.tensor_model_parallel_size=${TP_SIZE} \\\\
model.pipeline_model_parallel_size=${PP_SIZE} \\\\
model.data.test_ds.file_names=${TEST_DS} \\\\
model.data.test_ds.names=${TEST_NAMES} \\\\
model.global_batch_size=32 \\\\
model.micro_batch_size=4 \\\\
model.data.test_ds.tokens_to_generate=20 \\\\
inference.greedy=True \\\\
model.data.test_ds.output_file_path_prefix=${OUTPUT_PREFIX} \\\\
model.data.test_ds.write_predictions_to_file=True
これは、テスト用の入力に対する応答を生成し、それらを保存します。
./results/peft_results_data_preds_labels.jsonl.
出力を確認し、例えば日本語の創作プロンプトにどれだけ適切に応答できているか見てみましょう。
まとめ
これでFPT AI Factory・NVIDIA NeMo・PEFTを活用したLlama 3.1–8Bのファインチューニング手順が一通り終了です。PEFTの仕組みから推論まで、LLMを自分のプロジェクトに合わせて自在に適応できるようになりました。異なるデータセットを使ったり、LoRAのrankを調整したり、複数GPUでスケールしたり――応用方法は無限大です。
FPT AI Factoryに関する詳細やコンサルティングをご希望の場合は、お気軽にお問い合わせください。
FPT AI Factoryの詳細はこちら:https://fptcloud.com/ja/product/fpt-ai-factory-ja/
ホットライン:0800-300-9739
メール:support@fptcloud.jp


