
1. 概要
このガイドは、メタルクラウド(ベアメタルサーバー)上でLLaMA-Factoryを用いた分散型トレーニングのセットアップと運用方法を包括的に解説します。環境構築、Slurmベースのジョブスケジューリング、パフォーマンス最適化について詳しく説明します。
さらに、命令調整サンプルからなるOpen Instruct Uncensored Alpacaデータセットを用い、Llama-3.1-8Bモデルのファインチューニングを4ノード・各ノード8基のNVIDIA H100 GPU上で実施する実践的なトレーニングタスクも含まれています。現実的なトレーニングシナリオを再現するための具体的な手順を紹介します。
本ガイドでは、Slurm(高性能計算向けのオープンソースワークロードマネージャー)を使った分散トレーニング環境の構築手順を説明します。
主な流れは以下の通りです:
- Slurm、CUDA、NCCLを使った効率的なマルチGPU通信環境の準備
- LLaMA-Factoryのインストールとトレーニング環境の構成
- Open Instruct Uncensored Alpacaデータセットを用いたLLaMA-3.1-8Bモデルのファインチューニング
- Slurmによるリソース割り当て・パフォーマンス監視の実施
読者が重視すべきポイント:
- スケーラビリティと効率性:Slurmにより複数GPU・ノードにワークロードを最適分散し、トレーニング時間を短縮
- コスト最適化:適正なジョブスケジューリングによりアイドルGPU時間を低減し、リソース効率を向上
- 信頼性:自動ジョブ再開、エラーハンドリング、リアルタイム監視で安定したトレーニングを実現
- 実践的なトレーニング例:データセット準備、YAMLベース設定、Slurmバッチスクリプトまでを網羅
本ガイドに従えば、同等のトレーニングパイプラインを再現し、メタルクラウド上で自分のLLMトレーニングワークフローを最適化できます。
2. 分散トレーニングにSlurmを選ぶ理由
Slurmは高性能計算(HPC)環境向けに設計された広く使われているオープンソースワークロードマネージャーです。効率的なジョブスケジューリング、リソース割り当て、スケーラビリティを備えており、メタルクラウド上でのAIトレーニングに最適です。
主な利点は以下の通りです:
- リソース効率:GPU・ノード間でワークロードを最適分散し、アイドルリソースを最小化
- スケーラビリティ:少数GPUから数千GPUまでシームレスに拡張可能
- ジョブスケジューリング:ポリシーに基づくジョブ優先順位付け・キューイングでリソースを公平に利用
3. ユースケース
ユースケース:LLaMA-Factoryによる大規模言語モデルのトレーニング
メタルクラウド上でSlurmを活用する実践例として、LLaMA-Factoryフレームワークを用いた大規模言語モデルのトレーニングがあります。トレーニングを複数GPU・ノードに分散させることで、Slurmはトレーニング時間の短縮と安定・効率的な実行を実現します。
主なメリット:
- スケーラビリティ:大規模モデルを効率的にGPU活用してサポート
- コスト最適化:アイドル時間を削減しクラウド計算コストを抑制
- 信頼性:自動ジョブ再開とエラーハンドリングでワークフロー堅牢性を向上
4. 前提条件
事前に以下を確認してください:
4.1. システム要件
- 複数GPU搭載ノードを持つメタルクラウドアカウント
- Slurmジョブスケジューラーのインストールと設定
- 各ノードにNVIDIA CUDA(11.8以上推奨)がインストール済み
- マルチGPU通信のためのNCCL(NVIDIA Collective Communication Library)
- 各ノードにPython 3.8以上
- 分散トレーニング対応のTorch
- 高性能ストレージ
4.2. ネットワーク&SSH設定
- 各ノード間でSSH鍵を使いパスワードなしでSSH接続できること
- ネットワークインターフェースが高速通信(例:InfiniBand)に対応
- NCCLとPyTorchの分散バックエンドがTCP/IP経由で通信可能
ノード接続性は scontrol show nodes もしくは sinfo で確認できます。

5. 環境構築
分散トレーニングのシステム要件が揃ったら、各計算ノードで以下を実行しLLaMA-Factoryをインストールします。必要なパッケージが全てインストールされます。
python3 –m venv venv source venv/bin/activate
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory pip install –e ".[torch,metrics]"6. サンプルトレーニング:Open Instruct Uncensored AlpacaデータセットでLLaMAファインチューニング
現実的なシナリオ例として、Open Instruct Uncensored Alpacaデータセットを使ってLlama-3.1-8Bモデルを命令追従タスク向けにフルファインチューニングします。
6.1. データセット:Open Instruct Uncensored Alpaca
Open Instruct Uncensored Alpacaは、命令―応答ペアからなるデータセットです。命令追従モデルのファインチューニングによく用いられます。Hugging Faceで公開されています。
LLaMA-Factoryでは、YAML設定ファイルにHugging FaceなどのリモートリポジトリからデータセットのURI(アドレス)を直接指定することで、トレーニングの設定ができます。これにより、LLaMA-Factoryが自動的にデータセットをダウンロードしてくれます。
この仕組みを使うには、LLaMA-Factory/data/dataset_info.json というファイルに、使いたいデータセットの情報を記載する必要があります。具体的には、dataset_info.jsonファイルに次のような一行を追加してください。
“uncensored_alpaca”: {“hf_hub_url”: “xzuyn/open-instruct-uncensored-alpaca”}
ローカルにデータセットをダウンロードしたら、dataset_info.jsonに次の1行を追加するだけで準備完了です。
“your_dataset_name”: {“file_name”: “path/to/your/dataset.json”}
6.2. モデル:LLaMA 3.1 8B
LLaMA 3.1 8BモデルはMeta社LLaMAシリーズ第3世代の最新モデルの1つです。軽量かつ高性能で、研究・エンタープライズ利用両方に適しています。
LLaMA 3.1 8Bは、LLaMA-FactoryとDeepSpeedを組み合わせることで、Metal CloudメタルクラウドのマルチGPU/マルチノード環境で効率よくトレーニングできます。
Hugging Faceから直接モデルをダウンロードするには:
huggingface-cli download meta-llama/Llama-3.1-8B –local-dir=Llama-3.1-8B
7. トレーニング設定の準備
LLaMA-FactoryはYAML設定ファイルでトレーニングパラメータを管理します。YAMLによる管理でハイパーパラメータ調整や再現性が容易です。
ここでは、LLaMA 3.1 8Bのファインチューニング用YAML設定ファイル例を紹介します。
7.1. LLaMA 3.1 8B ファインチューニング用YAMLサンプル
LLaMA-Factory/examples ディレクトリに様々なYAML設定例があります。以下はOpen Instruct Uncensored AlpacaデータセットでLLaMA 3.1 8BをフルファインチューニングするYAML例です。
model_name_or_path: meta-llama/Llama-3.1-8B
trust_remote_code: true
stage: sft
do_train: true
finetuning_type: full
deepspeed: examples/deepspeed/ds_z2_config.json
dataset: uncensored_alpaca
template: llama3
cutoff_len: 2048
max_samples: 500000
overwrite_cache: true
preprocessing_num_workers: 16
output_dir: saves/llama3.1-8b/full/sft
logging_steps: 10
save_steps: 10000
plot_loss: true
overwrite_output_dir: true
per_device_train_batch_size: 4
gradient_accumulation_steps: 2
learning_rate: 1.0e-5
num_train_epochs: 2.5
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
val_size: 0.001
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 10000
モデルのURI(HuggingFaceの場合):
model_name_or_path: meta-llama/Llama-3.1-8B
ローカルの場合:
model_name_or_path: path/to/your/model
データセット指定は:
dataset: uncensored_alpaca
サンプル数を50万件に調整:
max_samples: 500000
その他のオプションも必要に応じ調整可能です。
8. Slurmを使ったマルチノードトレーニング設定
YAML設定ファイル(例:llama31_training.yaml)を用意し、4ノード・各ノード8GPUのトレーニング用Slurmスクリプトtrain_llama.sbatchを作成します。
#!/bin/bash
#SBATCH –job-name=multinode-training
#SBATCH –nodes=4
#SBATCH –time=2-00:00:00
#SBATCH –gres=gpu:8
#SBATCH -o training.out
#SBATCH -e training.err
#SBATCH –ntasks=4
nodes=($(scontrol show hostnames $SLURM_JOB_NODELIST ))
nodes_array=($nodes)
head_node=${nodes_array[0]}
node_id=${SLURM_NODEID}
head_node_ip=$(srun –nodes=1 –ntasks=1 -w “$head_node” hostname –ip-address | cut -d” ” -f2)
echo Master Node IP: $head_node_ip
export LOGLEVEL=INFO
export NNODES=4
export NPROC_PER_NODE=8
export HEAD_NODE_IP=$head_node_ip
export HEAD_NODE_PORT=29401
export NODE_RANK=$node_id
export NCCL_IB_DISABLE=0
export NCCL_SOCKET_IFNAME=^lo,docker0
export NCCL_TIMEOUT=180000000
export NCCL_DEBUG=INFO
export NCCL_BLOCKING_WAIT=1
export NCCL_ASYNC_ERROR_HANDLING=1
source venv/bin/activate
srun llamafactory-cli train llama31_training.yaml
ジョブ投入は:
sbatch train_llama.sbatch
![]()
ジョブキュー確認はsqueue

トレーニング状況はtraining.outとtraining.errで確認できます。

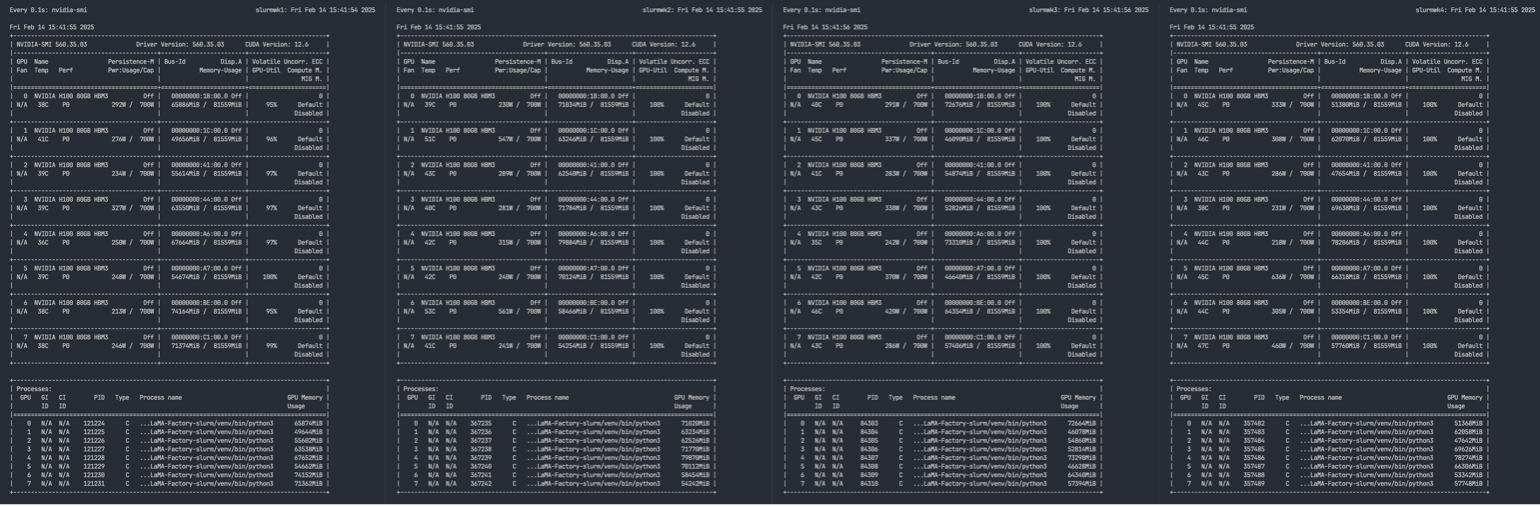
4ノードが完全に活用されます。
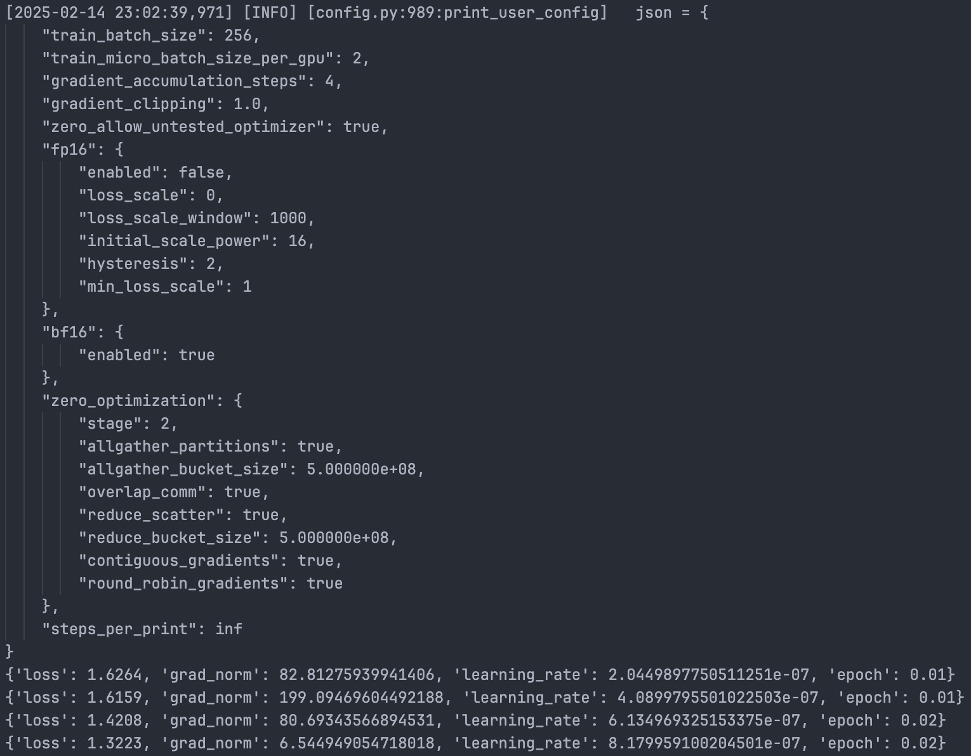
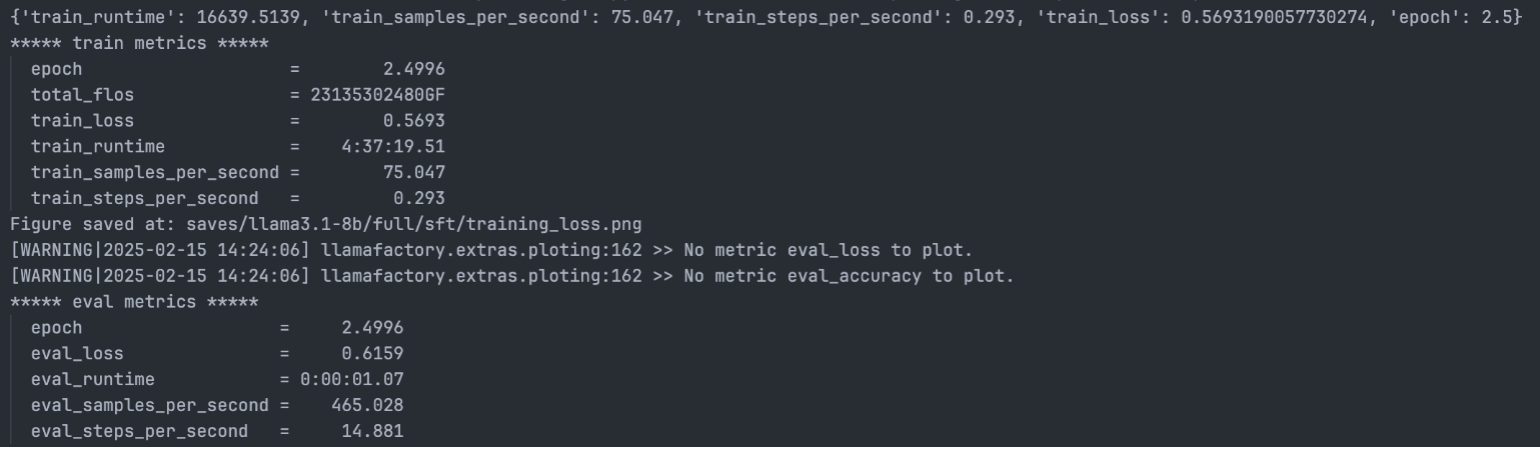
最終的な結果は以下の通りです。
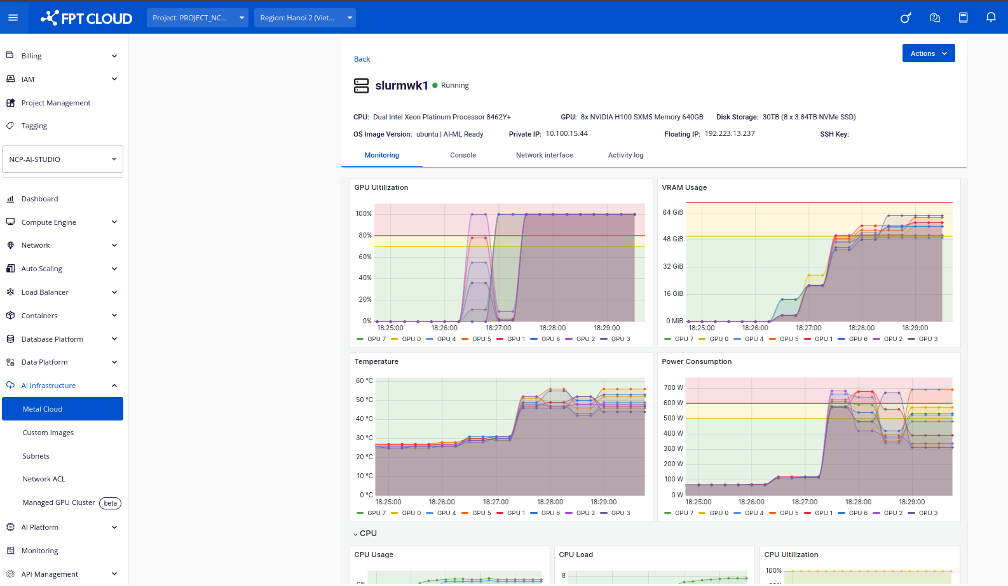
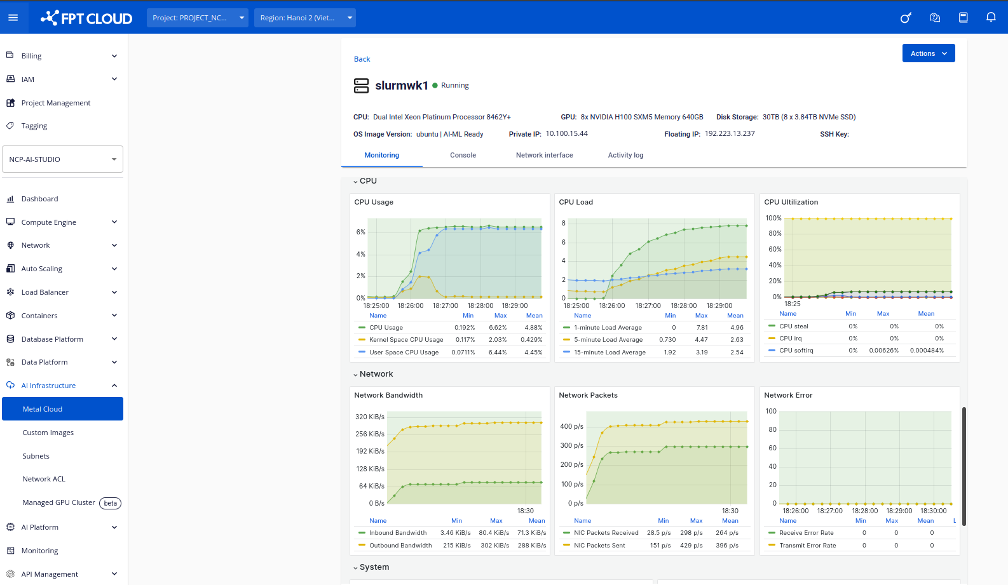
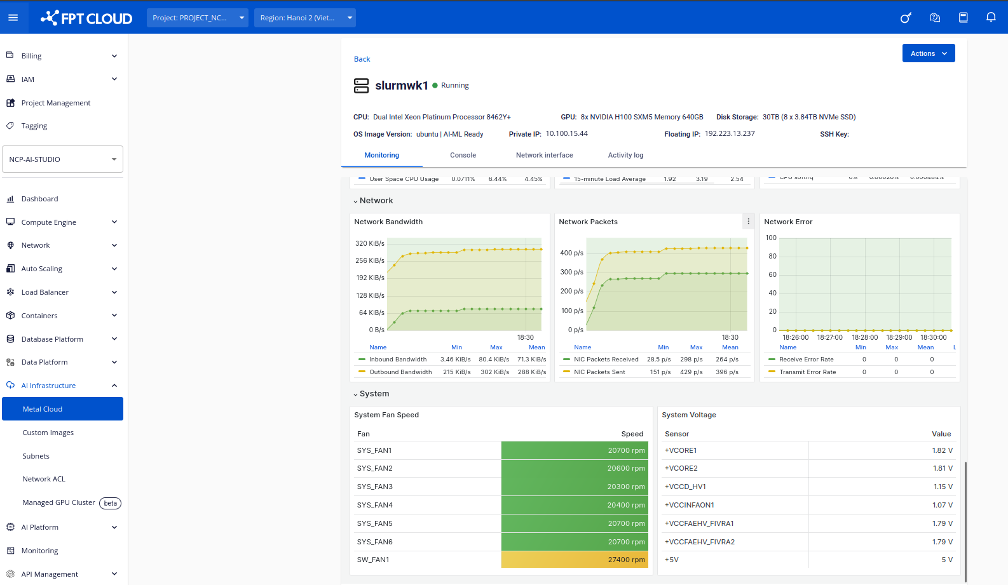
9. トレーニング中のCPU・GPU使用状況のモニタリン
LLaMA 3.1 8Bのような大規模モデルをメタルクラウド上でトレーニングする際は、CPU・GPU・メモリ・ディスク使用量の監視が重要です。適切な監視により:
- ボトルネック(例:GPU未活用、CPU負荷過多)の検出
- バッチサイズ調整などによるリソース最適化
- メモリエラー等によるシステムクラッシュの回避
ベアメタル環境では、以下のリアルタイムハードウェア利用状況を監視ページで確認できます:
- GPU使用率
- VRAM消費量
- CPU負荷
- ディスク&ネットワーク統計
ユーザーは、効率的で安定したトレーニングを確保するために、メタルクラウドのダッシュボードからモニタリングページにアクセスできます。
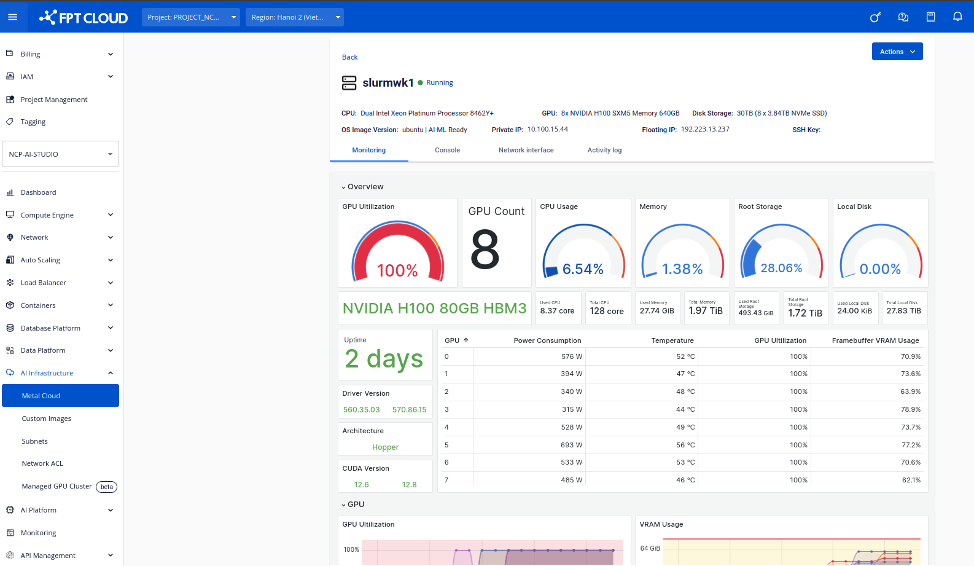
まとめ
本ガイドでは、メタルクラウド上でのLLaMA-Factory分散トレーニング環境の構築手順を体系的に説明しました。
- 環境構築
- Slurmによるジョブ投入
- LLaMA-Factory+DeepSpeed分散トレーニング
- 大規模モデル向け最適化
これらの手順に従うことで、メタルクラウドのマルチノードGPUクラスタ上でLLaMAモデルの効率的なファインチューニングが可能です。
メタルクラウドはFPT AI Factoryでご利用申込受付中です。
詳細はこちら:https://fptcloud.com/ja/product/fpt-ai-factory-ja/
ご相談・お問い合わせ:
- ホットライン:0800-300-9739


