
1. Flamingo紹介:視覚言語モデルのための少数事例学習

Flamingo(原論文:https://arxiv.org/pdf/2204.14198)は、マルチモーダル機械学習における少数事例学習の課題を解決するためにGoogle DeepMindチームが設計した視覚言語モデル(VLM)ファミリーです。
このモデルは3つの主要なアーキテクチャ革新によって構築されています:
- 強力な事前訓練済みの視覚専用モデルと言語専用モデルを橋渡しする
- 視覚データとテキストデータが任意に混在したシーケンスを処理可能
- 画像や動画を入力としてシームレスに取り込める
この柔軟性により、Flamingoは画像とテキストが混合した大規模ウェブデータで訓練可能であり、少数の事例から新しいタスクを学習する能力の基盤となります。結果として、単一のFlamingoモデルが視覚質問応答、キャプション生成、多肢選択問題など幅広いタスクで最先端の性能を達成できます。タスク固有の例でプロンプトを与えるだけで、数千倍のデータでファインチューニングされたモデルを凌駕する場合もあります。
2. Flamingoの動作原理
モデルアーキテクチャ
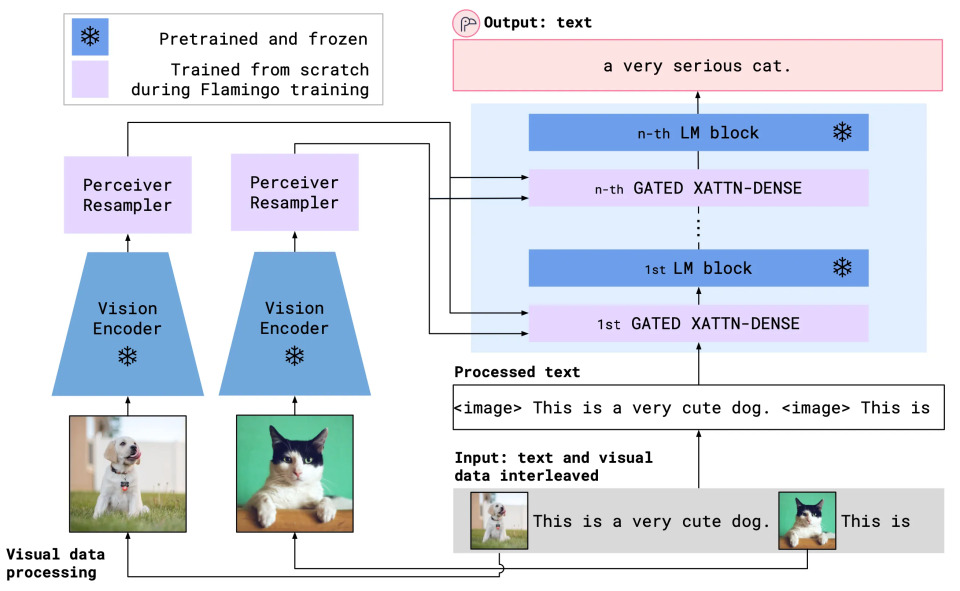
アーキテクチャは以下2つの主要経路で構成されます:
a. 視覚経路(左側)
視覚データ(画像)を処理し、言語モデル用に準備する役割:
- 視覚エンコーダー:入力画像から特徴量を抽出する事前訓練済みモデル(凍結された雪結晶アイコンで表示)。訓練中は重みが固定
- Perceiver Resampler:可変サイズの視覚特徴を固定数の出力トークンにマッピング。新規学習コンポーネント(紫色)。Flamingoでは出力画像トークン数を5に設定
b. 言語経路(右側)
テキストを処理し、視覚情報と融合:
- インターリーブ入力:<image>プレースホルダーを含むテキストシーケンス
- LMブロック:Chinchillaモデルなどの事前訓練済み言語モデル。視覚エンコーダー同様に凍結
- Gated XATTN-DENSE:両経路を接続する新規学習モジュール。<image>プレースホルダー検出時に、テキストクエリを用いて視覚トークンにクロスアテンション実行。「ゲート」機構で視覚情報の影響度を動的に制御
少数事例学習の新たな基準を確立
Flamingoは16種類のタスクで厳密にテストされ、各タスクにわずか4つの例しか与えられない場合でも、従来の少数ショット学習モデルを一貫して上回る性能を示しました。いくつかのケースでは、大規模なファインチューニングや膨大なデータセットに依存する手法よりも優れたパフォーマンスを発揮し、その高い汎化能力を際立たせています。
大規模なアノテーションやタスク固有の再学習の必要性を最小限に抑えることで、Flamingoは視覚言語モデルの効率性において大きな進歩を示しています。限られた例から迅速に学習できる能力は、AIを人間のような適応性に近づけ、より幅広い現実世界の応用を容易かつ正確に実現します。
3. なぜファインチューニングするのか?
新しいH100システムの性能を検証するため、LLMの実行能力をテストしています。この評価のために、Flamingoモデルのコミュニティ主導による実装をファインチューニングすることを選びました。
本プロジェクトは2つの目的を持っています:
- システム検証:このファインチューニングタスクを通じてH100インフラストラクチャの厳格なテストを行い、大規模モデルの学習と実行に必要な計算負荷を処理できることを確認します。
- コード検証:元のFlamingoモデルのコードが公開されていないため、コミュニティ開発版に依存しています。このプロセスを通じて、このオープンソース実装が論文で記載されたモデルの忠実な再現であり、実際に動作するかどうかを確認します。
したがって、ここではモデルの精度評価よりも、主にシステムの能力に焦点を当てていることにご留意ください。
本プロジェクトでは、元のFlamingoモデルが公開されていないため、ML-Foundationが開発したFlamingoのレプリカであるOpenFlamingoを使用しました。目的は、OpenFlamingoを元のデータセットでファインチューニングし、制御された条件下でその性能を評価することです。
この実験は主に2つの目的を果たしました:(1)同一データセットでファインチューニングした際のモデルの安定性と再現性の評価、(2)NVIDIA H100 GPUシステム上での計算効率・メモリ使用量・大規模マルチモーダルタスク処理能力のベンチマークです。
これらの知見は、OpenFlamingoを実利用に投入する際のハードウェア最適化の指針となります。
4. どのようにファインチューニングしたか
インストール
既存の環境にパッケージをインストールするには
| 1 | pip install open-flamingo |
または、OpenFlamingo用のconda環境を作成するには
| 1 | conda env create -f environment.yml |
トレーニングや評価の依存関係をインストールするには、最初の2つのコマンドのいずれかを実行します。すべてをインストールするには3つ目のコマンドを実行します。
| 1
2 3 |
pip install open-flamingo[training]
pip install open-flamingo[eval] pip install open-flamingo[all] |
requirements.txtファイルは3つあります:
- requirements.txt
- requirements-training.txt
- requirements-eval.txt
用途に応じて、pip install -r <requirements-file.txt> でいずれかをインストールできます。ベースファイルにはモデル実行に必要な最低限の依存関係のみが含まれています。
開発
オープンソースの著者は、リポジトリ内のチェックにフォーマットを合わせるためにpre-commitフックを使用しています。
pre-commitをインストールするには
| 1 | pip install pre-commit |
または、MacOSの場合はbrewを使用してください。
| 1 | brew install pre-commit |
インストールされたバージョンを確認するには
| 1 | pre-commit – version |
リポジトリのルートで以下と実行します。
| 1 | pre-commit install |
以降、git commit を実行するたびにチェックが行われます。フックによってファイルが再フォーマットされた場合は
| 1 | git add |
で変更されたファイルをaddし以下を再度実行します。
| 1 | git commit |
トレーニング手順
OpenFlamingoをトレーニングするには、環境がenvironment.ymlと一致していることを確認してください。
データ処理
コードベースではWebDatasetを使い、画像とテキストのシーケンスを含む.tarファイルを効率的に読み込みます。トレーニング時には—dataset_resampledフラグでシャードのリサンプリング(復元抽出)を推奨します。
- LAION-2Bデータセット
LAION-2Bは20億件のウェブスクレイピングされた(画像、テキスト)ペアを含みます。img2datasetを使ってこのデータセットをtarファイルとしてダウンロードしてください。
- Multimodal C4データセット
OpenFlamingoは、ウェブからスクレイピングされた1億300万件の画像・テキストが交互に入るMMC4のフルバージョンで学習します。トレーニング時には、シーケンスを256テキストトークンと1シーケンスあたり6画像に切り詰めます。コードベースは、base64でエンコードされた生画像を含む.jsonファイルが入った.tarファイルを想定しています。 MMC4をこの形式に変換するスクリプトが用意されています:(1)MMC4提供のスクリプト(例:fewer_facesv2.sh)で.zipファイルとしてMMC4シャードをダウンロード。(2)MMC4提供のスクリプト(例:download_images.py)で生画像を画像ディレクトリにダウンロード。(3)scripts/convert_mmc4_to_wds.pyを実行し、期待形式のtarファイルに変換。
- カスタマイズデータセット
最近、MMC4データセットのダウンロードURLでアクセス障害が報告されています。そのため、MMC4形式へ変換するスクリプトを用意しました(この例ではADNIデータセットをターゲットに、サンプルbase64画像データを固定で使用)。カスタムデータセットに合わせてこのスクリプトを修正できます。
| 1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
import json
import os import tarfile
def compress_directory_to_tar(directory_path): json_files = [f for f in os.listdir(directory_path) if f.endswith(‘.json’)] os.makedirs(‘replicate_mmc4’, exist_ok=True)
for i in range(0, len(json_files), 20): batch_files = json_files[i:i+20] tar_file_path = os.path.join(‘replicate_mmc4’, f”{i//20:09d}.tar”)
with tarfile.open(tar_file_path, “w:gz”) as tar: for file in batch_files: tar.add(os.path.join(directory_path, file), arcname=file)
print(f”Batch {i//20} compressed to {tar_file_path}”)
def convert_adni_to_mmc4(input_json_path, output_folder): # Ensure the output folder exists os.makedirs(output_folder, exist_ok=True)
# Load the large JSON file with open(input_json_path, ‘r’) as f: data = json.load(f)
matched_text_index = 0
# Iterate over each item in the list and save it as a separate JSON file for idx, item in enumerate(data): # Ensure compatibility with the structure of f9773b9c866145c28fe0b701dde8dfbe.json
# Handle text list: conversations = item.get(“conversations”, None) if conversations is not None: text_list = [] for conversation in conversations: text_list.append(conversation[“value”])
# Check for &amp;lt;image&amp;gt; tag in the first element of conversations list first_convo = conversations[0][“value”] if “&amp;lt;image&amp;gt;” in first_convo: if first_convo.startswith(“&amp;lt;image&amp;gt;”): matched_text_index = 0 elif first_convo.endswith(“&amp;lt;image&amp;gt;”): matched_text_index = 1
item[“text_list”] = text_list
# Handle image’s base64 content: with open(‘./sample_base64.txt’, ‘r’) as f: sample_img_base64_data = f.read()
# Handle image info: img_info = [] images_list = item.get(“image”, None) if images_list is not None: for img in images_list: img_obj = {} img_obj[“image_name”] = img img_obj[“raw_url”] = “https://example.com/{}”.format(img) img_obj[“matched_text_index”] = matched_text_index img_obj[“matched_sim”] = 0.75 img_obj[“image_base64”] = sample_img_base64_data img_info.append(img_obj)
# Create similarity_matrix similarity_matrix = [] for img in img_info: for _ in range(len(text_list)): inner_list = [0] * len(text_list) inner_list[matched_text_index] = 1 similarity_matrix.append(inner_list)
# item[“similarity_matrix”] = similarity_matrix
output_item = { ”id”: item.get(“id”, None), ”url”: “https://example.com“, ”text_list”: item.get(“text_list”, None), ”image_info”: img_info, ”similarity_matrix”: similarity_matrix, ”could_have_url_duplicate”: 0 }
# Save the item as a separate JSON file output_path = os.path.join(output_folder, f”{idx:05d}.json”) with open(output_path, ‘w’) as out_f: json.dump(output_item, out_f) |
ChatGPT生成シーケンス
一部のモデル(下記)は、LAIONから画像を取得し、ChatGPTで生成された(画像、テキスト)シーケンスを使って実験的に学習しています。これらのシーケンスを含むシャードはCodaLabワークシートで公開されています。リリースされたシャードには生画像は含まれていないため、jsonファイル内のURLから画像を事前ダウンロードし、base64に変換してから学習データとして使用してください。
ChatGPT生成シーケンスで学習したモデル:
- OpenFlamingo-4B-vitl-rpj3b
- OpenFlamingo-4B-vitl-rpj3b-langinstruct
トレーニングコマンド
training script(scripts/)にSlurmのサンプルが提供されています。あるいは、下記の(本事例で実際に使われた)コマンドを修正して利用可能です。
| 1
2 3 4 5 6 7 8 9 10 11 12 13 14 |
torchrun –nnodes=1 –nproc_per_node=8 open_flamingo/train/train.py \
–lm_path anas-awadalla/mpt-1b-redpajama-200b \ –tokenizer_path anas-awadalla/mpt-1b-redpajama-200b \ –cross_attn_every_n_layers 1 \ –dataset_resampled \ –batch_size_mmc4 2 \ –train_num_samples_mmc4 1000 \ –workers=4 \ –run_name OpenFlamingo-3B-vitl-mpt1b \ –num_epochs 20 \ –warmup_steps 1875 \ –mmc4_textsim_threshold 0.24 \ –mmc4_shards “modifications/VLM_ADNI_DATA/replicate_mmc4/{000000000..000000040}.tar” \ –report_to_wandb |
MPT-1B baseとinstructモデリングコードは、labelsキーワード引数を受け付けず、forward()内でクロスエントロピー損失を直接計算しません(このコードベースが期待するもの)。こちらとこちらで見つかる修正版MPT-1Bモデルの使用を推奨します。
分散トレーニング
デフォルトでtrain.pyはPytorchのDistributedDataParallelを使います。
FullyShardedDataParallelを使うには—fsdpフラグを指定します。
OpenFlamingoチームからのFSDPに関する注意事項: —fsdp_use_orig_params dfフラグの使用を推奨します。このフラグなしで—fsdpをオンにすると、全ての言語モデル埋め込みがトレーニング中にunfreezeされます(デフォルトでは新規追加された<image>と<|endofchunk|>トークンのみトレーニングされます)。 注:このフラグ使用時、OPTで問題が発生しています。他の言語モデルは互換性があります。 現在のFSDPラッピング戦略では、重みを共有する(tied)言語モデル埋め込み(入力/出力の両方)をトレーニングできません。そうしたモデルをFSDPで学習するには—freeze_lm_embeddingsフラグで埋め込みをフリーズしてください。
また、勾配チェックポイントや混合精度学習も実装しています。—gradient_checkpointingおよび—precision引数を使用可能です。
OpenFlamingoモデルの初期化
OpenFlamingoはOpenCLIPパッケージの事前学習済みビジョンエンコーダ(OpenAIの事前学習済みモデルを含む)をサポートしています。 また、transformersパッケージの事前学習済み言語モデル(MPT、RedPajama、LLaMA、OPT、GPT-Neo、GPT-J、Pythiaなど)もサポートしています。
| 1
2 3 4 5 6 7 8 9 |
from open_flamingo import create_model_and_transforms
model, image_processor, tokenizer = create_model_and_transforms( clip_vision_encoder_path=”ViT-L-14″, clip_vision_encoder_pretrained=”openai”, lang_encoder_path=”anas-awadalla/mpt-1b-redpajama-200b”, tokenizer_path=”anas-awadalla/mpt-1b-redpajama-200b”, cross_attn_every_n_layers=1, cache_dir=”PATH/TO/CACHE/DIR” # Defaults to ~/.cache |
5. 結果
以下はWandBsから報告されたNVIDIA H100 GPUの結果です。
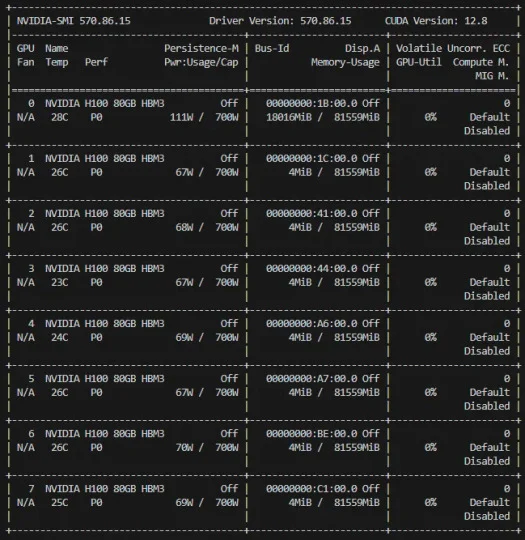
使用したNVIDIA H100システム:
- 8基のNVIDIA H100 80GB HBM3 GPUを搭載していますが、このトレーニング設定では分散トレーニングに2基のみで十分です。
- 各NVIDIA H100は80GBの高帯域幅メモリ(HBM3)を搭載しており、HPCやAI学習システムに相当します。
- NVIDIA H100 GPUはP0パフォーマンス状態にあり、これは最高のパフォーマンスモードです。
モデルの報告指標
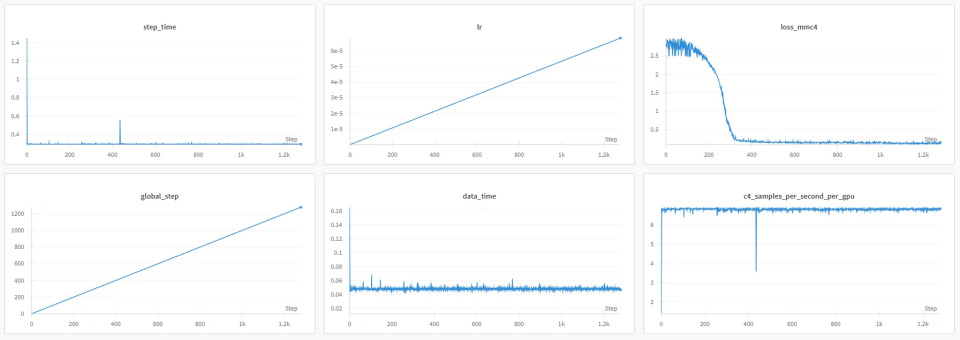
- 学習メトリクスは、様々なパラメータで期待通りの挙動を示しており、プロセスが正常であることを示しています。
- ロスカーブは初期に急激に低下し、その後安定して収束の良さを示しています。
- 学習率は線形ウォームアップスケジュールに従い、初期学習の安定化を図っています。
- ステップ時間やデータローディング時間は概ね安定していますが、システムの揺らぎやチェックポイント、データ取得遅延による一時的なスパイクが見られます。
- グローバルステップは線形的に進み、着実な反復増加を示しています。
- GPUあたり1秒あたりのサンプル数も安定しており、マイナーな低下は見られるものの性能に大きな影響はありません。
- 全体として、時折のステップタイムやデータタイムのスパイクを監視しつつ効率最適化を図ることで、正常な学習挙動が示唆されます。
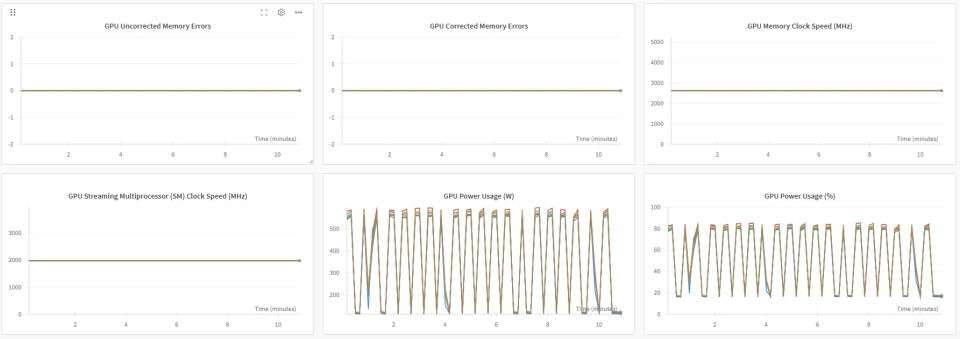
- GPUのメモリ修正エラー(左上):線はゼロのままで、修正されていないメモリエラーがないことを示します。
- GPU補正メモリ誤差(上中央):プロットはゼロでフラットで、補正メモリ誤差はありません。
- GPUメモリクロックスピード(右上):通常;一定のクロック速度は動的周波数のスケーリングやスロットリングがないことを示唆しています。
- GPUストリーミングマルチプロセッサ(SM)クロックスピード(左下):通常;安定したクロック速度は熱的スロットリングがないことを示唆しています。
- GPU電力使用量(W)(下中央):循環的なパターンを示し、ワークロード実行中にGPUの消費電力が変動することを示しています=>バッチ処理、ワークロードスケジューリング、動的電力管理が原因と考えられます。
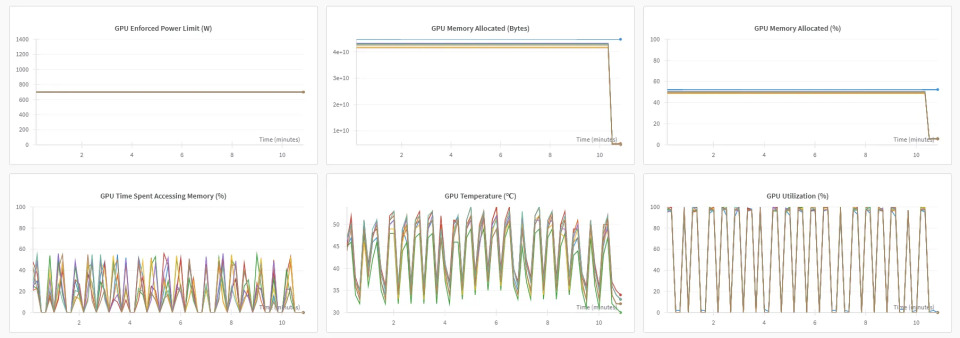
- GPU強制電力制限(左上):正常。GPUが事前定義された電力制限を超えていないことを示します。
- GPUメモリ割り当て(バイト)(中央上):メモリ割り当ては安定していますが、終了時に突然低下します(これは学習終了時)。
- GPUメモリ割り当て(%)(右上):バイト同様に正常です。
- GPUメモリアクセス時間(%)(左下):上記のGPU電力使用量と相関しています。
- GPU温度(℃)(中央下):上記のGPU電力使用量と相関しています。
- GPU使用率(%)(右下):上記のGPU電力使用量と相関しています。


