
What is data preprocessing, and why does it determine the success or failure of every AI and machine learning project? Data preprocessing is the essential process of collecting, cleaning, and transforming raw data into a structured format. At FPT AI Factory, we provide cutting-edge AI solutions that help organizations implement robust data preprocessing pipelines and accelerate their AI development journey.
1. What Is Data Preprocessing?
Data preprocessing is the process of cleaning, transforming, and organizing raw data into a reliable format for analysis or machine learning. It includes key steps such as handling missing values, removing duplicates, correcting inconsistent formats, encoding categorical variables, scaling features, and reducing noise. By addressing common data issues before training, preprocessing helps improve model accuracy, stability, and overall reliability.
For example, in a customer churn prediction project, raw customer data may contain missing ages, duplicated accounts, inconsistent date formats, and text labels such as “Yes/No” that a model cannot directly process. Through preprocessing, missing values can be filled, duplicates removed, dates standardized, and categorical labels encoded into numerical values, making the dataset ready for machine learning.
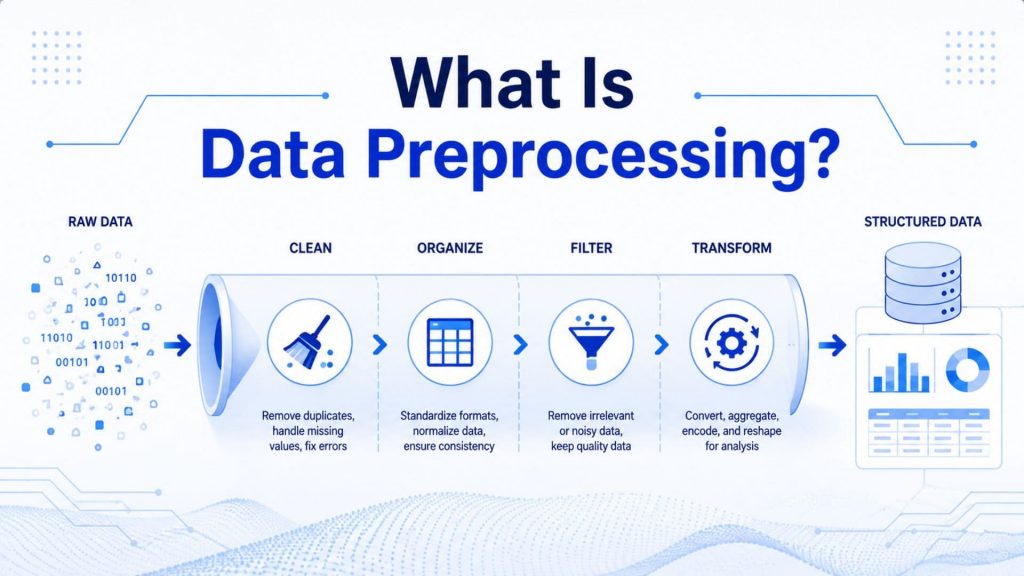
Data preprocessing is the structured process of cleaning, transforming, and organizing raw data
2. Why Is Data Preprocessing Important?
Data preprocessing is not just a technical formality, it is a decisive factor in whether an AI or machine learning project succeeds or fails. Here are the key reasons why data preprocessing deserves serious attention in every data pipeline:
- Improves data quality: Raw data frequently contains noise, missing values, and inconsistencies. Preprocessing cleans and prepares it, raising its overall quality and making it fit for analysis.
- Reduces noise and inconsistencies: Removing irrelevant or erroneous data helps prevent misleading insights and stops models from becoming confused during training.
- Helps models learn from reliable inputs: Models rely on clean, structured data to learn patterns accurately. When datasets contain duplicates or inconsistent formats, algorithms struggle to identify what is meaningful.
- Improves model accuracy and performance: Clean and well-structured data enables algorithms to learn patterns more effectively, leading to better predictions and outcomes.
- Reduces training errors: Proper preprocessing, including data wrangling, transformation, and feature scaling, can significantly reduce the computational resources and time required to train a machine learning or AI system.
- Supports better decision-making from data: When data is concise, complete, and relevant, it improves the performance of machine learning models and enables organizations to draw more reliable insights from their data.

Key reasons why data preprocessing deserves serious attention in every data pipeline
3. How Does Data Preprocessing Work?
Data preprocessing follows a structured sequence of steps, each designed to bring raw data closer to a state where machine learning models can extract meaningful patterns. While the exact workflow may vary by project, the core stages remain consistent across most AI and data science pipelines.
3.1 Data collection and inspection
Data collection and inspection is the first step in preprocessing, where data is gathered from sources such as databases, APIs, spreadsheets, sensors, or user logs. At this stage, teams review the dataset’s size, structure, data types, missing values, duplicate records, inconsistent formats, and obvious outliers before deciding what cleaning or transformation steps are needed.
For example, a telecommunications company may use the Telco Customer Churn dataset, which contains 7,043 customer records and information such as tenure, contract type, monthly charges, payment method, and churn status. During inspection, analysts can identify missing values in the TotalCharges column, check for duplicate customer IDs, and review unusual billing amounts before moving to the cleaning stage.
3.2 Data cleaning
Data cleaning focuses on fixing problems found during inspection, such as missing values, duplicate entries, irrelevant fields, incorrect labels, and inconsistent formats. This step makes the dataset more accurate and reliable, reducing the risk of poor model predictions caused by flawed or noisy data.
Continuing with the churn prediction example, missing values in TotalCharges may be imputed or removed, duplicate customer records eliminated, and inconsistent entries standardized. These corrections ensure the dataset accurately reflects customer behavior before model training begins.
3.3 Data transformation
Data transformation converts cleaned data into a format that machine learning models can process effectively. Common techniques include scaling numerical values, normalizing ranges, encoding categorical variables, and converting text-based labels into numerical representations.
In the Telco Customer Churn dataset, fields such as Contract, InternetService, and PaymentMethod contain categorical values that must be encoded into numerical representations. Numerical features such as MonthlyCharges and TotalCharges may also be scaled to ensure that large values do not disproportionately influence the model.
3.4 Feature preparation
Feature preparation involves selecting, creating, and refining the most useful input variables for the model. This step may include creating new features from existing data, removing irrelevant columns, combining related fields, or using domain knowledge to highlight patterns that improve model performance.
For example, analysts may create tenure groups (new, medium-term, and long-term customers) or derive a customer value metric from monthly charges and contract length. Features that contribute little predictive value can also be removed to improve model efficiency and accuracy.
3.5 Data splitting for training and testing
The final preprocessing step is dividing the prepared dataset into separate subsets for training, validation, and testing. The train-validation-test split helps assess how well a machine learning model will generalize to new, unseen data, and also prevents overfitting, where a model performs well on training data but fails to generalize to new instances.
In the churn prediction project, the 7,043 customer records may be split using an 80/20 ratio, with approximately 5,634 records used for training and 1,409 records reserved for testing. The trained model can then be evaluated on unseen customer data to measure how accurately it predicts future churn behavior.
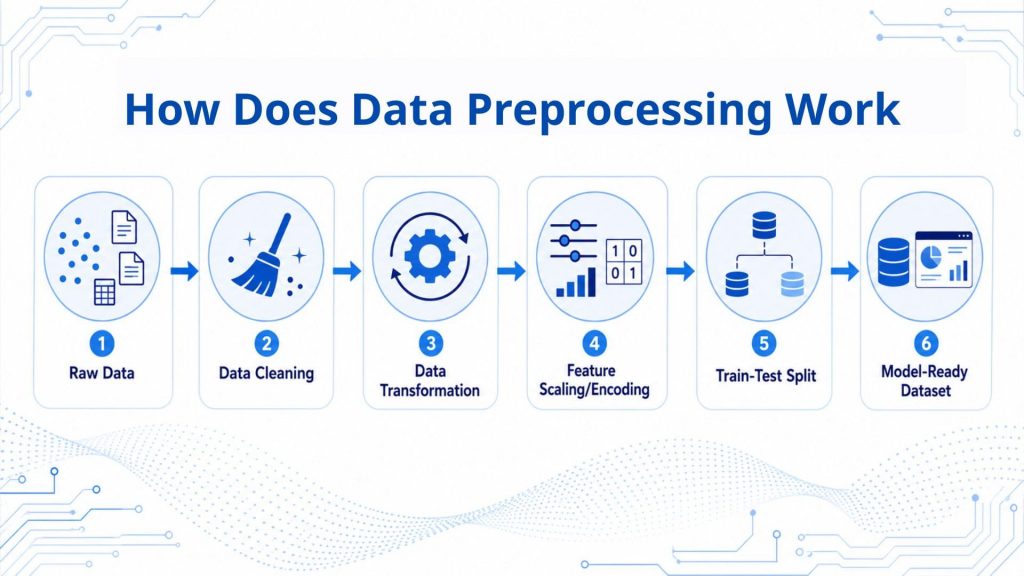
Data preprocessing follows a structured sequence of steps
4. Common Data Preprocessing Techniques
Understanding the individual techniques within data preprocessing helps teams apply the right method for each type of data quality issue. Below are six of the most widely used approaches, each with a practical example.
4.1 Handling missing values
Missing values are among the most frequent issues in real-world datasets and can introduce bias or cause model failures if left unaddressed. Common approaches include replacing missing values with the mean, median, or mode.
For instance, if “Age” contains gaps, the mean age from available records can fill them in. For more complex cases, methods like KNN or MICE imputation account for relationships between variables to produce more accurate estimates.
4.2 Removing duplicates
Duplicate records arise from data entry errors, system glitches, or merging multiple sources, and they can significantly distort model training. If certain records are heavily duplicated, the model might incorrectly learn that these instances are far more common or significant than they actually are.
In sales data, for example, a duplicated transaction entry could artificially inflate revenue numbers, removing duplicates ensures the data reflects the true nature of transactions.
4.3 Detecting and treating outliers
Outliers are extreme data points caused by measurement errors, data entry mistakes, or rare events that can skew model performance. The IQR method flags any value below Q1 − 1.5×IQR or above Q3 + 1.5×IQR, while the Z-Score method measures how many standard deviations a point lies from the mean. Once detected, outliers can be removed or treated through Winsorization, replacing extreme values with the nearest non-outlier boundary rather than discarding the entire row.
In a real estate pricing dataset, one property is mistakenly listed at $50,000,000 while all others range between $100,000–$800,000. Removing this outlier via the IQR method prevents the regression model from learning a distorted price range.
4.4 Encoding categorical variables
Most machine learning algorithms require numerical inputs, yet many datasets contain text-based categories such as gender, contract type, or product segment. One-hot encoding creates a binary column per category, ideal for unordered data, while label encoding assigns each category a unique integer, better suited for ordered variables such as “low, medium, high.” Choosing the right method prevents the model from misreading categories as having a false numeric hierarchy.
For instance, a churn dataset contains a “Contract Type” column with “Month-to-month,” “One year,” and “Two year” values. One-hot encoding splits this into three binary columns, letting the model interpret each contract type independently without implying a false numeric order.
4.5 Normalization and standardization
When features span very different value ranges, distance or gradient-based algorithms can become biased toward the largest values. Normalization scales features to a 0–1 range to ensure equal contribution, while standardization rescales data to a mean of 0 and standard deviation of 1, better suited for normally distributed data. Both techniques help models converge faster and produce more balanced outputs.
For example, in a loan approval model, “Annual Income” ranges from $20,000–$500,000 while “Number of Credit Cards” ranges from 0–10. After normalization, both features sit on the same 0–1 scale and are weighted fairly by the algorithm.
4.6 Data balancing and sampling
When one class significantly outnumbers another, models become biased toward the majority class, appearing accurate on paper while failing on the cases that matter most. In fraud detection, there might be 99,000 normal transactions and only 1,000 fraudulent ones, causing a model to predict “normal” for every case and miss actual fraud entirely.
For instance, SMOTE (Synthetic Minority Over-sampling Technique) resolves this by generating synthetic minority samples through interpolation between existing examples and their nearest neighbors, increasing diversity without simply duplicating records.
4.7 Feature engineering
Feature engineering is the process of creating, transforming, or combining existing variables to provide more meaningful information for machine learning models. While data cleaning focuses on improving data quality, feature engineering aims to improve the predictive power of the dataset by exposing patterns that may not be immediately visible in the raw data.
Common techniques include creating ratio-based features, extracting components from dates and timestamps, aggregating historical behavior, generating interaction terms between variables, and converting unstructured data into structured representations. Well-designed features can significantly improve model performance, sometimes even more than switching to a more advanced algorithm.
For example, ride-hailing platforms such as Uber and Lyft do not rely solely on raw pickup timestamps. Instead, they engineer additional features such as “hour of day,” “day of week,” “weekend versus weekday,” and “holiday indicator” to better capture demand patterns.
A ride request at 8:00 AM on a Monday carries a very different meaning from a request at 8:00 AM on a Sunday, even though the original timestamp format appears similar. By transforming raw timestamps into more informative features, demand forecasting models can make more accurate predictions and allocate drivers more efficiently.
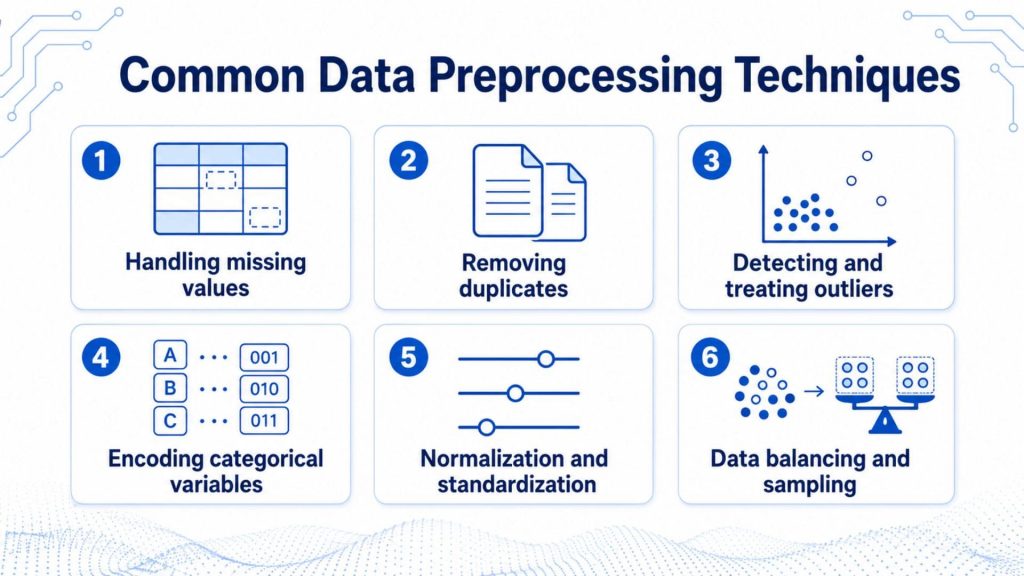
Understanding the individual techniques within data preprocessing helps teams apply the right method
5. Data Preprocessing by Data Type
Different data types come with unique structural challenges, so preprocessing techniques must be tailored to match. What works for images won’t apply to text, and time-series data demands a completely different pipeline from tabular records. Here is how preprocessing adapts to five major data types.
5.1 Text preprocessing for NLP
Raw text is unstructured and filled with noise that models cannot interpret directly. Core steps include tokenization (splitting text into words), converting to lowercase, removing stop words like “the” or “is,” and applying stemming or lemmatization to reduce words to their root form. For modern models like BERT or GPT, advanced tokenization techniques such as Byte-Pair Encoding (BPE) are used instead, as these models learn linguistic patterns directly from raw text.
5.2 Image preprocessing
Raw images vary in size, resolution, and brightness, making them incompatible with models that require fixed, consistent inputs. Key techniques include noise reduction, contrast enhancement via histogram equalization, normalization to standardize pixel ranges, resizing for consistent dimensions, and data augmentation, applying rotations and flips to simulate real-world variability and improve generalization.
5.3 Audio preprocessing
Raw audio signals contain background noise, varying sample rates, and amplitude differences that make direct model training unreliable. Before feature extraction, audio typically undergoes amplitude normalization, resampling to a standard rate, and removal of silent segments, with adaptive noise reduction applied to handle changing environmental conditions.
MFCC (Mel-Frequency Cepstral Coefficients) is then used to transform audio into a compact numerical representation, capturing spectral characteristics suitable for speech recognition and audio classification.
5.4 Time-series preprocessing
Time-series data carries temporal dependencies and patterns that standard preprocessing methods fail to capture. Core tasks include interpolating missing observations, correcting outliers, applying differentiating or detrending to achieve stationarity, and scaling values to stabilize variance over time. Lag features, capturing past values and rolling statistics such as 7-day moving averages, are also engineered to help models understand temporal dependencies.
5.5 Tabular data preprocessing
Tabular data is the most common format in business applications, including cleaning corrupted records, scaling numeric values, imputing missing data, clipping outliers, and transforming features. A common mistake is assigning arbitrary numbers like 1, 2, 3 to unordered categories such as city names, which creates a false hierarchy that misleads the model.
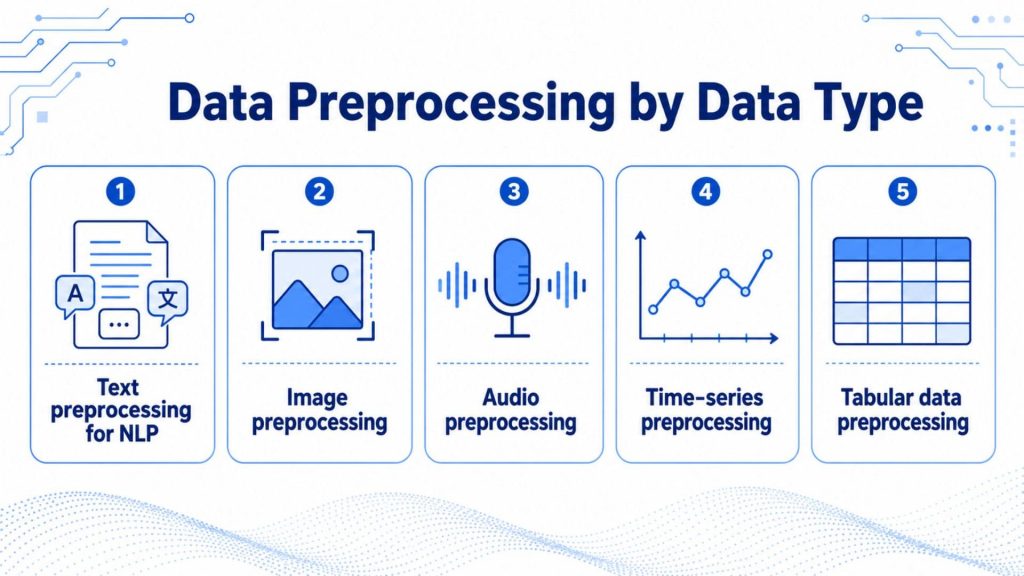
Different data types come with unique structural challenges
6. Data Preprocessing vs Data Cleaning vs Data Transformation
These three terms are frequently used interchangeably, yet each refers to a distinct concept with a different scope and purpose. The table below breaks down the key differences across six criteria.
| Criteria | Data Preprocessing | Data Cleaning | Data Transformation |
| Definition | A broad process of converting raw data into a suitable format for machine learning, encompassing cleaning, transformation, feature selection, normalization, and reduction | The process of detecting incomplete, incorrect, inaccurate, or irrelevant parts of data and then replacing, modifying, or deleting the dirty data | The process of converting data structures, formats, and/or types to make data more accessible and usable for analysis or model training |
| Main purpose | Prepare raw data end-to-end so it is ready for model training and analysis | Ensure data is accurate, complete, and consistent by fixing errors and removing noise | Convert clean data into a format and scale that algorithms can process effectively |
| Scope | Broadest scope: Encompasses cleaning plus transformations, integration, feature engineering, and optimization to prepare datasets for analysis or machine learning models | Narrower scope: Focused on eliminating errors and inconsistencies to make the dataset reliable, without changing its structure | Specific scope: Covers converting data types, normalizing number ranges, encoding categories, aggregating fields, and reshaping data structures |
| Common tasks | Missing value handling, deduplication, encoding, scaling, feature engineering, data splitting, balancing | Removing duplicates, filling missing values, correcting typos, fixing inconsistent formats, and removing outliers | Normalization, standardization, encoding, aggregation, feature engineering, binning, and dimensionality reduction |
| When it happens | Spans the entire data preparation pipeline, from raw data collection through to model-ready output | Comes first, cleaning precedes transformation, so that when data is reshaped, the results are meaningful rather than built on errors | Happens after cleaning, once data is accurate and consistent, transformation reshapes it for modeling |
| Example | Building a full ML pipeline that handles missing ages, encodes contract types, normalizes income, and splits data into training/test sets | A customer database has duplicate email entries, missing phone numbers, and inconsistent date formats, all corrected before any analysis begins | Aggregating total sales per customer, normalizing transaction amounts, and encoding categorical data such as payment method into numeric form |
7. Data Preprocessing Use Cases
Data preprocessing is not limited to any single industry or task, it underpins virtually every application where data drives decisions. Below are six of the most impactful real-world use cases.
7.1 Machine learning model training
Every machine learning model is only as good as the data it learns from. Data preprocessing helps clean, standardize, and structure input data so the model can process it correctly. Common steps include handling missing values, removing outliers, scaling numerical features, encoding categorical variables, and splitting data into training and testing sets.
For example, if a dataset contains location values such as “Chennai,” “CHN,” and “chennai,” preprocessing can standardize them into one consistent value. This ensures the model understands that all three entries refer to the same location, instead of treating them as separate features.
7.2 Data analytics and reporting
Before data can generate reliable business insights, it must be accurate, consistent, and properly structured. In data analytics and reporting, preprocessing helps remove duplicate records, correct inconsistent labels, fill missing values, and prepare datasets for dashboards or BI tools. Clean data improves the reliability of reports and reduces the risk of misleading business decisions.
For example, an HR department analyzing employee turnover may find duplicate employee records, inconsistent department names, and missing tenure values. After preprocessing, the cleaned dataset can produce more accurate dashboards that show which teams have the highest attrition rates.
7.3 Customer segmentation
Customer segmentation depends on clean and well-structured data that reflects real customer behavior. In retail and e-commerce, preprocessing is often used to merge purchase histories, demographic data, and behavioral data from multiple sources. The data is then deduplicated, standardized, and transformed before clustering algorithms group customers into meaningful segments.
A real example is that an e-commerce platform may use RFM analysis, including recency, frequency, and monetary value, to segment customers. Before clustering, raw transaction data is cleaned, missing purchase dates are handled, and spending values are normalized, allowing the model to group customers into high-value, at-risk, and inactive segments.
7.4 Fraud detection
Fraud detection models need high-quality data because fraudulent transactions are usually rare compared with legitimate ones. Preprocessing helps prepare transaction records, customer profiles, device data, and behavioral patterns before analysis. Key steps may include removing duplicates, normalizing transaction amounts, creating time-based features, and balancing imbalanced datasets.
For instance, a digital payment company may preprocess millions of daily transactions before feeding them into a fraud detection model. Transaction amounts can be normalized, duplicate records removed, and time-based features such as transaction hour or frequency within 10 minutes can be created to help the model detect suspicious behavior more accurately.
7.5 Natural language processing
Natural language processing models cannot work directly with raw text. Text data must be cleaned and converted into a structured numerical format before models can understand it. Common preprocessing steps include lowercasing, tokenization, removing stop words, correcting spelling issues, and converting text into vectors or embeddings.
For example, a financial institution building an NLP model to detect suspicious transaction descriptions may preprocess text fields before training. Raw descriptions can be tokenized, lowercased, cleaned of unnecessary filler words, and vectorized so the model can identify unusual language patterns across large volumes of transaction records.
7.6 Computer vision and AI datasets
Computer vision models require consistent, high-quality image data to learn effectively. Preprocessing prepares raw images by resizing them, correcting color formats, removing poor-quality samples, normalizing pixel values, and ensuring labels are accurate. These steps help the model learn from consistent visual inputs instead of noisy or mismatched images.
For example, an AI team training an image classification model may collect images from different cameras, devices, and lighting conditions. Before training, the images can be resized to the same resolution, converted into a consistent color format, and checked for incorrect labels, helping the model recognize objects more reliably.
Powering these use cases in practice, data scientists need a dedicated environment to inspect datasets, clean data, transform features, test preprocessing pipelines, and prepare data before training AI/ML models. FPT AI Factory’s AI Notebook provides exactly that, a fully managed notebook environment built for end-to-end data preparation and model development workflows.

FPT AI Factory’s AI Notebook provides a fully managed notebook environment (Source: FPT AI Factory)
8. Data Preprocessing in Modern ML Workflows
As AI systems grow in complexity, data preprocessing has evolved beyond manual scripts into structured, automated, and scalable workflows. Modern ML teams rely on standardized pipelines and tools to ensure consistency, reproducibility, and efficiency at every stage of data preparation.
8.1 Automated preprocessing pipelines
Manual preprocessing is error-prone and difficult to maintain across multiple experiments. Scikit-learn pipelines define a structured sequence for data processing and modeling, avoiding repeated preprocessing steps every time a team experiments with different models. Pipelines bundle multiple transformers and an estimator into one object, ensuring consistent data transformations across training and testing while reducing code repetition and minimizing errors.
8.2 Reproducible ML workflows
Reproducibility ensures that preprocessing steps can be tracked, rerun, and audited across team members and experiments. DVC (Data Version Control) is best for data and pipeline versioning in ML projects, tightly integrated with Git, while MLflow covers comprehensive ML lifecycle management, including experiment tracking, model versioning, and deployment.
Data versioning ensures that ML models can be recreated using the exact dataset used during training, which is critical when debugging regressions or deploying models to production.
8.3 Containerized preprocessing environments
Inconsistent runtime environments cause preprocessing steps to behave differently across development, staging, and production. Docker allows ML models, dependencies, and environments to be packaged together, eliminating compatibility issues, while Kubernetes orchestrates these containers to enable smooth deployment and rollback of models.
Each pipeline stage, such as data preprocessing and feature engineering, can have its own container, with Kubernetes allowing each stage to scale independently for heavy tasks.
8.4 Data preprocessing for scalable AI systems
When datasets reach the terabyte scale, single-machine preprocessing tools no longer suffice. Apache Spark simplifies large-scale preprocessing with distributed data structures like RDDs and DataFrames, which can handle terabytes of data efficiently, including normalizing numerical features, encoding categorical variables, and extracting text features like TF-IDF in a distributed fashion.
By distributing computation across a cluster of machines, Spark significantly reduces the overhead associated with data preprocessing and model training, addressing common bottlenecks in traditional single-node workflows.
Modern ML teams rely on standardized pipelines and tools to ensure consistency
9. Data Preprocessing Challenges
Data preprocessing is rarely straightforward in production environments. ABelow are the most common challenges teams face when preprocessing data at scale.
- Missing or incomplete data: Real-world datasets often have gaps due to sensor failures, manual errors, or inconsistent storage, and choosing the wrong imputation strategy can introduce bias that distorts model outputs.
- Inconsistent data formats: Inconsistent data across multiple sources can lead to inaccurate insights and poor decision-making.
- Outliers and noisy data: Most ML models are vulnerable to outliers and noisy data, making it critical to identify and rectify flawed observations before model training begins.
- High-dimensional datasets: When dealing with real-world datasets with many attributes, failing to reduce dimensionality can hurt model performance and increase computational resource requirements.
- Data leakage risks: Applying transformations like normalization or encoding before splitting the dataset allows test-set knowledge to leak into training.
- Time-consuming manual preprocessing: Data practitioners dedicate around 80% of their time to data preprocessing and management, making it one of the most significant bottlenecks in the AI development lifecycle.
- Maintaining reproducible preprocessing pipelines: If the dataset used to train a model changes after the time of training, it may be difficult or impossible to reproduce a model.
Running large-scale preprocessing workloads demands serious compute power. FPT AI Factory’s GPU Container provides on-demand, high-performance GPU infrastructure purpose-built for data-intensive preprocessing tasks, enabling teams to process massive datasets, run distributed transformations, and accelerate their entire data preparation pipeline before model training.
Data preprocessing is rarely straightforward in production environments
10. FAQs
10.1. What are the main steps in data preprocessing?
The main steps in data preprocessing usually include collecting raw data, cleaning errors or missing values, removing duplicates, handling outliers, transforming data into a usable format, scaling or normalizing numerical values, encoding categorical variables, and splitting the dataset into training and testing sets. These steps help turn raw data into a structured, consistent, and model-ready dataset.
10.2. Why is data preprocessing important in machine learning?
Data preprocessing is important because raw data often contains noise, missing values, inconsistencies, duplicates, and format issues that can reduce model performance. By improving data quality and converting features into a suitable representation, preprocessing helps machine learning models learn more reliable patterns and produce more accurate predictions.
10.3. Is data preprocessing required for deep learning?
Yes, data preprocessing is still required for deep learning, even though deep learning models can automatically learn complex patterns from large datasets. In practice, deep learning workflows often need steps such as normalization, resizing images, tokenizing text, augmenting data, batching, and preparing training, validation, and test sets so the model can train efficiently and generalize better.
If you are ready to put data preprocessing into practice, the Starter Plan at FPT AI Factory is the fastest way to begin. FPT AI Factory offers a $100 free trial credit program for users to explore the platform. The credit is valid for 30 days and is allocated as follows:
- $10 for GPU Container and $10 for GPU Virtual Machine
- $10 for AI Notebook and $70 for AI Inference and AI Studio
- Access to up to 5M tokens with Llama-3.3 and 20+ state-of-the-art AI models
For enterprises or teams requiring large-scale deployment, custom pipelines, or dedicated support, reach out directly to FPT AI Factory via the official contact form. Our specialists are ready to help you design a data and AI infrastructure tailored to your specific needs.
Data preprocessing is the foundation of every reliable AI and machine learning system. As datasets grow in scale and complexity, building robust and reproducible preprocessing pipelines becomes a core competency for any data-driven team. FPT AI Factory provides the tools and infrastructure to help organizations turn raw data into model-ready inputs with confidence.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Reference articles
What is an AI Data Platform and How Does It Work?
What Is Training Data? Examples, Types & Why It Matters
What Is Data Infrastructure? Key Components and How to Build It


