
What is a data pipeline, and why does it matter for modern data-driven organizations? A data pipeline is a structured system that automatically collects, processes, and delivers data from multiple sources to a target destination – forming the backbone of any scalable analytics or AI strategy. In this article, FPT AI Factory offers definitions, working process, and how to utilize cutting-edge AI and data infrastructure solutions that help businesses optimize data pipelines to unlock the full potential of their data.
1. What is a data pipeline?
A data pipeline is a sequence of automated processes that collect, move, transform, and deliver data between systems. In simple terms, a data pipeline acts like a digital highway that transports raw data from multiple data sources to destinations where it can be analyzed, visualized, or used for AI and machine learning applications.
Raw data alone has little value unless it can be processed into a usable format. Modern data pipelines automate this entire workflow, including data ingestion, transformation, validation, orchestration, and storage. This enables organizations to eliminate manual processing while improving data quality, scalability, and operational efficiency.
A well-built data pipeline takes care of all of that automatically. Organizations use data pipelines to copy or move data from one source to another so it can be stored, used for analytics, or combined with other data. Whether you’re pulling from databases, IoT devices, or SaaS applications, a pipeline ensures your data arrives clean, consistent, and ready to use without manual effort.

A data pipeline is a sequence of automated steps that transfer data
2. How do data pipelines support AI and machine learning?
Data pipelines are the backbone of any serious AI initiative. Without a steady, reliable flow of quality data, even the most sophisticated AI models fall flat. AI pipelines automate the full journey from raw data to actionable insights, including data collection, preprocessing, model training, evaluation, and deployment.
In modern AI systems, data pipelines also support MLOps, enabling organizations to automate model training, deployment, monitoring, and AI inference workflows at scale. As enterprise AI adoption grows, scalable pipelines become critical for managing training data, supporting LLM inference, and deploying production-ready AI applications efficiently.
AI data pipelines go beyond traditional ETL by incorporating machine learning model training, deployment, and continuous learning, making it possible for models to stay accurate and relevant over time.
Data pipelines serve as the crucial infrastructure that feeds fresh enterprise data into AI systems, ensuring models make decisions based on the current state of the business rather than outdated information. For organizations looking to scale AI from experiment to production, a robust data pipeline isn’t optional; it’s essential.

AI pipelines automate the full journey from raw data to actionable insights (Source: FPT AI Factory)
>>> Read more: What Is Data Infrastructure? Key Components and How to Build It
3. How a Data Pipeline Works?
Understanding a data pipeline is easier when you break it down step by step. Each stage plays a specific role in turning raw, scattered data into something your business can act on.
- Data is collected from sources: Data sources may include relational databases, SaaS applications, IoT devices, and APIs. Most pipelines ingest raw data from multiple sources via push mechanisms, API calls, or replication engines that pull data at regular intervals.
- Data is ingested into the system: Once collected, data enters the pipeline. Before data flows into a data repository, it usually undergoes some processing, which includes filtering, masking, and aggregations to ensure appropriate integration and standardization.
- Data is cleaned and transformed: This is where raw data becomes reliable data. Transformations such as sorting, reformatting, deduplication, and validation change the data to meet analysis requirements, removing errors, filling gaps, and ensuring consistency across sources.
- Data is stored or sent to downstream systems: The endpoint of a data pipeline can be a data warehouse, data lake, ai data center or a business intelligence application, wherever the data needs to live for analysis, reporting, or feeding downstream AI models.
- Pipeline is monitored and orchestrated: A pipeline isn’t a set-and-forget system. Data pipelines must include a monitoring component to ensure data integrity, with mechanisms that alert administrators when issues such as network congestion or offline sources occur. Ongoing orchestration keeps everything running smoothly and on schedule.
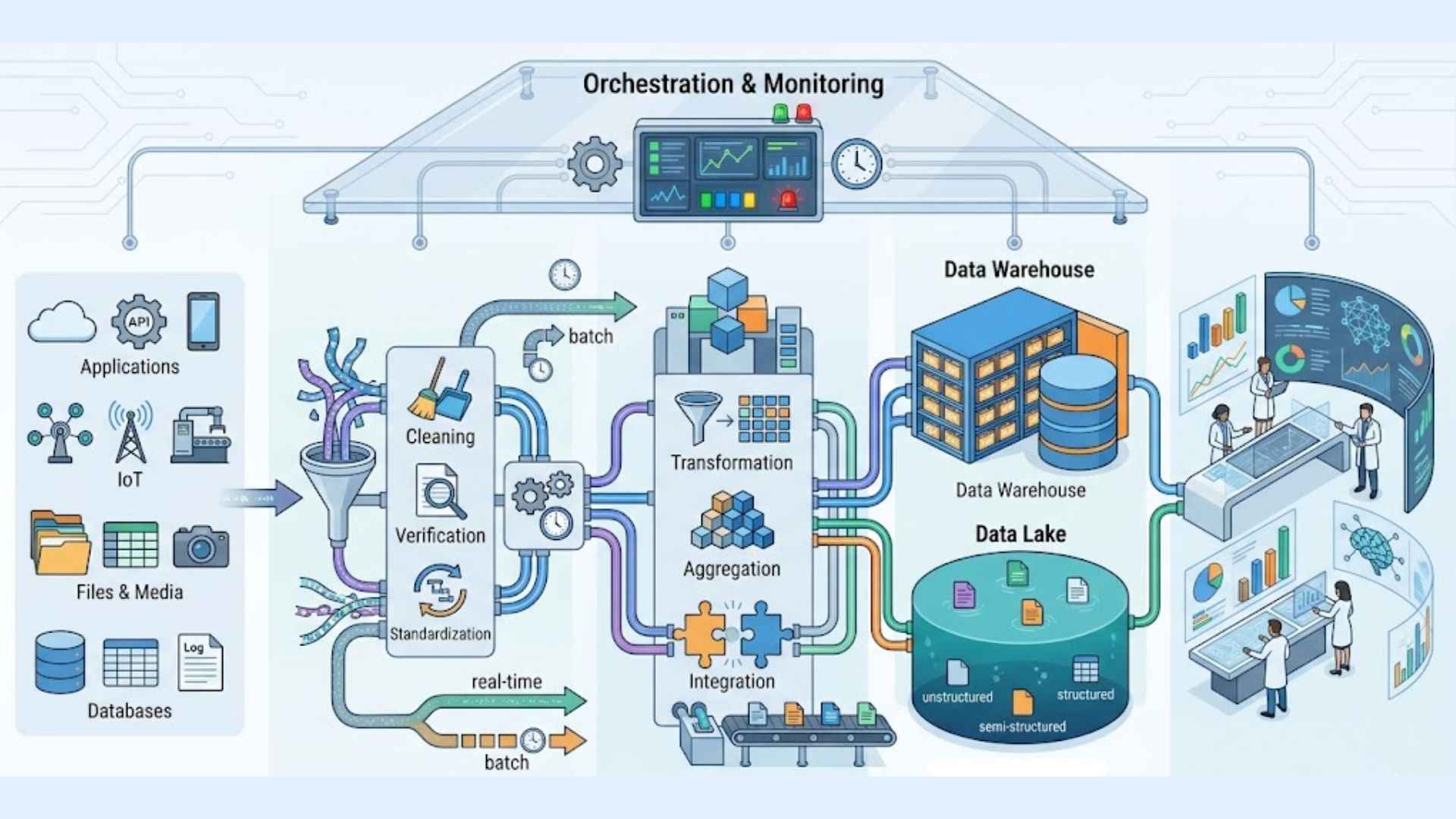
Understanding a data pipeline is easier when you break it down step by step
4. Main components of a data pipeline
A data pipeline isn’t a single tool, it’s a system of interconnected parts, each with a specific job. These components work together to move, transform, and deliver data efficiently. Here’s a breakdown of what makes up a well-built pipeline.
4.1 Data sources
Data sources are the origins of data, encompassing systems like databases, APIs, web apps, IoT devices, CRM platforms, social networks, and file storage solutions where information is initially generated. A single pipeline can pull from dozens of these sources at once, which is exactly what makes it so powerful compared to manual data collection.

Data sources are the origins of data
4.2 Ingestion layer
The ingestion layer extracts and collects data from various sources, either through batch processing, collecting data at scheduled intervals, or streaming, which captures data in real time as it’s generated. This layer acts as the entry gate to your pipeline, making sure data flows consistently and completely.
4.3 Transformation logic
Once data is ingested, it needs to be shaped into something usable. Transformation covers a wide range of operations, filtering, aggregation, standardization, deduplication, validation, and verification to clean, merge, and optimize data to prepare it for analysis and decision-making. This is arguably the most critical step, since poor-quality data leads to poor-quality insights.

Once data is ingested, it needs to be shaped into something usable
4.4 Storage/destination
For unstructured or semi-structured data such as videos, images, and text files, data lakes are often the right fit due to their scalability. For structured data, data warehouses are a common choice, giving analysts a clean, organized place to query and report from. The right storage solution depends on how your team plans to use the data downstream.
4.5 Orchestration and monitoring
Data orchestrators are essential for automating, scheduling, and controlling how data moves through a pipeline, coordinating tasks from ingestion and transformation to storage while ensuring each step runs in the right order and at the appropriate time. On top of that, monitoring and logging capabilities allow teams to track the status and performance of each task within the pipeline, which is valuable for troubleshooting and optimizing performance.
5. Modern data pipeline architecture and tools
Modern data pipeline architecture is no longer limited to basic batch processing or traditional ETL. Many organizations now combine different pipeline patterns, storage layers, orchestration tools, and monitoring systems to support analytics, AI, and real-time applications at scale.
- ELT vs. ETL: ETL transforms data before loading it into a destination, while ELT loads raw data first and transforms it later inside a data warehouse or lakehouse. ELT is common in cloud-native analytics because it supports more flexible transformation and faster ingestion.
- Data lakehouse: A data lakehouse combines the scalability of a data lake with the structure and performance features of a data warehouse. It helps teams store raw, semi-structured, and structured data in one architecture for analytics and AI/ML workloads.
- Streaming-first architectures: These architectures process data continuously instead of waiting for scheduled batch jobs. They are useful for fraud detection, real-time dashboards, system monitoring, and personalization engines.
- Event-driven pipelines: Event-driven pipelines trigger actions when specific events happen, such as a payment transaction, user click, sensor update, or system alert. This helps businesses respond faster to operational changes.
- AI/ML data pipelines: AI/ML pipelines prepare data for model training, fine-tuning, inference, and monitoring. They often include steps for data validation, feature preparation, dataset versioning, model evaluation, and feedback loops.
- Vector database pipelines: These pipelines convert text, images, or documents into embeddings and store them in vector databases for semantic search, recommendation systems, RAG applications, and AI assistants.
- Data observability: Data observability helps teams monitor pipeline health, detect data quality issues, track failures, and understand where data problems occur before they affect dashboards, models, or business decisions.
Common tools and frameworks used in modern data pipelines include Kafka, Spark, Airflow, dbt, Flink, Snowflake, Delta Lake, Databricks, CDC tools, and vector pipeline frameworks. The right toolset depends on data volume, latency requirements, storage strategy, AI/ML use cases, and the level of automation the organization needs.
6. Data pipelines methods
The two most common approaches are batch processing and streaming pipelines. Understanding the difference helps you avoid building more or less than you actually need.
6.1 Batch data pipelines
Batch processing is most effective when data doesn’t need to be processed immediately and can be analyzed periodically. Think of it like doing laundry, you wait until you have a full load, then run everything at once.
Common use cases include generating data backups, loading data into warehouses and lakes via ETL pipelines, running complex business analytics, training machine learning models, and handling periodic financial data aggregation.
The main drawback of batch processing is the delay in obtaining insights, as data must be collected and processed in chunks before results are available. Once data is collected, it might be minutes, hours, or even days before a batch completes, making it best suited for non-time-sensitive use cases like end-of-day reporting. For many organizations, that delay is completely acceptable, and batch pipelines remain a cost-effective, reliable choice.
6.2 Real-time or streaming data pipelines
Streaming data processing handles data in real time as it is produced, instead of waiting for large volumes to build up before processing. Yielding results in real time or near real time, which is important for quick decision-making and responsiveness.
Streaming pipelines are commonly used for system monitoring and alerting, where immediate response is critical. Other strong use cases include fraud detection, live recommendation engines, and real-time dashboards.
These scenarios are significantly more time-sensitive than batch use cases. They rely on near-instant insights to drive effective action, prioritizing low latency above all else. The investment in streaming infrastructure is higher, but for the right use case, the business impact is well worth it.
7. Common Use Cases of Data Pipelines
Data pipelines are the backbone of modern, data-driven operations across virtually every industry. Here are some of the most impactful real-world applications:
- E-commerce personalization: E-commerce companies use recommendation engines that require a robust data pipeline capable of ingesting user activity logs, product catalog information, and customer profiles, processing this raw data through machine learning systems like collaborative filtering to generate personalized recommendations for each user.
- Financial fraud detection: Financial institutions leverage complex algorithms that analyze patterns across millions of transactions, flagging potential fraudulent activities. Banks typically use streaming platforms like Apache Kafka to process transaction data in near real time.
- Healthcare patient monitoring: A healthcare data integration pipeline aggregates information from disparate sources like electronic health records (EHRs), imaging systems, lab management modules, and billing databases. Standardizing incoming data across inconsistent formats and resolving ambiguities in patient identifiers, while prioritizing data privacy and HIPAA compliance at every stage.
- Manufacturing and IoT: In manufacturing or logistics, automated pipelines pull sensor IoT data, inventory levels, and shipment statuses into a unified dashboard. For example, using AWS Data Pipeline to continuously ingest RFID scans and ERP inventory counts so that operations managers can forecast stock needs and prevent shortages.
- Business intelligence and reporting: Finance teams use pipelines to close books faster, reduce errors, and deliver up-to-date reports. For instance, an e-commerce retailer might pipe sales, expenses, and bank feed data into Snowflake for an always-on Profit & Loss dashboard.
- ML model training: Batch pipelines consolidate large volumes of data from multiple sources to train machine learning algorithms, making them an essential step for any organization developing AI models at scale.

Some common use cases of data pipelines
8. Data Pipeline vs. ETL Pipeline
People often use “data pipeline” and “ETL pipeline” interchangeably, but they’re not the same thing. ETL focuses on a structured process that extracts data from multiple sources, transforms it into a usable format, and loads it into a target system like a data warehouse. A data pipeline, by contrast, is a general framework for moving data between systems, often including tasks beyond ETL, such as real-time processing or transferring raw data.
| Criteria | ETL Pipeline | Data Pipeline |
| Scope | Narrow: Covers Extract, Transform, Load as a fixed 3-step sequence | Broad: Encompasses any automated data movement, including ETL as one of many possible patterns |
| Processing style | Primarily batch processing on a scheduled interval | Supports both batch and real-time/streaming processing |
| Flexibility | More structured transformations are predefined and applied before the data reaches its destination | More flexible in terms of data formats and integration capabilities, accommodating various data sources and destinations |
| Typical use cases | Finance: Monthly consolidation of sales data from multiple retail branches into a central data warehouse for P&L reporting | Finance: Real-time fraud detection by streaming credit card transactions within milliseconds |
| Retail: Nightly ETL jobs that pull purchase records from POS systems into BigQuery to generate weekly inventory and demand reports | E-commerce: Continuous ingestion of clickstream data from web logs and user profiles into a recommendation engine | |
| Healthcare: Scheduled batch loads of EHR data into a centralized data warehouse for regulatory reporting under HIPAA compliance | Healthcare: Real-time monitoring pipelines that stream data from wearable devices and ICU sensors into clinical dashboards for immediate patient alerts |
9. Why Data Pipelines Matter?
Organizations that rely on pipelines to collect, move, and integrate data enjoy benefits that apply to IT, executive leadership, and every decision that gets made. Here’s what a well-built pipeline actually delivers:
- Better data quality: Data pipelines automate the cleaning and standardizing of data, eliminating error-prone manual data handling and reducing silos and redundancy. Clean data means more trustworthy reports, dashboards, and AI outputs.
- Faster decision-making: Data pipelines accelerate the time taken to process large volumes of data, allowing businesses to gain insights more quickly, ensuring that critical information is available when it’s needed, enabling more agile responses to market changes.
- Automation at scale: By automating repetitive tasks and reducing the opportunity for human errors, businesses streamline their data management efforts and make informed decisions more quickly and effectively. Teams spend less time wrangling data and more time acting on it.
- Scalability on demand: Data pipelines handle expanding data volumes by scaling to meet increasing demands, distributing tasks across multiple servers or utilizing more GPU computing resources, and can even handle seasonal spikes in data volume.
- Eliminated data silos: Data pipelines help businesses break down information silos and easily move and obtain value from their data in the form of insights and analytics. Everyone in the organization works from the same source of truth.
- Reduced costs: By automating data processes, pipelines streamline data movement, processing, and transformation without requiring constant manual oversight, thereby reducing labor costs. In cloud environments, data pipelines dynamically scale to match workload demands, meaning organizations only pay for the resources they need.
Once a data pipeline has reliably handled ingestion, cleaning, and transformation, organizations need a structured to land that data for the next phase of AI and ML work.
This is where a platform like FPT AI Factory’s Data Hub becomes a natural fit, providing a centralized environment to store, manage, and organize datasets so they’re ready for model training, fine-tuning, and downstream analytics without additional preparation overhead. Once the data pipeline ensures stable data ingestion, cleaning, and transformation, a Data Hub serves as a suitable solution for storing, managing, and organizing datasets to support subsequent AI/ML workflows.

FPT AI Factory’s Data Hub becomes a natural fit, providing a centralized environment (Source: FPT AI Factory)
Now that you have a clearer understanding of what a data pipeline is and how it powers modern data-driven operations, it’s time to put that knowledge into action. Explore our Starter Plan and begin building robust data pipelines today. New users receive a free $100 credit, available immediately upon login with zero setup delay. This credit is valid for 30 days and includes:
- $10 for GPU Container and $10 for GPU Virtual Machine
- $10 for AI Notebook and $70 for AI Inference & AI Studio
- Access to up to 5M tokens with Llama-3.3 and 20+ other state-of-the-art models
For enterprises or organizations looking to scale their data pipeline infrastructure or require custom deployment solutions, reach out to FPT AI Factory directly through the official contact form to receive dedicated support tailored to your operational needs.
In short, understanding what is data pipeline is only the first step. Choosing the right tools and infrastructure to run it efficiently is what truly drives results. Whether you are just getting started or planning a large-scale data pipeline deployment, our specialists are ready to help you design an architecture that fits your goals. Contact FPT AI Factory today through contact form for a personalized consultation!
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Read more:
What is LoRA? A complete beginner’s guide on how it works
What is JupyterHub? Characteristic and practical application
How to use Jupyter Notebook? A comprehensive tutorial
Prompt Engineering vs Fine-tuning: A Guide to better LLM
LoRA vs QLoRA: Efficient Fine-Tuning techniques for LLM


