
What is deep learning, and why is it transforming every industry from healthcare to finance? Deep learning is a subset of machine learning that uses multi-layered neural networks to automatically learn patterns from vast amounts of data, enabling breakthroughs in image recognition, natural language processing, and beyond. At FPT AI Factory, we harness the full potential of deep learning to deliver cutting-edge AI solutions that help organizations solve complex, real-world challenges at scale.
1. What Is Deep Learning?
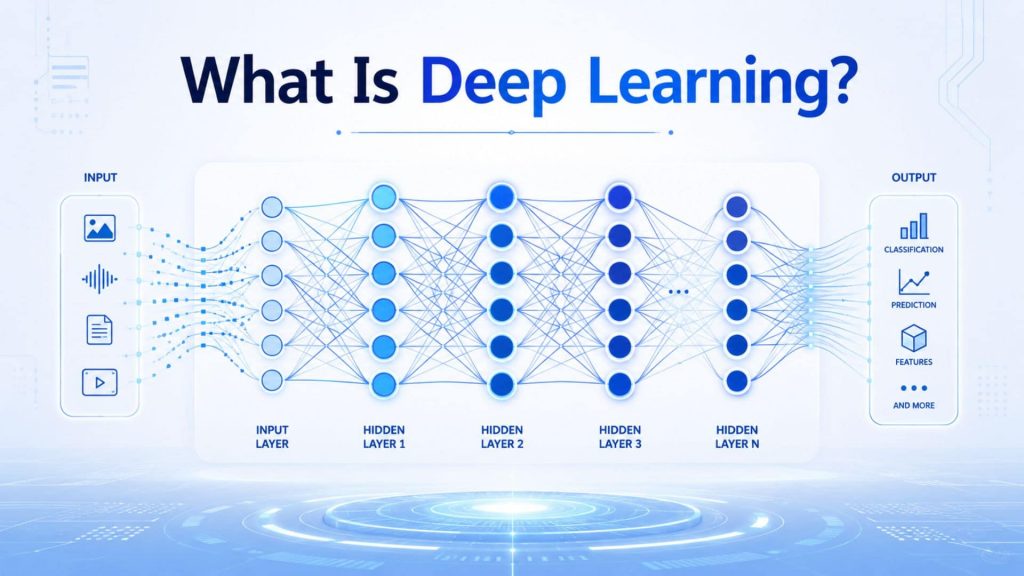
Deep learning is a branch of machine learning that uses multi-layer neural networks to learn patterns directly from raw data. Instead of relying on manually written rules, each layer transforms the input into increasingly abstract features. This makes deep learning especially useful for complex data such as images, speech, text, and video.
For example, Baidu’s Deep Speech system used end-to-end deep learning for speech recognition, replacing many hand-engineered processing stages found in traditional speech systems. The model learned directly from audio data and was designed to handle challenges such as background noise, reverberation, and speaker variation more effectively.
Deep learning is a branch of machine learning that uses multi-layered neural networks
2. How Does Deep Learning Work?
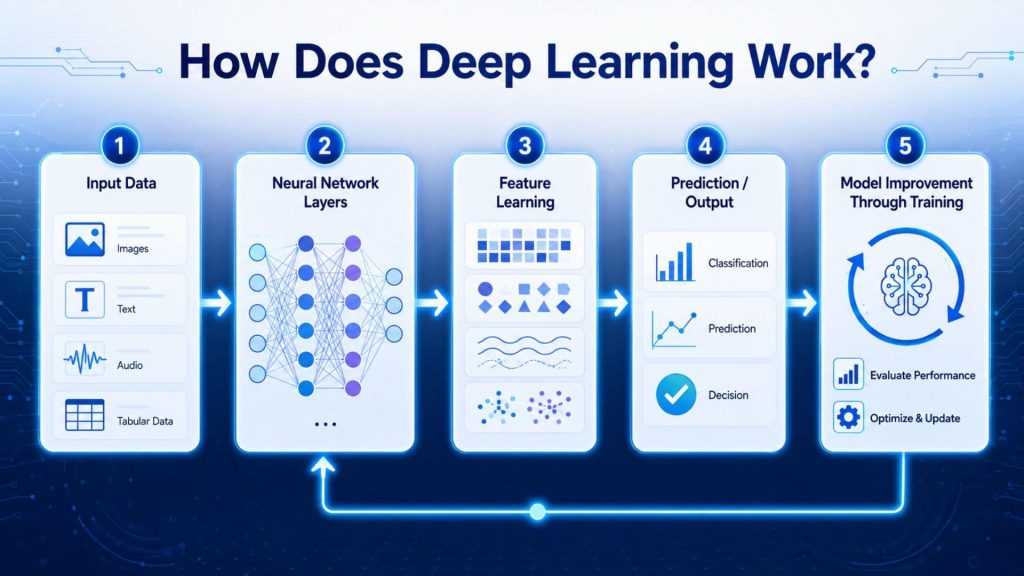
Deep learning works by mimicking how the human brain processes information, through artificial neural networks with multiple successive processing layers. Instead of programming explicit rules, the system learns autonomously from large datasets through repeated training cycles. Each iteration allows the model to refine its predictions, reduce errors, and improve accuracy over time.
2.1 Input data
Input data is the starting point of every deep learning model. It may include images, text, audio, video, or numerical values, depending on the task. Before training, the data is often cleaned, resized, normalized, or standardized so the model can process it more consistently. High-quality and well-prepared input data is essential because poor or inconsistent data can slow training and reduce model performance.
For instance, in TensorFlow’s flower image classification tutorial, the model is trained on about 3,700 flower photos divided into five classes: daisy, dandelion, roses, sunflowers, and tulips. The images are loaded from folders, resized into a consistent format, and split into training and validation sets before being used by the neural network
2.2 Artificial neural networks
Artificial neural networks are computing systems made of connected nodes, or “neurons,” arranged in layers. A typical network includes an input layer, hidden layers, and an output layer. Each node receives information, applies a calculation, and passes the result forward. In deep learning, many layers are stacked together, allowing the model to learn complex relationships that simpler machine learning models may miss.
For example, In TensorFlow’s beginner quickstart, a neural network is built to classify handwritten digit images from the MNIST dataset. The model receives image pixels as input, processes them through neural network layers, and outputs the predicted digit class.
2.3 Hidden layers and feature learning
Hidden layers are where deep learning models learn increasingly abstract features from the input data. In image-related tasks, earlier layers may detect simple visual patterns, while deeper layers can combine those patterns into more meaningful structures. This automatic feature learning is one of the main reasons deep learning can handle complex tasks without heavy manual feature engineering.
In real case, AlexNet, a deep convolutional neural network, was trained on 1.2 million high-resolution images from ImageNet and classified them into 1,000 categories. Its success showed how deeper neural networks could learn useful visual features for large-scale image recognition.
2.4 Model training and optimization
Model training is the process of teaching a neural network to make better predictions. During training, the model makes a prediction, compares it with the correct answer using a loss function, and then uses an optimizer to adjust its weights. Hyperparameters such as learning rate, batch size, and number of epochs strongly affect how efficiently the model learns.
For example, TensorFlow’s custom training walkthrough explains how a training loop feeds examples into a model, measures prediction error, calculates gradients, and applies an optimizer to update trainable variables. This cycle repeats across multiple epochs to improve model performance.
2.5 Backpropagation and weight updates
Backpropagation is the core algorithm that helps neural networks learn from their mistakes. It sends the prediction error backward through the network and uses gradients to determine how much each weight contributed to the loss. The optimizer then updates the weights so the model can reduce future errors. A suitable learning rate is important because very small values slow learning, while overly large values can make training unstable.
For instance, IBM explains backpropagation as a training method that uses the chain rule to calculate how each network weight contributes to the loss. This allows the model to update weights layer by layer and gradually improve its predictions.
2.6 Prediction or output generation
After training, the model enters the inference stage, where it receives new data and generates an output based on the patterns it has learned. The output depends on the task: it may be a class label, a probability score, a translated sentence, generated text, or a numerical prediction. A well-trained model should generalize beyond the training data and make useful predictions on unseen examples.
In TensorFlow’s clothing image classification tutorial, a trained model predicts labels for new test images and returns probability scores for each clothing category. For example, the model can classify an unseen image as an ankle boot, shirt, sneaker, or another clothing class.
2.7 Deep learning architectures
Deep learning architectures define how neural network layers are structured and connected to solve specific tasks. Different architectures are designed for different types of data. For example, CNNs are widely used for image recognition, RNNs and LSTMs are suitable for sequential data, while Transformers are highly effective for language processing. Selecting the right architecture helps improve model accuracy and efficiency.
For example, ChatGPT is built on the Transformer architecture, which was introduced in the paper Attention Is All You Need. Transformers use a self-attention mechanism to capture relationships between words more effectively than many earlier architectures. This design has enabled large language models to perform tasks such as text generation, translation, and question answering at scale.
Deep learning works by mimicking how the human brain processes information
3. Deep Learning vs Machine Learning
Machine learning trains models to make predictions based on data and selected features, while deep learning utilizes neural networks with many layers to learn patterns directly from raw data. The comparison table below breaks down the key differences across nine criteria:
| Criteria | Machine Learning (ML) | Deep Learning (DL) |
| Definition | Algorithms that learn from structured data, with human-guided feature selection. | Multi-layered neural networks that automatically extract features from raw data. |
| Data requirements | Works with small to medium datasets. | Requires very large labeled datasets. |
| Feature engineering | Manual – humans define relevant features. | Automatic – the network learns features itself. |
| Model complexity | Simple (decision trees, SVM, regression). | Complex (CNNs, RNNs, Transformers). |
| Computing resources | Runs on standard CPUs. Trains in minutes to hours. | Requires GPUs/TPUs. Training can take days or weeks. |
| Scalability | Performance plateaus as data grows. | Continues to improve with more data and compute. |
| Accuracy potential | Strong for structured, well-defined tasks. | State-of-the-art for complex, unstructured tasks. |
| Interpretability | High – results are explainable and auditable. | Low – often a “black box,” hard to trace decisions. |
| Best use case | Fraud detection, credit scoring, demand forecasting. | Image recognition, speech recognition, NLP, generative AI. |
| Example | Spam filter in Gmail – classifies emails using engineered features like keywords and sender reputation. | Google Photos – a CNN identifies people and objects across millions of images with near-human accuracy. |
4. Common Types of Deep Learning Models
Deep learning architectures have revolutionized artificial intelligence, offering innovative solutions for complex problems across computer vision, natural language processing, speech recognition, and generative modeling. Each model type below is designed for a specific kind of data and task.
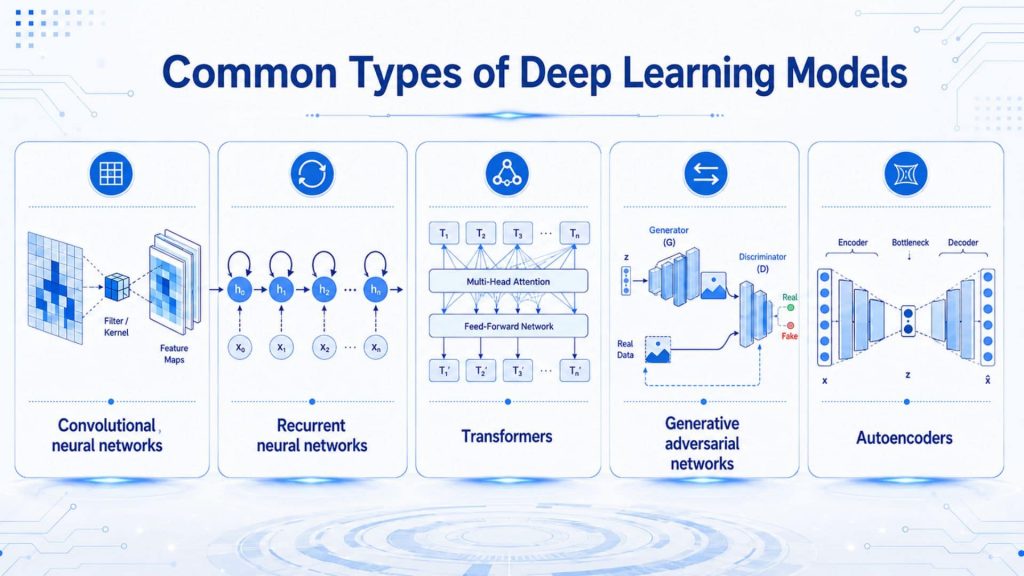
4.1 Convolutional neural networks
CNNs are neural networks designed to process data with grid-like structures, such as images and videos. They work by applying a series of filters to the input. Shallow filters detect simple features like edges and lines, while deeper filters detect more complex patterns like shapes and objects. This hierarchical feature extraction makes CNNs the dominant architecture for computer vision tasks.
Google Photos uses CNNs to automatically recognize people, places, and objects across a user’s photo library. Tesla’s Autopilot system also connects on CNNs to process visual input from cameras and make real-time driving decisions.
4.2 Recurrent neural networks
RNNs are designed to process sequential data such as time series and natural language. They contain internal loops that retain information over time, enabling applications like language modeling and speech recognition. Variants like LSTMs and GRUs were developed to address the vanishing gradient problem in long sequences.
Financial systems apply recurrent learning to identify market patterns over time. Before transformers became dominant, RNN-based architectures powered early versions of speech recognition and machine translation services like Google Translate.
4.3 Transformers
Transformers are neural network architectures built around an attention mechanism that weighs the influence of different words on each other. Unlike RNNs, they process entire sequences in parallel rather than sequentially, significantly reducing training time and enabling much better handling of long-range dependencies.
Transformer-based models like BERT and GPT have set new performance standards across NLP tasks, from machine translation and text summarization to chatbots. GPT-based models power ChatGPT, while BERT underpins Google Search’s contextual understanding of queries.
4.4 Generative adversarial networks
A GAN consists of two competing neural networks: a generator that creates synthetic data, and a discriminator that evaluates whether the output looks real. This adversarial process continues until the generator produces outputs indistinguishable from real data. GANs are widely used for image generation, style transfer, and data augmentation.
Businesses use GANs to generate product images, simulations, and marketing visuals. Early GANs were used to generate realistic human faces, and the technology now underlies tools like DALL-E and Adobe Firefly for AI image synthesis.
4.5 Autoencoders
An autoencoder is a neural network trained to compress input data into a compact lower-dimensional representation (encoding), then reconstruct the original input from it (decoding). It learns to minimize reconstruction error, making it useful for detecting patterns that deviate from the norm.
Autoencoders are widely used in credit card fraud detection. The model is trained on normal transaction data, so it reconstructs legitimate transactions with low error. Fraudulent transactions, which fall outside normal behavior produce a high reconstruction error and are flagged as anomalies.
Deep learning architectures have revolutionized artificial intelligence
5. Benefits of Deep Learning
Deep learning is a transformational AI technique that provides enormous advantages, allowing enterprises to drive innovation across industries. Its ability to learn directly from raw data and improve over time gives it a clear edge over traditional approaches. Below are the key benefits:
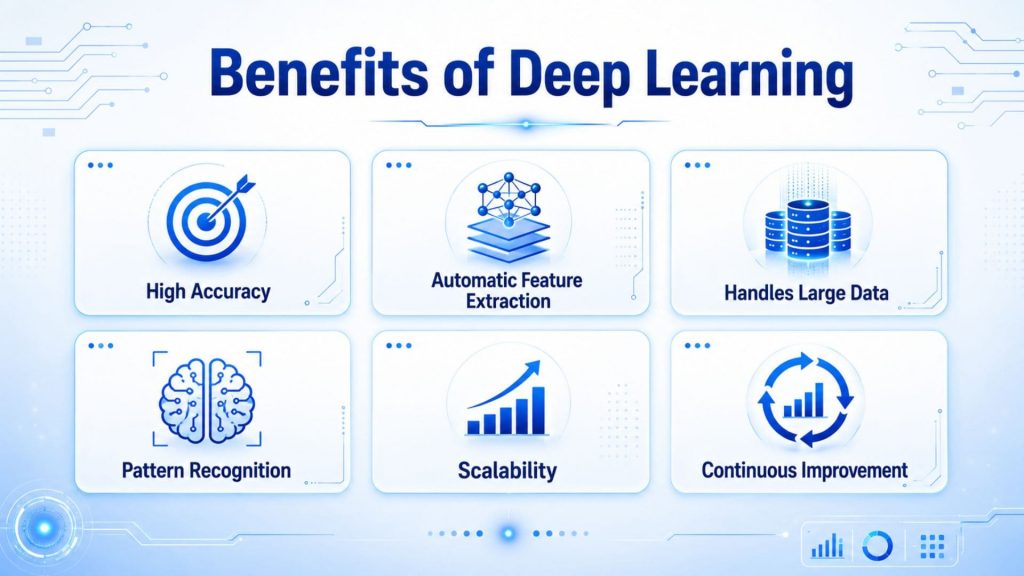
- Learn complex patterns from large datasets. Deep learning models automatically extract relevant features layer by layer, building progressively more complex representations from raw data, something traditional methods cannot achieve at scale.
- Reduces manual feature engineering. Deep learning algorithms can learn features directly from data without human intervention, which is especially valuable in tasks where defining features is inherently difficult, such as image recognition.
- Improves accuracy for image, text, speech, and video tasks. Deep learning has significantly advanced performance across unstructured data types, from object detection and facial recognition in computer vision, to sentiment analysis and contextual understanding in natural language processing, to speech recognition in voice assistants.
- Supports automation for complex decision-making. Deep learning enables systems to make real-time, autonomous decisions based on raw inputs, as seen in self-driving cars that identify objects and predict pedestrian behavior, and in healthcare tools like Google DeepMind that analyze medical scans to detect diseases.
- Scales well with more data and computing power. Deep learning models can scale horizontally across multiple machines or clusters, allowing them to process massive datasets quickly and efficiently, and unlike traditional models, their performance continues to improve as data volume grows.
- Powers advanced AI applications such as generative AI and computer vision: Models like CNNs, RNNs, and Transformers underpin a broad range of cutting-edge applications, from autonomous systems and healthcare diagnostics to generative AI tools that create images, text, and audio at scale.
Deep learning is a transformational AI technique that provides enormous advantages
6. Deep Learning Use Cases
Deep learning has moved well beyond the research lab and is now embedded in products and systems that billions of people interact with daily. From diagnosing diseases to generating creative content, the following use cases illustrate how the technology is reshaping industries at scale.
6.1 Computer vision and image recognition
Deep learning has turned computer vision into a real-time decision engine. Systems can now interpret visual data the way businesses need, shifting from static rule-based recognition to dynamic visual understanding across manufacturing, healthcare, supply chain, and logistics. CNNs power most of these systems by learning to detect visual features directly from raw pixel data.
For example, security and surveillance systems use deep learning models to analyze CCTV footage in real time, detecting theft, traffic violations, and intrusions automatically without manual monitoring.
6.2 Natural language processing
NLP powered by deep learning allows systems to read, understand, and generate human language with context and clarity. Virtual assistants like Siri and Alexa use NLP to interpret spoken commands and respond naturally, while chatbots handle customer support queries and text summarization tools condense long documents into concise outputs.
For instance, PMorgan’s advanced NLP platforms process real-time market data, earnings calls, and regulatory documents simultaneously, extracting insights and spotting warning signs before they appear in financial statements.
6.3 Speech recognition and voice assistants
Deep learning has enabled automatic speech recognition systems to handle accents, background noise, and technical language with high robustness. OpenAI’s Whisper, trained on 680,000 hours of multilingual data, uses an encoder-decoder Transformer architecture to transcribe speech across multiple languages and translate audio into English.
In a real case, OpenAI’s GPT-4o integrates speech recognition with multimodal capabilities, converting speech to text, understanding objects, and interpreting emotions from voice and facial expressions, marking a significant leap in human-machine interaction.
6.4 Fraud detection and risk prediction
Deep learning models for fraud detection can achieve up to 96% accuracy in distinguishing illicit transactions from legitimate ones in real time. Their adaptive learning capabilities allow them to keep pace with evolving deception patterns, something rule-based systems struggle to do.
For example, from 2019 to 2022, PayPal nearly halved its fraud loss rate even as its annual payment volume almost doubled from $712 billion to $1.36 trillion, a result of deep learning algorithms that rapidly adapt to new fraud patterns and protect customers at scale.
6.5 Healthcare and medical imaging
Deep learning is enabling personalized patient care by analyzing medical histories, symptoms, and test results. IBM Watson uses deep learning and NLP to process vast amounts of medical literature and patient data, cross-referencing genetic profiles with the latest oncology research to recommend individualized cancer treatment plans.
For instance, Google DeepMind developed a model capable of detecting over 50 different eye diseases from retinal scans, assisting clinicians in diagnosing conditions such as diabetic retinopathy and macular degeneration at earlier and more treatable stages.
6.6 Generative AI applications
Generative AI models can produce photographs that appear authentic to human observers, generate natural language, create music, and synthesize video, capabilities that are transforming creative industries, product development, and content generation at an unprecedented pace. These models are built on deep learning architectures such as Transformers and GANs.
In a real case, Stripe assembled 50 potential GPT-4 applications to test across its payment platform. After rigorous vetting, 15 prototypes were incorporated into production, including fraud detection, support ticket routing, and summarizing user queries, demonstrating how generative AI models can be integrated directly into enterprise workflows.
For businesses looking to deploy deep learning or generative AI models into their applications without the complexity of managing inference infrastructure, Serverless Inference offers a practical solution, enabling teams to call models via API, scale flexibly with demand, and go to production faster without maintaining their own serving infrastructure.

Serverless Inference offers a practical solution, enabling teams to call models via API (Source: FPT AI Factory)
7. Deep Learning in Modern AI Systems
Deep learning is not just a component of modern AI, it is the foundation on which most of today’s advanced systems are built. From language models that power conversational assistants to the infrastructure that serves billions of predictions per day, deep learning shapes every layer of the AI stack.
7.1 Large language models (LLMs)
A large language model is a neural network trained on a vast amount of text for natural language processing tasks, especially language generation. LLMs can generate, summarize, translate, and parse text across many contexts, and serve as a foundational technology behind modern chatbots. They are built on the Transformer architecture and scaled to hundreds of trillions of parameters.
For example, GitHub Copilot, powered by LLMs, now serves over 20 million developers, a 400% year-over-year increase, and is used by 90% of Fortune 500 companies to autocomplete code, generate functions, and suggest bug fixes.
7.2 Generative AI applications
Recent advances in generative AI, including Vision-Language Models such as GPT-4V and Google Gemini, have brought multimodal learning to the forefront. LLMs now form the core of generative systems capable of producing text, images, audio, and video, ushering in a new generation of AI applications where natural language serves as the universal interface.
For instance, Stripe tested 50 potential GPT-4 applications across its payment platform. After rigorous evaluation, 15 were incorporated into production, spanning fraud detection, customer support summarization, and ticket routing, demonstrating how generative AI models can be deeply embedded into enterprise workflows.
7.3 Multimodal systems
Multimodal models are unified systems capable of processing, understanding, and generating content across multiple data types, within a single neural network architecture. This represents a fundamental shift from fractured, single-task tools toward coherent, unified intelligence that mirrors human cognition.
In a real case, GPT-4o, released in May 2024, was OpenAI’s first unified multimodal model, natively trained to process text, images, and audio, and generate both text and speech within a single neural network, enabling real-time conversational interaction across all modalities simultaneously.
7.4 AI model training infrastructure
Training deep learning models requires fast access to massive datasets, high-bandwidth memory, and dynamic resource allocation that can scale efficiently from small experiments to large production workloads. Modern AI infrastructure relies on GPUs and TPUs, hardware specifically optimized for the matrix-heavy computations at the heart of neural networks.
For example, Google’s infrastructure can connect over one million TPUs across multiple data center sites into a single training cluster, essentially transforming globally distributed hardware into one seamless supercomputer for training large-scale AI models.
7.5 Real-time inference and deployment
Deploying deep learning models for real-time predictions requires meeting strict service level objectives, ensuring reliability, minimal downtime, and optimized infrastructure costs. Large models often demand GPU resources for efficient inference, and underutilization of GPU hardware in production environments remains a key challenge for businesses.
For instance, the global AI inference market reached $97.24 billion in 2024 and is projected to grow at 17.5% annually through 2030, with serverless solutions capturing an increasing share as businesses prioritize faster deployment, lower operational costs, and elastic scaling over fixed infrastructure.
For businesses that need to deploy deep learning or generative AI models into their applications via API, without the complexity of managing inference infrastructure, Serverless Inference offers a production-ready solution with flexible scaling and zero infrastructure overhead, so engineering teams can focus on building products rather than managing servers.
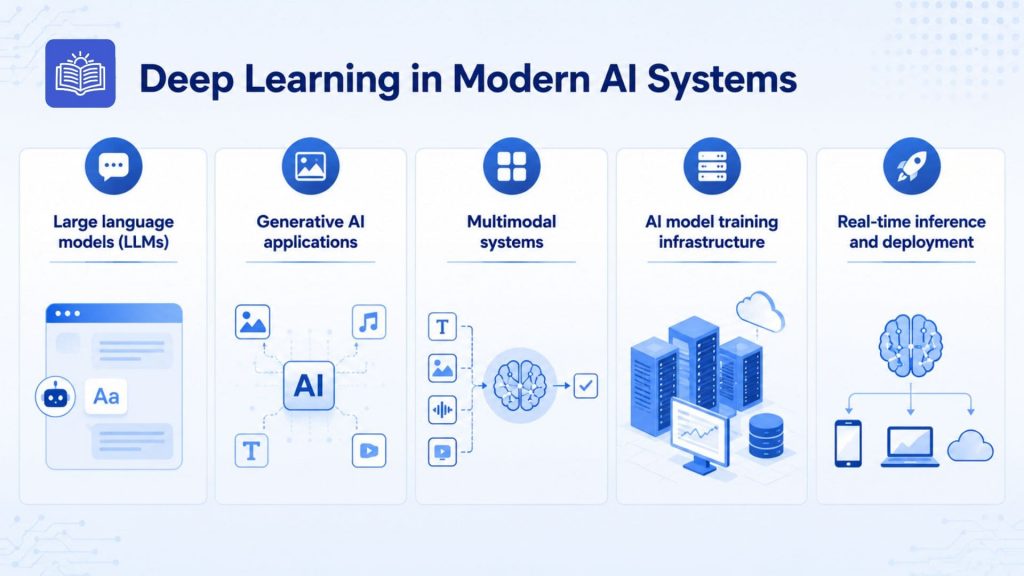
Deep learning is the foundation on which most of today’s advanced systems are built
8. Deep Learning Infrastructure Requirements
Deep learning systems require more than powerful models, they also need a reliable infrastructure layer for data storage, GPU acceleration, model training, deployment, monitoring, and scaling. As models become larger and more complex, businesses must ensure their infrastructure can support high-throughput data pipelines, parallel computation, low-latency inference, and secure model serving across production environments.
Key infrastructure requirements include scalable GPU or TPU resources, high-bandwidth storage, distributed training support, model registry, API-based deployment, observability, and cost optimization. Without these components, teams may face slow training cycles, unstable deployment, underused GPU capacity, and rising operational costs when moving deep learning models from experiments to real-world applications.
To address these challenges, organizations increasingly adopt AI infrastructure platforms that provide integrated compute, training, and deployment capabilities. For example, FPT AI Factory offers services such as GPU Container, GPU Cluster, and GPU Virtual Machine, enabling businesses to access scalable GPU resources, customize foundation models with proprietary data, and streamline the entire AI development lifecycle.
9. Challenges of Deep Learning
Despite its transformative potential, deploying deep learning at enterprise scale is far from straightforward. 87% of data science projects never make it to production, and even when they do, moving a model from lab to full-scale deployment often takes seven to twelve months, slowed by poor data quality, siloed systems, and chronic shortages of skilled AI talent. The following challenges explain why:
- Requires large amounts of quality data: Deep learning models require well-organized, high-quality training data. Without consistent data collection and curation, AI initiatives often stall, and enterprise data is frequently scattered across departments and legacy systems that do not communicate with each other.
- Needs high computing power for training: Training is computationally expensive, requiring specialized hardware such as GPUs and TPUs. Managing multiple GPUs can be costly, and depending on dataset size, training can take days or even months.
- Can be costly to train and deploy: Beyond training, maintaining low latency and responsiveness across enterprise-sized systems after deployment adds significant engineering and infrastructure costs, requiring careful decisions around cloud, on-premise, or hybrid architecture.
- May be difficult to interpret or explain: Neural networks used in deep learning are among the hardest models for humans to understand, a growing concern in regulated industries such as finance and healthcare, where auditability and accountability are required.
- Requires careful model monitoring and tuning: Without visibility into how a model makes decisions, drift becomes harder to detect, outputs vary unexpectedly, and organizations struggle to identify root causes when something goes wrong.
- Needs skilled AI/ML teams and infrastructure: Implementing AI at enterprise scale requires specialized skills, and there is currently a global talent shortage in this area, making it difficult for many organizations to move beyond experimentation into sustained production deployment.
For teams running large-scale model training, fine-tuning, or compute-intensive workloads, GPU Virtual Machine provides on-demand, high-performance GPU compute purpose-built for deep learning, without the overhead of managing physical hardware.

Moving a model from lab to full-scale deployment often takes seven to twelve months
10. FAQs
10.1. What is the difference between AI, machine learning, and deep learning?
Artificial intelligence (AI) is the broad field of creating systems that can mimic human intelligence, such as problem-solving or language understanding. Machine learning (ML) is a subset of AI where computers learn patterns from data instead of being directly programmed. Deep learning (DL) is a more advanced subset of machine learning that uses multilayer neural networks to process huge amounts of complex data like images, audio, and text
10.2. Is deep learning the same as neural networks?
Not exactly. Deep learning is based on neural networks, but it specifically refers to neural networks with many layers, often called “deep neural networks.” A regular neural network may only have one or two hidden layers, while deep learning models can contain dozens or even hundreds of layers to learn more complex patterns from data automatically.
10.3. Why does deep learning need GPUs?
Deep learning requires GPUs because training neural networks involves performing millions or even billions of calculations simultaneously. GPUs are designed for parallel processing, meaning they can handle many calculations at the same time much faster than CPUs. This greatly speeds up tasks such as image recognition, natural language processing, and AI model training.
10.4. Is ChatGPT based on deep learning?
Yes. ChatGPT is based on deep learning technology, specifically a type of neural network architecture called a Transformer. It is trained on massive amounts of text data using deep learning techniques so it can understand language patterns and generate human-like responses. The “GPT” in ChatGPT stands for “Generative Pre-trained Transformer.”
If you are ready to put sovereign AI into practice, explore the Starter Plan at FPT AI Factory today. FPT AI Factory offers a $100 free trial credit program for users, including credits for GPU Container, GPU Virtual Machine, AI Notebook, AI Inference, and AI Studio, along with access to Llama-3.3 and more than 20 advanced AI models.
For enterprises requiring customization or large-scale sovereign AI deployment, FPT AI Factory also offers dedicated consultation and tailored infrastructure solutions to support compliance, governance, and operational scalability.
In conclusion, understanding what is deep learning is essential for businesses and developers looking to unlock the full potential of modern AI technologies. To turn these capabilities into real-world applications, platforms like FPT AI Factory provide the infrastructure, tools, and sovereign AI ecosystem needed to build, train, and deploy AI solutions efficiently and securely.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Reference Articles
What Is a Pre-Trained Model? Benefits & Use Cases
PyTorch vs TensorFlow: Which One Is Better for You?
What Is AI Infrastructure? Key Components and How It Works


