
Transformer architecture in AI has become the foundation of modern deep learning models, especially in natural language processing and generative AI. Understanding how this architecture works helps teams design, train, and deploy AI systems more effectively with platforms like FPT AI Factory.
1. What is a transformer architecture in AI?
A transformer architecture is a neural network architecture designed to handle sequential data by focusing on relationships between elements rather than processing them step by step.
Instead of reading input in order, like traditional models, transformers look at the entire sequence at once and decide which parts matter most. This shift may sound subtle, but it fundamentally changes how models understand context.
Earlier approaches like RNNs and LSTMs struggled with:
- Long sequences where important information appears far apart
- Slow training due to sequential processing
- Difficulty scaling to large datasets
Transformers address these limitations by:
- Processing tokens in parallel
- Capturing long-range dependencies more effectively
- Scaling well with modern compute infrastructure
This is why they’ve become the default architecture behind most state-of-the-art AI models today.
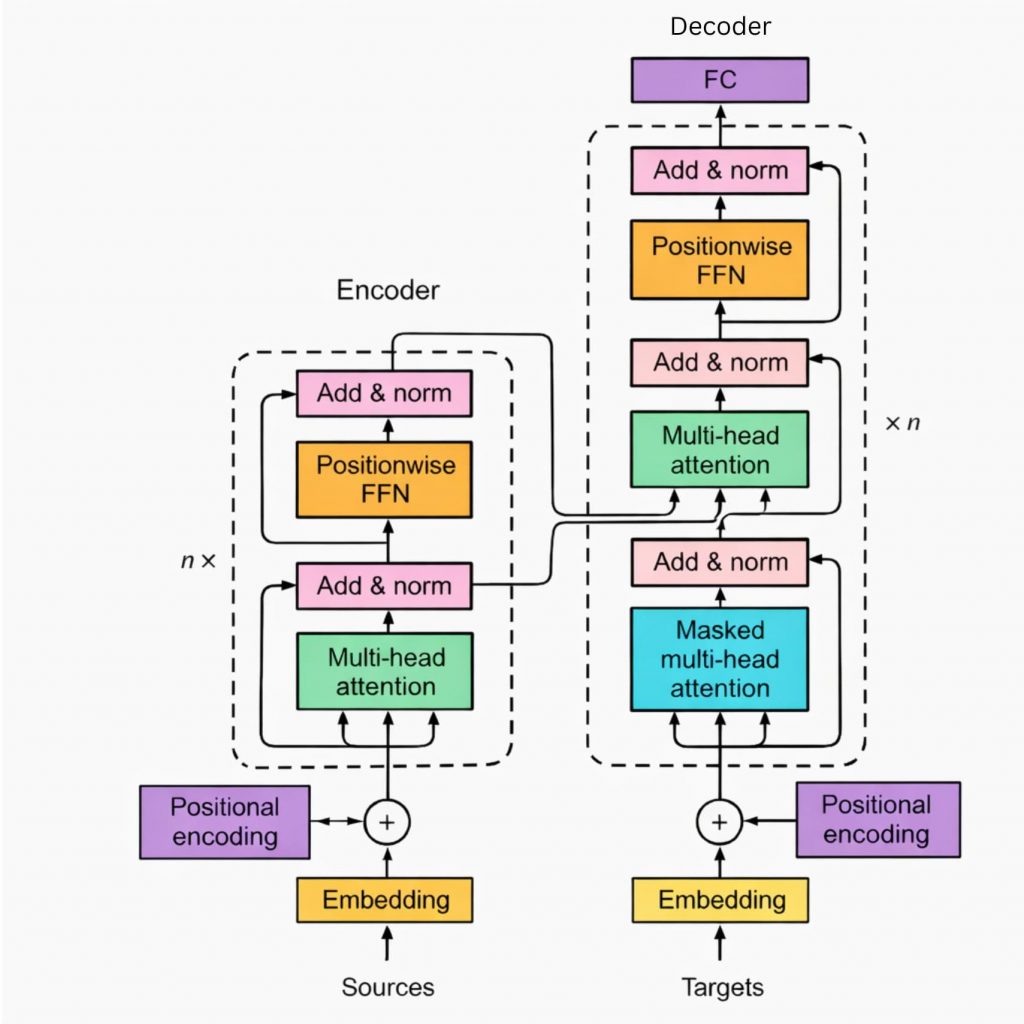
The transformer architecture consists of many steps from encoder to decoder
2. Why are transformers important in deep learning?
Transformers matter because they unlocked both performance and scalability at the same time, something previous architectures couldn’t achieve together. In practice, they are now used across a wide range of domains:
- Natural language processing (translation, summarization, chat)
- Generative AI (text, code, multimodal content)
- Search and recommendation systems
What makes them particularly important is not just accuracy, but how they handle context. Instead of compressing information into a fixed-size representation, transformers dynamically adjust what they pay attention to. It offers a better understanding of meaning across entire documents with more coherent text generation. Overall, it improves adaptability across business and organizational tasks.
Equally important, transformers are well-suited for GPU-based training, which allows teams to scale models to billions of parameters, a key factor behind the rise of large language models.
3. What is the core architecture of a transformer?
At a high level, transformer architecture is built around a stack of layers that repeatedly refine how input data is represented. The original design includes two main parts:
- An encoder (to process input)
- A decoder (to generate output)
However, many modern models use only one side depending on the task. The architecture is composed of several key building blocks working together:
| Component | Role |
| Embedding layer | Converts tokens into numerical vectors |
| Positional encoding | Injects information about token order |
| Attention layers | Learn relationships between tokens |
| Feed-forward networks | Transform representations after attention |
Before any learning happens, raw input (like text) is converted into embeddings. Since transformers don’t inherently understand order, positional encoding is added to preserve sequence structure. From there, the model repeatedly applies attention and transformation layers, gradually building a richer understanding of the input.
4. The main components of transformer architecture
4.1. Multi-head attention
Instead of relying on a single attention mechanism, transformers use multiple attention heads running in parallel. Each head focuses on different aspects of the input, allowing the model to capture a wider range of relationships within the data. As a result, the model can learn more nuanced patterns and build richer representations, rather than depending on a single perspective.
4.2. Feed-forward networks
After the attention step, each token is passed through a feed-forward neural network to further transform the learned representation. This stage applies non-linear transformations, which helps the model capture more complex patterns in the data. Even though the processing happens independently for each token, it builds on the contextual information already introduced by the attention mechanism.
4.3. Residual connections
Residual connections play an important role in maintaining information as it flows through multiple layers of the network. Without them, deeper models tend to become harder to train and may lose important signals over time. By allowing the original input to pass through alongside transformed outputs, residual connections help preserve information and improve gradient flow, making training more stable.
4.4. Layer normalization
Layer normalization is used to keep the values within each layer stable during training. By normalizing activations, it helps the model converge faster and reduces sensitivity to initialization. This results in more stable training overall, especially when working with deep transformer architectures.
Together, these components form a repeating block that can be stacked many times, allowing transformers to scale in depth and complexity.
5. What are the requirements of transformers?
Despite their strengths, transformers are not lightweight models. They come with practical constraints that need to be considered early.
- Compute requirements: Training large transformer models requires significant GPU resources. This includes high memory capacity, parallel compute capabilities, and long training times for large datasets
- Data dependency: Transformers generally perform better with large, high-quality datasets. Without sufficient data, models may underperform and generalization can be limited
- Infrastructure considerations: To handle these challenges, teams often need scalable GPU environments, efficient workload orchestration, and flexible deployment options
With platforms like FPT AI Factory, these requirements can be addressed more effectively, enabling teams to streamline model training, simplify deployment, and adapt resources based on real-world usage without overprovisioning.
GPU Virtual Machines provide flexible GPU resources with full control over compute, OS, and AI workloads, suitable for training, testing, and high-performance development. GPU Containers, on the other hand, enable faster setup and easier portability, making them ideal for maintaining consistent environments across development and production.
Together, these options allow teams to scale GPU usage efficiently without managing physical infrastructure, so they can focus on building and deploying AI applications while FPT AI Factory handles the underlying compute.

FPT AI Factory offers GPU infrastructure to support business projects
Transformers have become the foundation of modern AI because they fundamentally change how models understand relationships in data. While the architecture itself is conceptually elegant, deploying it effectively requires careful consideration of compute, data, and system design. With the right infrastructure in place, such as GPU-powered environments from FPT AI Factory, teams can move beyond theory and start building scalable, production-ready AI systems.
New users can receive $100 in credits and start using the service immediately after logging in. For enterprises with customization needs or large-scale deployment requirements, please contact FPT AI Factory through the contact form for personalized consultation.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more articles:


