
What is pipeline in machine learning and why has it become essential for modern AI development? Machine learning pipelines help organizations automate workflows, improve model consistency, and accelerate deployment across production environments. A FPT AI Factory, businesses can streamline AI development with integrated tools for training, monitoring, fine-tuning, and scalable GPU infrastructure.
1. What is Pipeline in Machine Learning?
A machine learning pipeline (ML pipeline) is a structured workflow that automates the process of building and managing machine learning models. It connects key stages such as data preparation, model training, evaluation, deployment, and monitoring into one continuous and repeatable system. By organizing these steps in a clear workflow, ML pipelines reduce manual work, improve coordination, and help teams build AI applications faster, more consistently, and more reliably in real-world environments.
For example, ride-hailing platforms like Uber use machine learning pipelines to predict trip demand and optimize driver allocation. The pipeline continuously processes location data, traffic conditions, weather information, and user booking patterns to train prediction models. These models are then updated regularly to improve estimated arrival times, dynamic pricing, and route recommendations in real time.

ML pipelines automate the full AI workflow from data processing to real-time prediction and deployment
>>> Explore: What is a Data Pipeline? Types, Benefits and Use Cases
2. Why ML Pipelining is important?
Machine learning systems today are rarely simple. They involve multiple stages such as data collection, preprocessing, training, evaluation, and deployment, all of which need to work together in a stable and repeatable way. When these steps are handled manually, it becomes easy for inconsistencies and errors to appear, especially as projects scale.
This is where ML pipelining becomes a key part of the workflow. It provides a structured way to organize and connect all stages of the machine learning lifecycle into a single automated process, making the system easier to manage and more reliable in production.
In practice, ML pipelines are widely used because they bring several important advantages:
- The entire workflow becomes more consistent across different experiments and teams
- Repetitive tasks are handled automatically instead of being done manually every time
- Models can be reproduced more reliably since the same steps are always followed
- Experimentation becomes faster, allowing quicker improvements and iterations
- Development, deployment, and monitoring are linked into one continuous flow
- The overall system becomes more stable by reducing dependency on manual configuration
>>> Explore: What Is AI Infrastructure? Key Components and How It Works
3. How Does a Machine Learning Pipeline Work?
A machine learning pipeline works by structuring the entire ML workflow into a connected and automated sequence of steps. Instead of handling each task separately, the pipeline ensures that data flows continuously from raw input to final prediction in a controlled and repeatable way. Each stage processes the output of the previous step, which helps maintain consistency and reduces manual intervention.
In practice, the pipeline begins with data ingestion, then moves through data preprocessing, feature engineering, model training, and evaluation before reaching deployment. Once the model is deployed, the pipeline often continues to operate in a loop through monitoring and retraining, ensuring the system adapts to new data and maintains performance over time.
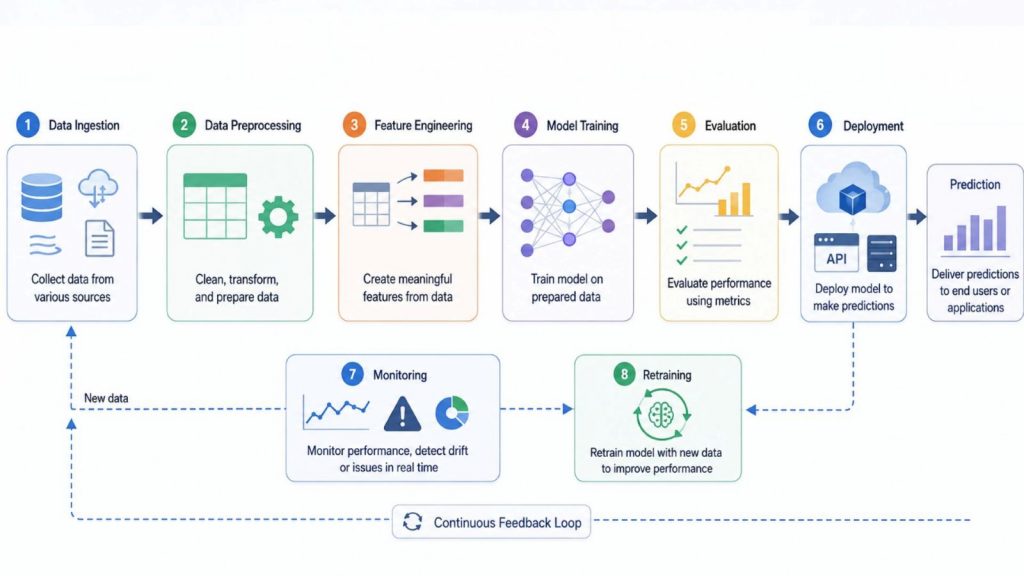
Machine learning pipelines automate connected workflows from data to prediction and continuous improvement.
>>> Explore: What is AI inference? How it works, types, and use cases
4. Key Stages of a Machine Learning Pipeline
A machine learning pipeline is typically structured as a sequence of stages that gradually transform raw data into a trained, evaluated, and production-ready model. Each stage has a specific role, and together they ensure the workflow is consistent, repeatable, and scalable.
4.1. Data collection and ingestion
This stage focuses on gathering data from multiple sources and bringing it into a centralized system, which is a key part of a broader data infrastructure that supports machine learning workflows. Data can come from internal systems such as business records or logs, as well as external sources like APIs, web data, or third-party datasets. In many cases, this process runs continuously since new data is constantly generated.

Data flows from multiple sources into a centralized system
4.2. Data processing
Once collected, the data needs to be cleaned and prepared before it can be used for modeling. This includes handling missing values, removing noise, fixing inconsistencies, and transforming raw inputs into a structured format. Exploratory analysis is often done here to better understand patterns and data quality, which helps guide later modeling decisions.
4.3. Feature engineering
At this stage, raw data is transformed into meaningful features that better represent the problem for the model. This may involve selecting the most relevant variables, creating new features, or reducing unnecessary ones. The quality of feature engineering directly affects how well the model can learn patterns from the data.
4.4. Model training
After the dataset is prepared, a suitable machine learning algorithm is selected and trained using the available data, including training data. During this process, the model learns patterns and relationships within the dataset so it can generate accurate predictions on unseen data. Depending on the complexity of the use case and performance requirements, different algorithms may be evaluated and tested to find the most effective approach.
4.5. Model evaluation
Once training is completed, the model is tested using evaluation metrics to measure its performance. This step helps determine whether the model is accurate, stable, and suitable for real-world deployment. If performance is not satisfactory, earlier stages such as feature engineering or model selection may need to be revisited.
4.6. Development, monitoring and retraining
Once a machine learning model is deployed into production, its lifecycle continues as new data is constantly generated in real-world environments. At this stage, the pipeline ensures the model remains accurate, stable, and aligned with changing data patterns over time.
Monitoring focuses on tracking key indicators such as model performance, prediction quality, latency, system health, and data drift. These signals help identify early signs of degradation or abnormal behavior before they affect business outcomes.
Retraining is the process of updating the model using new data to maintain accuracy as real-world patterns evolve. This continuous monitoring and retraining loop is a key part of the ML lifecycle, ensuring long-term reliability in production systems.
Platforms like FPT AI Studio help streamline these stages in a unified environment, from managing training datasets with Data Hub and experimenting in AI Notebook, to running no-code Model Fine-Tuning with built-in pipeline orchestration across multi-GPU infrastructure.

Continuous monitoring and retraining ensure deployed ML models stay accurate and reliable as real-world data evolves
5. Benefits of Machine Learning pipeline
Machine learning pipelines provide tangible operational and business advantages by organizing complex workflows into modular, reusable, and automated components. This allows organizations to accelerate AI development while maintaining control, consistency, and scalability across multiple projects. Unlike traditional workflows that require manual coordination between stages, pipelines optimize the entire lifecycle from experimentation to production deployment.
Key benefits include:
- Faster time-to-production by automating end-to-end ML workflows
- Improved maintainability through modular and well-structured pipeline stages
- Better resource efficiency by reusing shared components across multiple models
- Flexibility to integrate different tools, frameworks, and programming languages
- High reusability of common steps such as data preprocessing and feature engineering
- Easier scalability when handling larger datasets, models, and infrastructure
- Increased production stability with reduced human intervention and fewer errors
6. Managing ML Pipelines with MLOps
As machine learning systems move into production, building a pipeline is no longer enough. The focus shifts from just developing models to reliably operating, updating, and scaling them in real-world environments. This is where MLOps becomes essential, as it provides the practices and infrastructure needed to manage ML systems in a production-ready way.
6.1. Why MLOps Matters for Production ML
MLOps becomes important when machine learning moves from experimentation in notebooks to real production environments. In real-world use cases, models that perform well during development can quickly lose accuracy once exposed to live data, changing user behavior, and evolving system conditions. MLOps helps bridge this gap by bringing structure and automation to the entire machine learning lifecycle.
Instead of handling each stage separately, MLOps connects training, deployment, monitoring, and updates into a continuous workflow. It helps reduce model performance degradation through data tracking, improves reproducibility with version control, and enhances collaboration between data science and engineering teams. It also enables organizations to scale multiple models efficiently without increasing operational complexity.
>>> Explore: What Is GPU Computing and How Does It Work? A Complete Guide
6.2. Pipeline Automation and Orchestration
Pipeline automation and orchestration work together to manage how data and code move through a machine learning system from start to finish. Automation focuses on executing individual tasks automatically, while orchestration connects and coordinates the entire workflow into a unified process.
Automation removes manual effort from repetitive steps such as data processing, model training, and evaluation. These tasks are triggered automatically to ensure consistent execution without human intervention. Orchestration, on the other hand, controls the structure of the pipeline by defining the order of execution and managing dependencies between stages. It ensures each step only runs when the required inputs are ready, while also supporting scheduling, retries, and system-wide monitoring.
Together, they make ML pipelines more stable, scalable, and easier to operate in real-world production environments, especially when handling complex workflows and large-scale systems.
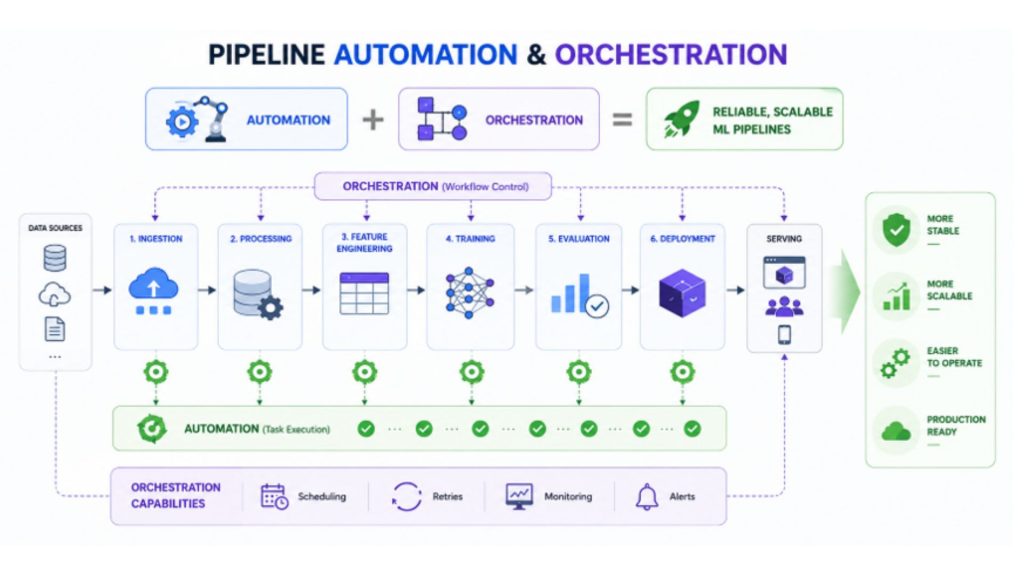
Automating tasks, orchestrating workflows, powering reliable ML pipelines
>>> Explore: The Importance of Cloud Computing in DevOps: Detailed Guide
6.3. Pipeline Monitoring and Retraining
In production machine learning systems, monitoring and retraining are not treated as isolated steps but instead operate as part of a continuous workflow that ensures long-term stability. Rather than evaluating models only after deployment, systems continuously observe model behavior in real-world conditions where data distributions and user behavior can change over time.
Monitoring is typically implemented through dashboards and alert systems that track signals such as data drift, prediction accuracy, latency, throughput, and overall system health. These systems help detect performance degradation or anomalies early, allowing teams to respond before they impact production outcomes.
When issues or data shifts are detected, retraining is triggered through automated or semi-automated pipelines. These pipelines reuse existing training configurations and incorporate new data to refresh the model without disrupting ongoing services.
>>> Explore: MLOps vs DevOps: Key Differences, Use Cases & How to Choose
7. Use cases of a machine learning pipeline
Machine learning pipelines are widely used because they break complex workflows into modular stages that are easier to manage, update, and scale. Instead of a single monolithic system, each step can be developed independently, making the overall process more flexible and maintainable for real-world and evolving requirements.
7.1. Natural Language Processing
In natural language processing, pipelines are often used to handle multi-step text processing workflows. For example, in a Twitter sentiment analysis system, raw tweets are first collected through data ingestion, then cleaned by removing noise such as punctuation, special characters, and unnecessary whitespace. After that, the text is tokenized and normalized before being passed into a sentiment classification model.
For instance, ride-hailing apps like Grab or Uber using NLP pipelines to process user feedback from reviews and support tickets. If many users report issues like “driver not arriving” or “payment failed,” the system can quickly detect and group these complaints, helping teams identify problems early and fix them faster.

NLP pipelines process user text data to detect sentiment and quickly identify real-world issues from customer feedback.
7.2. Customer churn prediction
Machine learning pipelines are commonly used in customer retention systems to predict churn behavior. Data from user activity logs, subscription history, and engagement metrics is processed and transformed into meaningful features for modeling.
For example, a subscription-based gym app can use a pipeline to detect members who are about to cancel their membership. If the system notices a user hasn’t checked in for weeks, stops booking classes, or reduces app activity, it can flag them early so the gym can send discounts or personalized offers to encourage them to stay.
7.3. Fraud detection
In fraud detection systems, pipelines process large volumes of transactional data in near real time to identify unusual or risky behavior. Each transaction goes through multiple stages such as validation, feature extraction, and anomaly detection before a final decision is made.
A real-world use case can be seen in PayPal’s fraud detection system, where every payment is continuously monitored for abnormal patterns. If a transaction suddenly involves a high amount, a new device, or an unusual location compared to the user’s normal behavior, the system can automatically flag it for review or temporarily hold it for verification. This approach helps prevent unauthorized transactions and strengthens security for users on the platform.
7.4. Recommendation engines
Recommendation systems rely heavily on pipelines to continuously process user interactions and generate personalized suggestions. Data from clicks, views, and purchase history is collected and transformed into user-item features, which are then used to train ranking or recommendation models.
In TikTok’s recommendation system, user behavior is analyzed in real time to determine which videos should appear next on the feed. When a user watches, likes, shares, or skips certain videos, the system continuously updates their preference profile and adjusts recommendations to prioritize similar content. This pipeline-based approach enables TikTok to deliver highly personalized feeds without needing to manually redesign the recommendation logic every time new user data is generated.
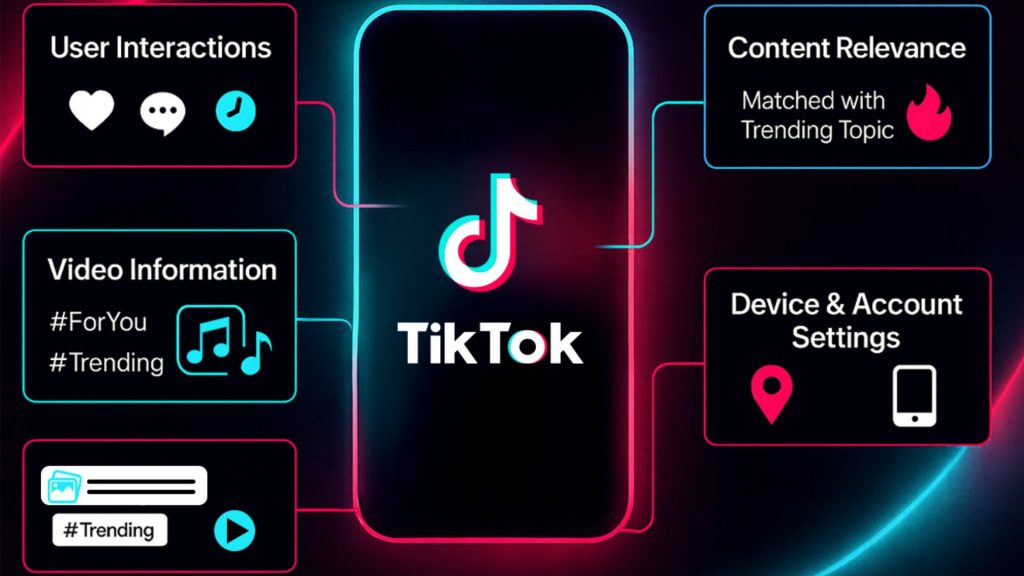
Recommendation pipelines use user behavior data to generate personalized suggestions
7.5. Predictive maintenance
In predictive maintenance, machine learning pipelines are used to monitor equipment health by processing sensor data over time. Signals such as temperature, vibration, and pressure are analyzed to detect early signs of potential failure.
In real-world manufacturing environments, companies like Siemens use predictive maintenance systems to monitor industrial machines and production lines. When the system detects abnormal vibration patterns or rising temperature levels that differ from normal operating conditions, it can predict a possible breakdown and trigger maintenance scheduling in advance. This helps reduce unexpected downtime, lower repair costs, and improve overall production efficiency.
8. Common challenges when building ML Pipelines
Building machine learning pipelines requires automating multiple stages such as data ingestion, preprocessing, training, and deployment. While this structure improves efficiency and scalability, it also introduces several challenges across data, infrastructure, deployment, and governance that teams need to carefully manage in real-world systems.
8.1. Data quality
One of the most critical challenges is maintaining high-quality data. In real-world systems, data often comes from multiple sources and may include missing values, duplicates, inconsistent formats, or noise. In addition, data can continuously change over time, which leads to data drift or concept drift and gradually reduces model performance if not properly handled.
8.2. Feature engineering complexity
Feature engineering is often complex because it requires transforming raw data into meaningful inputs for the model. A common issue is feature inconsistency between training and production environments, also known as training-serving skew. When feature calculations are not aligned, the model may behave differently in real-world usage compared to training.
Turning raw data into reliable features for real-world ML systems.
8.3. Model selection and tuning
Selecting the right model and tuning it for optimal performance is rarely a one-step process. Different algorithms can produce very different results depending on the dataset, and hyperparameter tuning often requires multiple experiments. Without a well-structured pipeline, this process becomes difficult to track, reproduce, and optimize.
8.4. Data privacy and security
Machine learning pipelines often handle sensitive or regulated data, which requires strict security and governance controls. Organizations must ensure proper data access management, secure storage, and compliance with privacy regulations. This adds additional constraints when designing end-to-end ML workflows.
8.5. Model interpretability and explainability
Many advanced machine learning models operate as black boxes, making it difficult to explain how predictions are generated. This lack of transparency becomes a challenge in regulated industries such as finance or healthcare, where explainability and accountability are required for decision-making.
8.6. Deployment and scalability of models
Deploying models into production introduces challenges related to environment mismatch, latency requirements, and system stability. In addition, as data volume and user traffic grow, pipelines must be able to scale efficiently. Without proper design, maintaining performance and reliability in production becomes difficult.
Scaling ML models from development to reliable real-world deployment
>>> Explore: What is AI governance? Principles, framework and practices
9. Frequently Asked Questions
9.1. What is the difference between a data pipeline and an ML pipeline?
A data pipeline is mainly responsible for collecting, transforming, and moving raw data into a format that can be stored or used for analytics, such as in ETL processes. On the other hand, a machine learning pipeline builds on top of this by using the prepared data to train, evaluate, deploy, and monitor ML models. In simple terms, data pipelines focus on preparing and delivering data, while ML pipelines turn that data into trained models that can generate predictions and support decision-making.
9.2. Can ML pipelines handle both structured and unstructured data?
Yes, ML pipelines are designed to work with both structured data such as tables and databases, as well as unstructured data like text, images, audio, or video. However, unstructured data usually requires more complex preprocessing steps such as text tokenization, image normalization, or feature extraction before it can be used for training models.
9.3. How do ML pipelines enable predictive analytics?
ML pipelines enable predictive analytics by automating the process of turning raw data into trained models that can generate forecasts or predictions. Each stage of the pipeline, from data preparation to model deployment, ensures that insights are generated in a consistent and scalable way, allowing organizations to make data-driven decisions based on future trends rather than just historical data.
Understanding what is the pipeline in machine learning helps clarify how modern AI systems are designed and run at scale. ML pipelines structure the entire workflow by connecting data processing, model training, deployment, and monitoring into a single automated and repeatable system. This improves efficiency, reduces manual effort, and ensures more consistent model performance in real-world environments. As machine learning continues to evolve, pipelines remain a key foundation for building reliable and scalable AI solutions.
For individuals and developers who want hands-on experience, you can start immediately with $100 free credits, available right after login to explore and run workloads on the platform. For enterprises, organizations, or teams that need customized solutions or large-scale deployment, please contact FPT AI Factory via the official contact form to discuss requirements and integration needs.
Contact information
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore Related Articles:


