
When it comes to modern data integration, ETL vs ELT is one of the most debated topics among data engineers and architects. And for good reason, as the choice between the two can significantly impact pipeline performance. Each approach carries distinct advantages depending on your infrastructure and data volume. FPT AI Factory offers comprehensive data and AI solutions that help organizations evaluate, implement, and scale the right data pipeline strategy for their unique needs.
1. What Is ETL?
ETL, which stands for Extract, Transform, and Load, is the process data engineers use to extract data from different sources, transform the data into a usable and trusted resource, and load that data into the systems that end-users can access and use downstream to solve business problems. In this approach, data is cleaned, standardized, and mapped to a defined schema before it ever reaches the target system, meaning only processed, analytics-ready data makes it into the destination.
ETL is the right fit when organizations need a high degree of control over data quality before it enters a data warehouse. A well-designed ETL pipeline removes errors, duplicates records, and enriches data before it reaches the warehouse, improving consistency, performance, and trust across the organization. This makes ETL particularly valuable for regulated industries or use cases where schema compliance, data governance, and audit trails are non-negotiable requirements.
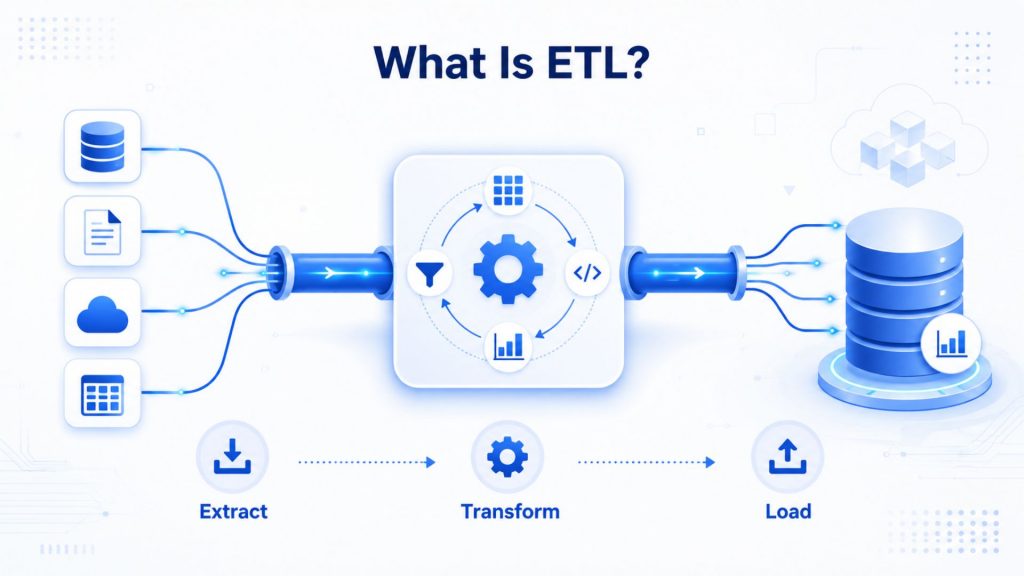
ETL is the process data engineers use to extract data from different sources
2. What Is ELT?
ELT, which stands for Extract, Load, Transform, is a contemporary data integration strategy that emphasizes loading raw data into storage before transformation takes place. Unlike ETL, where data must be cleaned and reshaped before it enters the destination system, ELT moves raw data directly into the target environment first and defers all transformation work until after the data has landed.
Cloud data warehouses such as BigQuery, Amazon Redshift, and Databricks provide the elastic, massively parallel compute that makes ELT practical at scale, allowing organizations to perform complex transformations directly within the warehouse rather than relying on a separate transformation layer. The result is a faster, more flexible pipeline that can accommodate large and varied datasets without the bottlenecks of traditional pre-load processing.
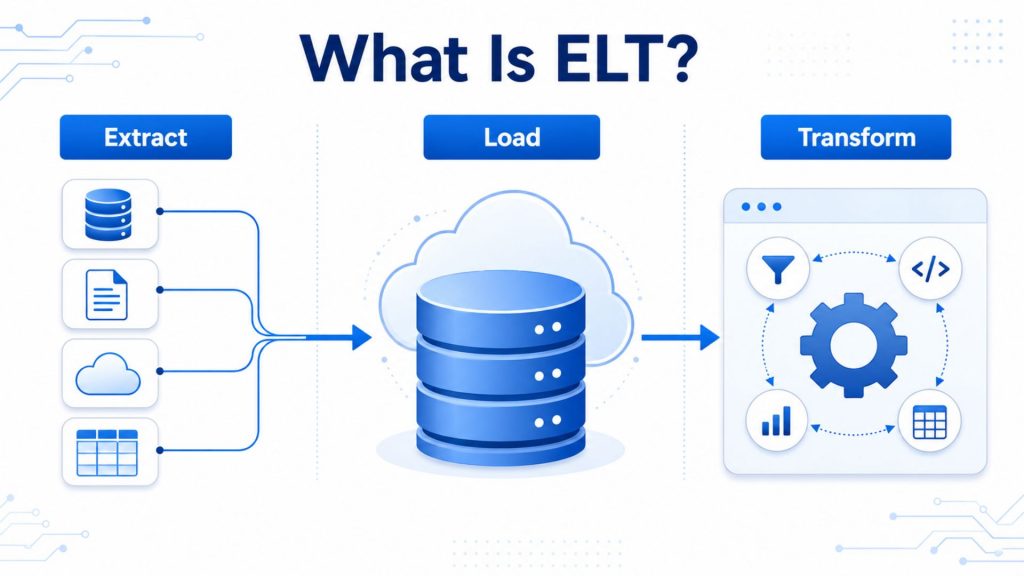
ELT is a contemporary data integration strategy
3. ETL vs ELT: Key Differences
The key distinction between ETL and ELT comes down to the sequence of steps: in ETL, data is transformed before being loaded into the destination system, whereas ELT involves loading raw data first and then performing transformations within the target environment. This difference is especially important for AI and machine learning teams, because model development often requires access to large volumes of raw, semi-structured, and constantly changing data.
For traditional business intelligence workloads, ETL is often effective because the required outputs are already well-defined. Data can be cleaned, standardized, and loaded into a warehouse for stable reporting. However, AI teams usually prefer ELT because machine learning workflows are more experimental. Data scientists may need to test different features, reuse the same raw data for multiple models, and adjust transformation logic as model requirements evolve.
ELT also fits better with modern data lakehouse architectures, where raw data, structured data, and transformed analytical datasets can coexist in the same environment. This allows AI teams to work with large-scale datasets such as clickstream logs, user behavior data, transaction histories, sensor data, images, and documents. Instead of forcing all data into a fixed schema before storage, ELT allows teams to store data first and decide later how it should be transformed.
The table below breaks down how this difference plays out across every major dimension of a data pipeline:
| Criteria | ETL | ELT |
| Process order | Extract → Transform → Load | Extract → Load → Transform |
| Transformation timing | Before loading, data is cleaned and shaped in a staging area first | After loading, the raw data lands in the destination and is transformed on demand |
| Processing location | A separate staging server or processing engine handles transformation before data enters the warehouse | Transformations run directly inside the target cloud warehouse using its own compute power |
| Data storage approach | Only processed, structured data is stored in the target system | Raw data is stored as-is, enabling multiple re-transformations without re-extracting |
| Scalability | Limited by the capacity of the dedicated transformation engine | Modern cloud warehouses like Amazon Redshift, Snowflake, and Google BigQuery are designed specifically for transforming large volumes of raw data efficiently |
| Speed | Slower initial load due to upfront transformation, queries are faster post-load | Faster ingestion, transformation may take longer depending on warehouse compute availability |
| Cost structure | Higher infrastructure costs for separate transformation servers, predictable and controlled | Pay-as-you-go cloud compute, cost scales with transformation complexity and query volume |
| Data governance | Stronger upfront governance, data quality is enforced before it enters the warehouse | More flexible, but requires governance to be applied at transformation time within the warehouse |
| Best use case | Complex data transformation projects, legacy systems, and use cases requiring extensive data cleaning before loading | Large volumes of data, real-time or near-real-time processing, and exploratory analytics |
| Structured vs unstructured data | Best suited for structured data with well-defined schemas | Handles both structured and unstructured data, such as logs, images, and documents |
| Example | A bank extracts transaction records nightly, cleans and masks PII data, then loads clean records into an on-premises data warehouse for compliance reporting | An e-commerce company loads raw clickstream, order, and inventory data into Snowflake throughout the day, then transforms it into sales dashboards using dbt as needed |
4. How ETL and ELT Work in a Data Pipeline
Understanding the mechanics behind each approach helps teams make better architectural decisions, and know where each fits within a broader modern data stack.
4.1 ETL workflow
An ETL pipeline follows a strict sequential flow. First, data is extracted from source systems, this can include relational databases, APIs, flat files, SaaS applications, or IoT devices. During the extraction phase, different data formats are managed appropriately, whether structured data from an SQL database or unstructured data from a log file, and the extraction process is designed to be as non-intrusive as possible to avoid disrupting source systems.
The data then moves to a staging area where the transformation takes place. In this stage, data gets cleansed, mapped, and transformed, often to a specific schema, so it meets operational needs, and audit reports for regulatory compliance can be generated, or data issues can be diagnosed and repaired. Only once all transformations are validated does the clean, structured dataset get loaded into the target data warehouse.
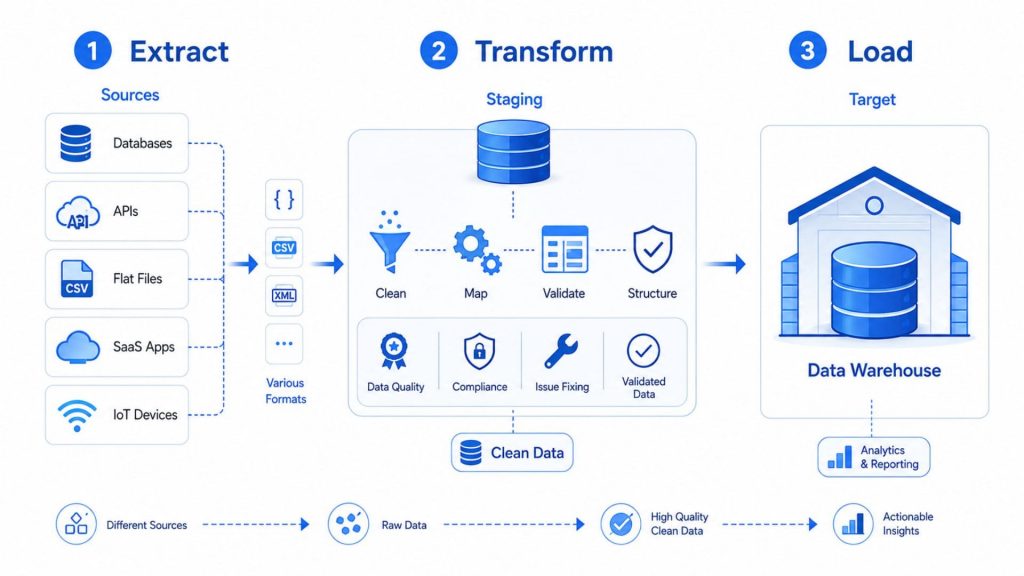
An ETL pipeline follows a strict sequential flow
4.2 ELT workflow
In an ELT pipeline, the order shifts significantly. After extraction from source systems, raw data is loaded directly into the destination, typically a cloud data warehouse or data lake, without any prior transformation. With an ELT pipeline, data cleaning, enrichment, and transformation all occur within the data warehouse itself, and raw data is stored indefinitely, enabling multiple transformations as business requirements evolve.
This deferred transformation model offers a meaningful advantage in flexibility. Teams can query and reshape the same raw data in different ways for different use cases, building multiple analytics models from a single source of truth, without ever having to re-extract from source systems. This shift in order is what makes ELT faster, more flexible, and more scalable, as businesses can handle large, complex, and diverse datasets without the limitations of traditional ETL infrastructure.
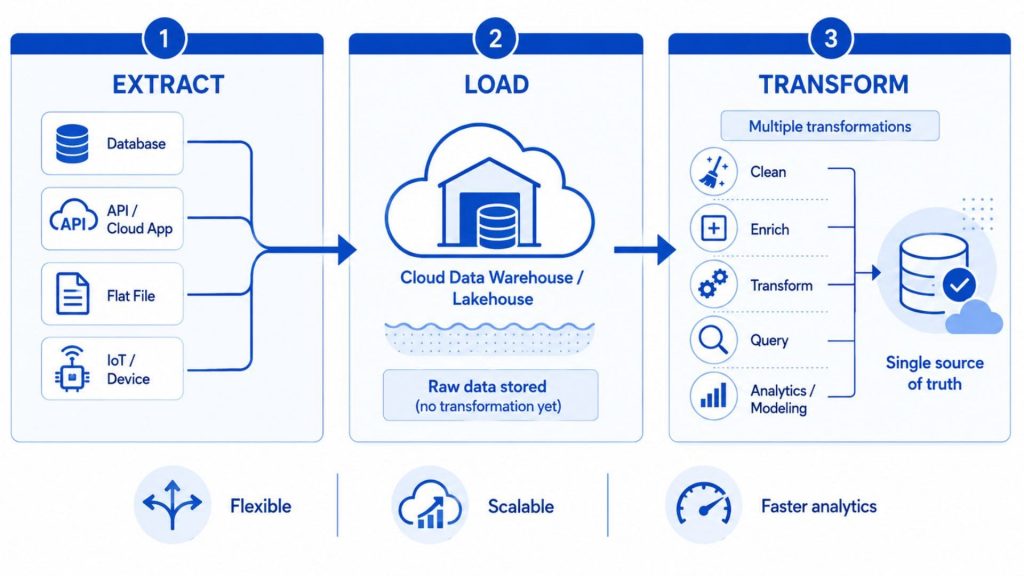
With an ELT pipeline, data cleaning and transformation all occur within the data warehouse itself
4.3 Role of data warehouses and data lakes
The choice between ETL and ELT is closely tied to the type of destination system in use. A data warehouse stores refined, pre-processed data optimized for reporting and business intelligence, following the ETL pattern, while a data lake keeps data in its raw format for greater flexibility, following the ELT pattern where loading precedes transformation.
In practice, many modern organizations maintain both. A data warehouse provides a governed, analytics-ready layer for structured reporting, while a data lake serves as a cost-effective raw storage layer for exploration, machine learning, and large-scale processing. Cloud platforms such as BigQuery, Amazon Redshift, and Databricks provide the compute foundation that makes ELT practical at scale, executing transformations directly where data is stored.
4.4 Batch processing vs near real-time processing
Both ETL and ELT can operate in batch or near real-time modes, and the choice between them often depends on how quickly the business needs access to fresh data. Batch processing pipelines are used for traditional analytics and business intelligence use cases where data is periodically collected and transformed. And moved to a cloud data warehouse while real-time processing pipelines enable ingestion from streaming sources such as IoT devices, social media feeds, and mobile applications.
Batch processing is simpler to implement and cost-efficient for use cases where hourly or daily data refresh is acceptable. Near real-time pipelines, by contrast, are necessary when latency matters. When detecting financial fraud, managing inventory in a fast-paced warehouse, or capturing a customer during an online session, a delay in the data pipeline is simply not acceptable, and streaming infrastructure becomes the foundation of the data stack.

Understanding the mechanics behind each approach helps teams make better architectural decisions
5. When Should You Use ETL?
ETL remains the right choice in several scenarios, particularly when data quality, governance, and compliance take priority over speed or flexibility. Here are the key situations where ETL is the stronger fit.
5.1 Compliance-heavy data workflows
In regulated industries, data often needs to be anonymized, masked, or validated against specific standards before it can be stored anywhere. In industries like finance, healthcare, and government, ETL is used to anonymize, encrypt, or mask data before storage to ensure compliance and minimize exposure risk. Loading raw, unprocessed data into a destination system isn’t an option when regulations like HIPAA, GDPR, or SOX mandate that sensitive information never be persisted in its original form.
Northmill Bank, a digital bank based in Sweden, used ETL pipelines via Hevo to generate audit trails for 100,000+ customer transactions per day, allowing their compliance team to pull audit-ready data instantly and cutting manual preparation effort by 60%.
5.2 Legacy data warehouse environments
Many enterprises still operate on-premises data warehouses built years or even decades ago. These systems were designed to receive clean, structured data in a defined format, they often lack the compute power or architectural flexibility to handle raw data transformations internally. ETL is critical for legacy systems that rely on on-premises data warehouses and have limited cloud connectivity, ensuring data is prepared and formatted before it enters the system.
Financial institutions use ETL solutions to extract data from multiple legacy source systems, transform it into the required format for regulatory reporting, and load it into reporting tools, helping them meet strict requirements from bodies such as the SEC, FINRA, and Basel III.
5.3 Structured data with strict schema requirements
When the destination system enforces a rigid schema, data must conform to that structure before loading. ETL handles this by applying mappings, type conversions, and normalization rules in the transformation stage, ensuring every record fits the expected format. Because transformations happen before loading, ETL gives teams more control over how sensitive or regulated data is processed, making it easier to meet internal data governance policies.
Retailers use ETL pipelines to consolidate data from e-commerce platforms, POS systems, inventory tools, and loyalty programs into a centralized data warehouse, powering insights into sales trends, customer behavior, and inventory management.
5.4 Data quality control before loading
Some workflows demand that only verified, clean data ever enters the warehouse. ETL supports this by running validation, deduplication, and business rule checks in a staging environment before any record is committed to the target system. A well-designed ETL pipeline removes errors, deduplicates records, and enriches data before it reaches the warehouse, improving consistency, performance, and trust across the organization.
A large healthcare network consolidating patient records from dozens of independent clinics applied ETL-based validation, achieving a 96% match rate and an 85% reduction in duplicate records, with data integrity treated as a direct patient safety requirement.
5.5 Smaller or controlled data volumes
ETL works best when data volumes are manageable and don’t require the elastic scalability of a cloud warehouse. ETL is well-suited for creating data repositories that are smaller, need to be retained for a longer period, and don’t require frequent updates, making it a practical choice for teams that don’t need big data infrastructure but still need reliable, well-governed pipelines.
A mid-sized insurance company running scheduled nightly batch jobs to pull claims data from three internal systems. They apply standardization rules and load a clean dataset into their on-premises reporting warehouse, a controlled, predictable workflow that runs reliably without cloud-scale compute.
ETL remains the right choice in several scenarios
6. When Should You Use ELT?
ELT is the default choice for modern, cloud-native data stacks. It shines when speed, scale, and flexibility matter more than upfront data control.
6.1 Cloud data warehouse environments
If your organization already operates on a cloud data platform, ELT is the natural fit. Cloud data warehouses such as Snowflake, BigQuery, and Redshift are designed to load raw data directly before performing transformations inside the warehouse, making ELT faster, more flexible, and more scalable than traditional ETL infrastructure. There’s no need for a separate transformation server when the warehouse itself can handle the work more efficiently.
Many production-grade data teams have adopted a modern ELT architecture using dbt and BigQuery. It pushes raw data into a landing schema in BigQuery, then applies staged transformations using dbt models, before serving results to BI tools like Looker
6.2 Large-scale raw data processing
When data volumes are massive and varied, transforming everything before loading can quickly become a pipeline bottleneck. ELT solves this by loading raw data first, then using cloud warehouses such as Google BigQuery to transform data at scale. Because BigQuery is built for large analytical workloads, teams can store raw data centrally, reuse it for different business needs, and transform it later without re-extracting data from source systems.
For example, Zeotap modernized its Customer Data Platform by shifting from ETL to ELT with BigQuery. Instead of transforming user and event data before loading, Zeotap streams raw data through Pub/Sub into BigQuery, where transformations happen directly inside BigQuery. This helps streamline the pipeline, remove separate processing steps, and support scalable customer data processing.
6.3 Real-time or faster data availability needs
Businesses that need near-real-time analytics can’t afford the latency of batch-based ETL. ELT supports faster ingestion by loading raw data immediately, with transformations running on demand as soon as the data lands. Modern data warehouses like Amazon Redshift, Snowflake, and Google BigQuery are designed specifically for transforming large volumes of raw data efficiently, enabling real-time or near-real-time reporting.
For instance, Stripe relies on real-time ELT-based data processing to detect fraudulent transactions as they occur, enabling timely intervention and maintaining customer trust without sacrificing pipeline throughput.
6.4 Flexible analytics and experimentation
ELT is particularly well-suited for teams that need to explore data from multiple angles or iterate on business logic without rebuilding pipelines. Because raw data is preserved in the warehouse, analysts can run new transformations at any time without touching the source. With ELT, you can transform data in different ways on the fly to produce different types of metrics, forecasts, and reports.
Teams building ELT pipelines with dbt and BigQuery can store raw data in the warehouse and re-run new transformations in the event of finding a pipeline error or a desire to enrich views with additional information, without losing any original data in the process.
6.5 AI and machine learning data workflows
ML pipelines require access to raw, unprocessed data, feature engineering decisions often change as models evolve, and locking data into a fixed schema too early limits what’s possible. ELT is well-suited for use cases where data needs to be analyzed in its raw form, such as in machine learning workflows, real-time reporting, and data lakes, where flexibility at the transformation layer is essential.
Data teams and data scientists working on ML projects need a dedicated environment to explore raw data and prepare datasets for training, all before those pipelines go to production. FPT AI Factory’s AI Notebook is built for exactly this kind of iterative workflow, providing a cloud-based notebook environment where teams can connect directly to their data warehouse, experiment with ELT-style transformations, and build ML-ready datasets without leaving their development environment.

AI Notebook provides a cloud-based notebook environment (Source: FPT AI Factory)
7. Cost and Operational Considerations
Cost and operations are important when choosing between ETL and ELT. ETL often offers stronger control before data is loaded, while ELT can provide more flexibility and scalability in cloud-native data environments.
| Criteria | ETL | ELT |
| Infrastructure cost | Usually requires a separate ETL server, middleware, or processing layer before data is loaded. This can increase infrastructure planning and setup costs, especially in traditional or on-premise environments. | Often uses the target cloud warehouse, lake, or lakehouse as the main processing environment, reducing the need for a separate transformation layer. |
| Compute cost | Compute is spent before loading, usually in an ETL tool or external processing engine. This can be predictable for scheduled batch jobs but may become costly if transformations are complex. | Compute is consumed inside the target platform during transformation. This can scale well, but large SQL transformations or repeated model-preparation jobs may increase cloud compute bills. |
| Storage cost | ETL usually stores only cleaned and structured data in the warehouse, which can reduce storage duplication. However, raw data may need to be archived separately if teams want traceability. | ELT often stores raw data and transformed data together or in separate layers. Storage costs may be higher, but cloud object storage and modern lakehouse designs make this practical at scale. |
| Transformation cost | Transformations happen before loading, so teams may spend more effort designing rules, schemas, validation logic, and data quality checks upfront. | Transformations happen after loading, so teams can transform data on demand for different analytics, ML, or business use cases. However, repeated transformations can raise computational costs. |
| Maintenance effort | ETL pipelines can be easier to govern when schemas and data quality rules are stable, but they may be harder to modify when source systems or business logic change. | ELT pipelines can be more flexible because raw data is already available in the destination, but teams must manage transformation logic, data lineage, and warehouse performance carefully. |
| Required data engineering skills | Requires strong skills in data modeling, schema design, data cleansing, batch processing, and ETL tool configuration. | Requires strong SQL, cloud data warehouse, data lake, orchestration, and transformation framework skills. Analytics engineers often play a larger role in ELT workflows. |
| Monitoring and troubleshooting | Issues are often detected before data enters the warehouse, making it useful for strict validation and compliance-heavy workflows. However, failures in external ETL jobs may require tool-specific debugging. | Monitoring must cover raw ingestion, warehouse transformations, query performance, and downstream models or dashboards. ELT gives flexibility, but troubleshooting can become distributed across more layers. |
| Long-term scalability | Scales well for controlled, structured, and governance-heavy workloads, especially when data volumes are predictable. However, scaling may require more infrastructure investment. | Scales well in cloud-native environments because modern platforms can separate storage and compute and support large volumes of structured, semi-structured, and raw data. This makes ELT a strong fit for modern analytics and AI workflows. |
8. ETL and ELT in Modern AI and Analytics Workflows
ETL and ELT are no longer only about moving data into a warehouse for reporting. In modern AI and analytics environments, they help prepare raw data for dashboards, experimentation, machine learning, feature engineering, and data lakehouse platforms.
8.1. Preparing datasets for machine learning
Machine learning models depend heavily on clean, consistent, and well-structured datasets. ETL can be useful when teams need to validate, clean, deduplicate, normalize, and standardize data before it enters a controlled training repository. This is especially helpful when model training requires strict data quality, consistent labels, or regulated data handling.
ELT is useful when teams want to collect large volumes of raw data first and prepare different training datasets later. For example, raw application logs, customer behavior data, transaction records, and sensor data can be loaded into a cloud data platform, then transformed into model-ready tables as needed. This approach gives data scientists and ML engineers more flexibility because the raw data remains available for future experiments.
8.2. Feature engineering and transformations
Feature engineering often requires repeated transformations, such as aggregating user behavior, calculating time-window metrics, encoding categories, joining multiple datasets, or deriving statistical features. ETL can handle these transformations before loading when features must be standardized and approved before they are used by downstream systems.
ELT is often more flexible for feature engineering because transformations can be performed directly inside the warehouse, data lake, or lakehouse. Teams can build multiple feature views from the same raw data without repeatedly extracting data from source systems. This is useful for experimentation, where data scientists may test several feature sets before deciding which one improves model performance.
8.3. Data lakehouse architectures
Data lakehouse architectures are becoming important in AI and analytics because they combine the scalability and flexibility of data lakes with the management and reliability features of data warehouses. Databricks describes a lakehouse as an architecture that combines the flexibility, cost efficiency, and scale of data lakes with warehouse-style data management, enabling BI and machine learning on the same data.
In lakehouse environments, both ETL and ELT can be used. ETL may be applied to produce curated, governed, high-quality datasets for reporting or compliance. ELT may be used to load raw and semi-structured data quickly, then transform it into bronze, silver, and gold data layers for analytics, ML, and experimentation. This makes lakehouse architecture well suited for organizations that need one platform for data engineering, business intelligence, data science, and AI development.
8.4. Analytics and experimentation workflows
Modern analytics teams need fast access to reliable data for dashboards, A/B testing, product analytics, customer segmentation, and business performance monitoring. ETL supports these workflows by delivering trusted, clean, and structured datasets to reporting systems. This is valuable when dashboards must use consistent business logic and approved metrics.
ELT supports experimentation by allowing analysts and data scientists to work from raw or lightly processed data and create new transformation models quickly.This makes ELT useful for fast-moving analytics teams that need agility, while ETL remains useful when accuracy, governance, and repeatable metric definitions are the priority.
ETL and ELT help prepare raw data for dashboards
9. FAQs
9.1 What is the main difference between ETL and ELT?
The main difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) lies in the order of operations. In ETL, data is extracted from source systems, transformed into a suitable format, and then loaded into a data warehouse. In contrast, ELT first loads raw data into the target system and performs transformations afterward. This shift allows ELT to leverage the processing power of modern data platforms.
9.2 Is ELT replacing ETL?
ELT is not completely replacing ETL, but it is becoming more popular, especially in cloud-based environments. Traditional ETL is still widely used in legacy systems or when strict data transformation is required before storage. However, ELT is increasingly preferred for its flexibility, scalability, and ability to handle large volumes of raw data efficiently.
9.3 Which is better for cloud data warehouses: ETL or ELT?
ELT is generally considered better for cloud data warehouses because these platforms are designed with strong computational capabilities. By loading raw data first and transforming it within the warehouse, ELT takes full advantage of distributed processing, making it faster and more scalable compared to traditional ETL approaches.
9.4 Which is more cost-effective: ETL or ELT?
The cost-effectiveness depends on the use case, but ELT is often more cost-efficient in modern cloud environments. It reduces the need for separate transformation infrastructure and allows organizations to use the built-in processing power of cloud data warehouses. However, ETL can be more cost-effective in scenarios where early data filtering reduces storage and compute costs.
9.5. Can ETL and ELT be used together?
Yes, ETL and ELT can be used together in a hybrid approach. Organizations may use ETL for initial data cleansing and sensitive transformations before loading, and then apply ELT for further processing and analytics within the data warehouse. This combination provides both control and flexibility, depending on specific data requirements.
If you are ready to accelerate your data workflows and analytics capabilities, explore our Starter Plan today. FPT AI Factory is currently offering $100 for users to accelerate their projects. This credit is valid for 30 days and includes:
- $10 for GPU Container and $10 for GPU Virtual Machine
- $10 for AI Notebook and $70 for AI Inference & AI Studio
- Access to up to 5M tokens with Llama-3.3 and 20+ other state-of-the-art models
For enterprises or organizations with needs for customization or large-scale data processing, please contact FPT AI Factory directly via the official contact form to receive tailored support and solutions.
In conclusion, when evaluating ETL vs ELT, there is no one-size-fits-all approach, the right choice depends on your data architecture, performance needs, and scalability goals. With FPT AI Factory, you can streamline your data pipelines, leverage advanced infrastructure, and build a future-ready analytics ecosystem tailored to your business objectives. Contact FPT AI Factory today to accelerate your data transformation journey and unlock the full potential of your data.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more articles
What Is Data Infrastructure? Key Components and How to Build It
What Is an AI Data Center? Architecture & Key Benefits


