
What are vector database? As generative AI transforms how businesses process text, images, and other unstructured data, vector databases have become essential for building fast, context-aware AI applications. FPT AI Factory provides the scalable infrastructure and AI tools needed to manage large datasets and optimize modern AI workflows efficiently.
1. What Are Vector Databases?
A vector database is a specialized storage engine optimized to store, index, and search high-dimensional vector embeddings generated by machine learning models. Unlike traditional relational platforms that rely on rigid tables, this database organizes unstructured information as mathematical coordinates in a multi-dimensional space. This geometric structure allows applications to instantly locate and retrieve complex data objects based on their actual conceptual meaning rather than relying on exact, literal keyword matches.
Vector databases are available in several forms to meet different deployment requirements. Open-source vector databases such as Milvus and Weaviate provide flexibility and customization for self-managed environments. Managed vector database services like Pinecone eliminate infrastructure management by offering fully hosted, scalable platforms. Meanwhile, PostgreSQL-based solutions such as pgvector extend existing relational databases with vector search capabilities, allowing organizations to combine structured data and semantic retrieval within a single system.
For example, if an enterprise user searches for the phrase “vehicles for cold weather,” a standard database would only return documents containing those exact words. In contrast, a vector database understands the underlying semantic context and can instantly retrieve highly relevant documents containing terms like “winter SUVs,” “snowmobiles,” or “all-wheel-drive trucks.” This capability ensures that AI-powered customer service chatbots and search engines provide incredibly accurate answers even when users use completely different vocabulary.

A high-level view showing how vector databases store multi-dimensional AI embeddings instead of rigid data rows.
2. Why Vector Databases Matter for AI
Deploying large language models in enterprise environments requires a retrieval framework that moves past the constraints of standard matching systems. Standard data management approaches fall short when dealing with complex reasoning patterns, massive scales, and the fluid nature of human language. Vector databases solve these infrastructure bottlenecks, making them an essential component of the modern AI stack for several key reasons:
- Enable true semantic search: They interpret user intent and conceptual meaning, delivering highly relevant search results even when exact matching keywords are completely missing.
- Deliver sub-second query latency: They utilize specialized indexing algorithms to search through millions of high-dimensional data vectors in milliseconds, maintaining ultra-low latency.
- Power accurate RAG systems: They act as an external knowledge base that provides precise, real-time context to LLMs, preventing hallucinations and ensuring factual accuracy.
- Scale horizontally with massive datasets: They allow production applications to store, update, and query billions of data points seamlessly without experiencing any system degradation.
- Drive advanced personalization: They analyze user behavior profiles converted into embeddings to instantly match individuals with relevant products, content, or services based on hidden preferences.

Architectural advantages showing how vector engines enable semantic search and prevent hallucinations in LLM workflows.
3. How Does Vector Databases Work?
Operating a high-dimensional data store involves a multi-stage computational pipeline that translates raw inputs into mathematical coordinates. This mathematical translation ensures that queries execute with sub-second latencies regardless of total dataset size.
3.1. Embedding generation
The process begins when raw, unstructured data, such as text documents, images, or audio files, is passed through a specialized machine learning model. This model analyzes the input and converts its semantic meaning into a string of numbers called a vector embedding. This digital representation positions the data point within a high-dimensional space where similar concepts are grouped closely together.
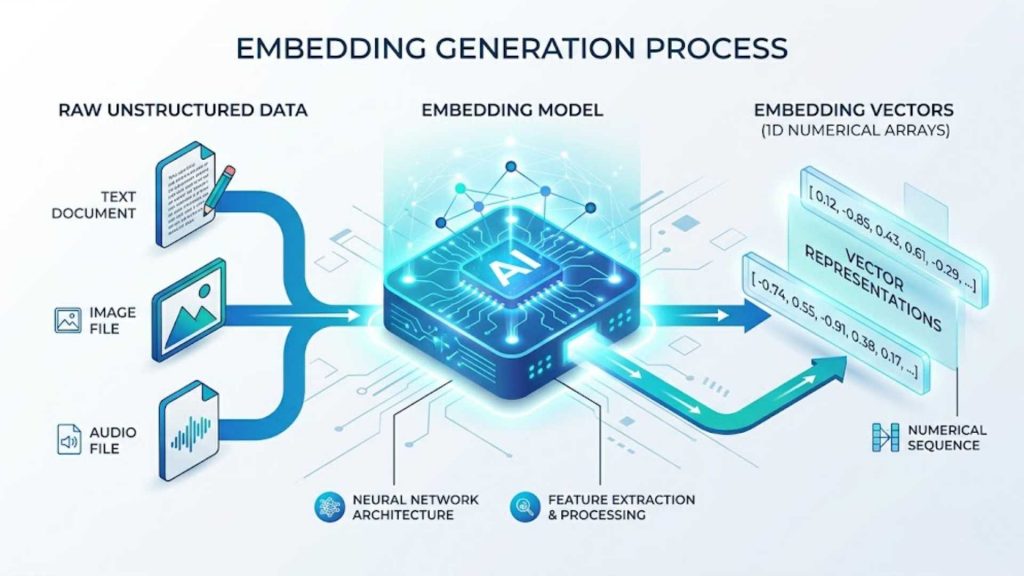
The multi-stage process of converting raw unstructured data into numerical arrays using deep learning models.
3.2. Vector storage and indexing
Once the embeddings are generated, they are stored within the vector database, which applies specialized indexing algorithms to organize the high-dimensional space. Unlike traditional databases that use B-trees, vector systems use structures like Hierarchical Navigable Small World (HNSW) graphs or Inverted File Indexing (IVF). These indexes map out pathways across data coordinates, ensuring future search operations do not have to scan every single record line-by-line.
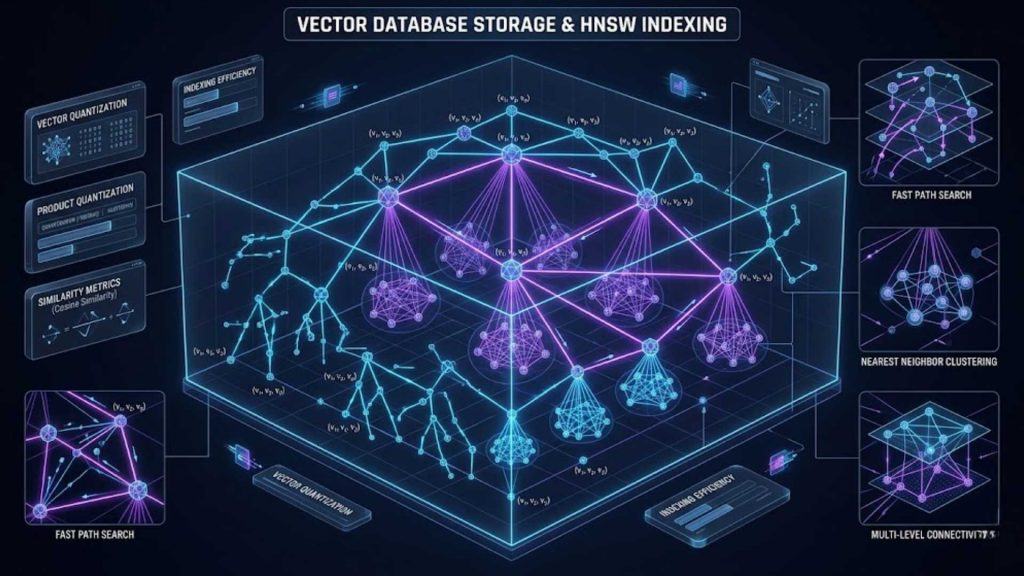
How vector databases organize high-dimensional data points using specialized graphs to ensure sub-second search latencies.
3.3. Similarity search and nearest neighbor retrieval
When a user submits a query, the application converts that inquiry into a vector embedding using the exact same machine learning model. The database then performs a similarity search, using mathematical metrics like Cosine Similarity or Euclidean Distance to calculate the distance between the query vector and stored data. The system quickly identifies the closest matching coordinates, known as Approximate Nearest Neighbors (ANN).
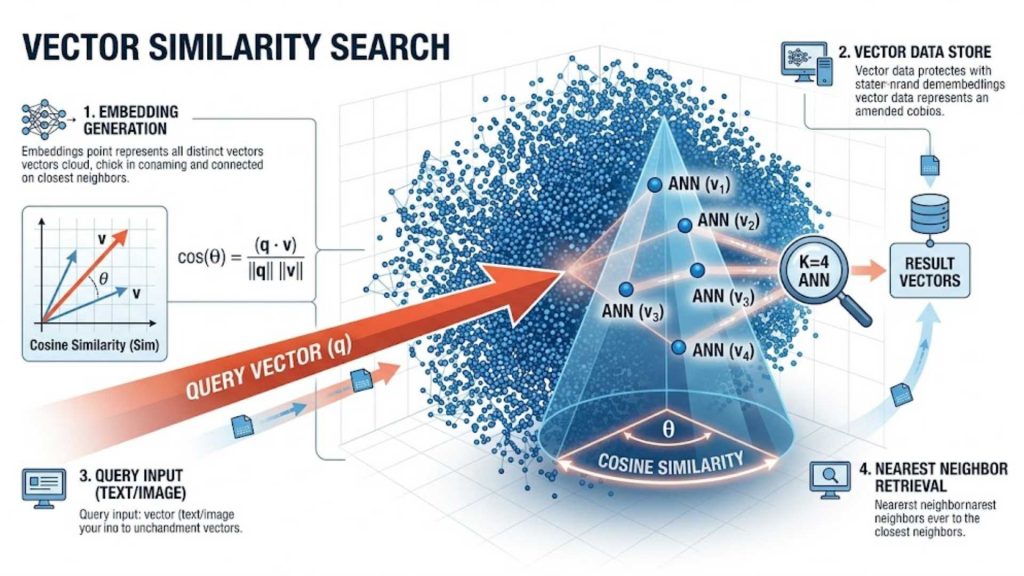
Visualizing query vector matching against stored datasets using mathematical distance metrics like Cosine Similarity.
3.4. Ranking and post-processing
After the nearest neighbors are retrieved, the database refines and sorts the results based on their closeness scores to filter out irrelevant data points. In many production pipelines, this stage also involves applying traditional metadata filters,such as checking document creation dates or user permissions. This ensures the final output matches both semantic intent and business logic.
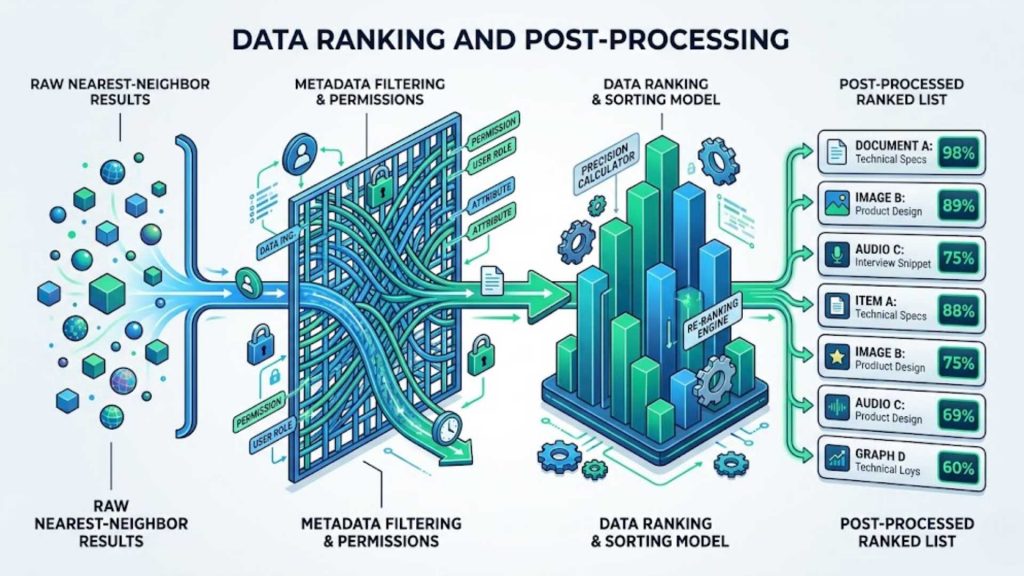
The refining stage where nearest neighbor results are filtered by business metadata and sorted by accuracy scores.
3.5. Integration with AI applications and LLMs
In the final step, the highly relevant data chunks retrieved by the database are packaged and sent directly to the AI application or LLM. The model reads this specific context alongside the user’s original prompt to generate an accurate, highly customized response. This complete cycle allows applications to deliver intelligent, dynamic answers based on proprietary enterprise knowledge.
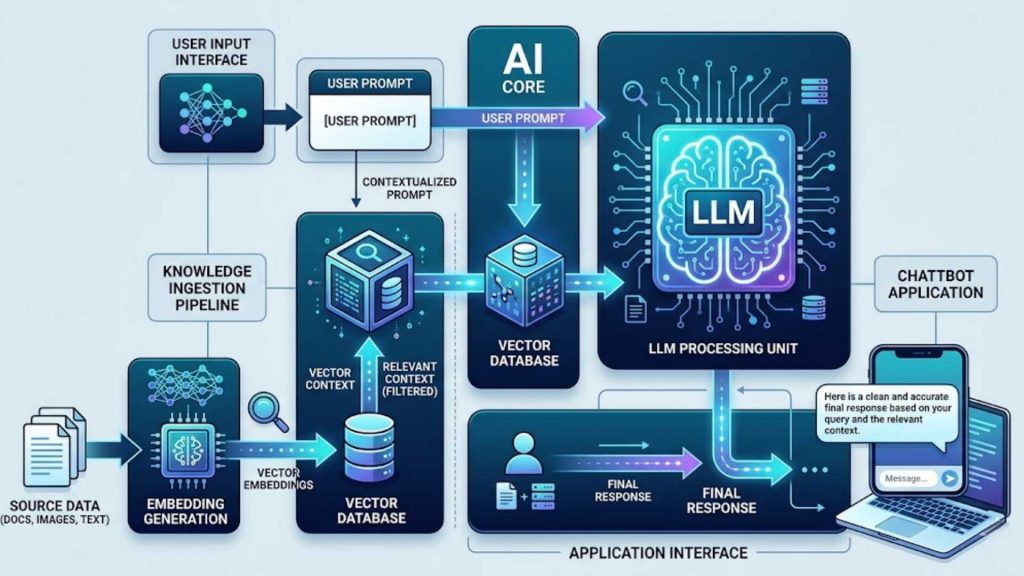
System architecture showing a vector database acting as long-term memory to supply relevant context directly to an LLM.
4. Vector Database Architecture
A vector database architecture combines embedding generation, efficient indexing, metadata management, and intelligent retrieval to support AI applications such as semantic search and Retrieval-Augmented Generation (RAG). The following components work together to deliver fast and context-aware data access.
- Embedding Model
An embedding model converts text, images, or other unstructured data into high-dimensional vector representations. These embeddings capture semantic relationships, allowing similar content to be located even when exact keywords differ. - Index
The index organizes vector embeddings for efficient similarity search across massive datasets. Advanced indexing algorithms reduce query latency while maintaining high retrieval accuracy for real-time AI applications. - Metadata
Metadata stores additional information associated with each vector, such as document IDs, timestamps, categories, or user attributes. This structured data enables filtered searches and improves retrieval precision. - Query Layer
The query layer processes incoming search requests by converting them into embeddings and performing similarity matching against indexed vectors. It can also combine vector search with metadata filtering to deliver more relevant results. - LLM
Large Language Models consume the retrieved information to generate context-aware responses and perform reasoning tasks. In RAG architectures, the vector database supplies relevant knowledge while the LLM synthesizes it into accurate, natural-language outputs.
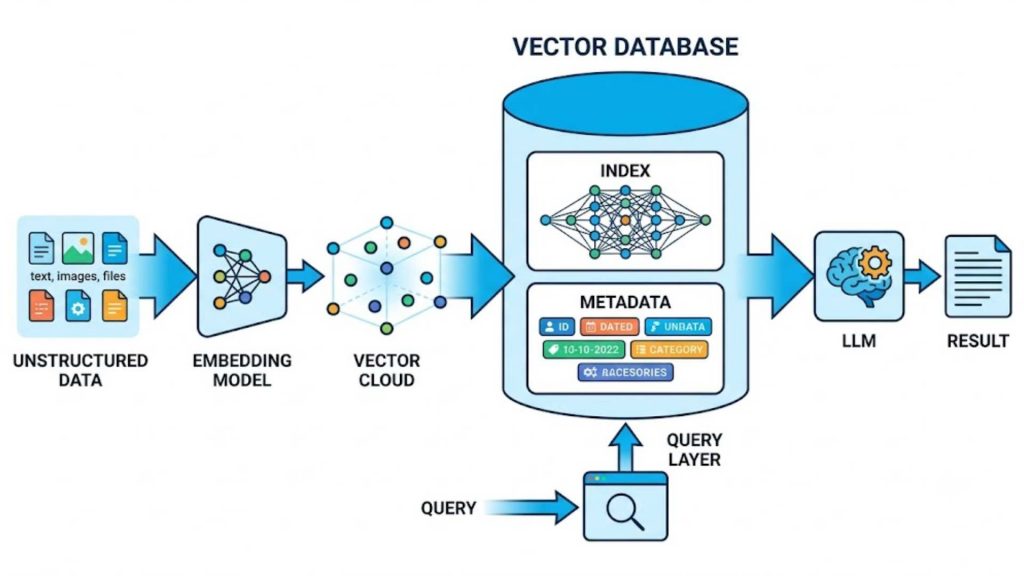
Vector database architecture for RAG and LLM applications
5. Compare Vector Databases vs Traditional Databases
Selecting the optimal infrastructure layout requires a clear contrast between relational paradigms and high-dimensional spaces. While legacy designs excel at maintaining exact transactional records, AI workloads require an entirely separate approach to validation and retrieval. This comparison highlights why technical teams deploy side-by-side database ecosystems to handle distinct organizational functions.
The key limitation of traditional databases in LLM environments is their reliance on exact matching and structured schemas. AI applications require semantic understanding, similarity search, and fast retrieval across millions of embeddings—capabilities that conventional relational databases were not originally designed to provide.
Choosing the right data architecture depends on the structure of your information and how your applications need to access it. The table below outlines the core differences between traditional database platforms and modern vector systems:
| Feature | Traditional Databases (Relational/NoSQL) | Vector Databases |
| Data Types | Structured numbers, strings, and tables | High-dimensional vector embeddings and metadata |
| Search Mechanism | Exact keyword matching, boolean queries, and regex | Mathematical similarity search (Cosine, Euclidean distance) |
| Core Structure | Rows, columns, key-value pairs, or document JSON | High-dimensional geometric space with graph/tree indexes |
| Query Intent | Focuses on exact string properties and data records | Focuses on semantic meaning, context, and data concepts |
| Primary Use Cases | Financial transactions, ERP, inventory management, and CRM | Generative AI, RAG, facial recognition, and semantic search |
| Scalability Focus | ACID compliance, transactional throughput, and text indexing | Fast nearest-neighbor retrieval across billions of dimensions |

A direct structural comparison contrasting traditional relational tables with multi-dimensional geometric vector spaces.
6. Vector Database Use Cases
The commercial utility of mathematical similarity search spans across various industries, optimizing how digital ecosystems interact with target audiences. From refining internal productivity to automating security monitoring, geometric intelligence reshapes core software functions. Below are the prominent ways production teams utilize vector structures to achieve automated operational breakthroughs.
6.1. Retrieval-augmented generation (RAG)
Enterprises building RAG applications often need centralized data pipelines to manage documents, embeddings, and retrieval workflows. Platforms like AI Studio Data Hub help organize enterprise knowledge sources before they are indexed into vector databases for semantic search and LLM applications. By pairing a structured data pipeline with a high-capacity vector store, businesses can create secure internal chatbots that answer questions using private corporate documentation without risk of data leaks.
Example: A prominent legal-tech firm implemented a vector-powered RAG pipeline to analyze hundreds of thousands of complex litigation records. According to a case study by Pinecone, integrating a dedicated vector store cut document retrieval time from hours to under 100 milliseconds, boosting legal research productivity by over 40% (Source: Pinecone Case Studies).
6.2. Conversational AI and chatbots
Standard chatbots often give repetitive or irrelevant answers because they rely on rigid, pre-written operational scripts. Integrating vector storage allows conversational agents to remember previous user interactions and reference long-term dialogue histories dynamically. This capability creates human-like chat experiences where the virtual assistant retains context across long discussions and handles complex customer inquiries naturally.
6.3. Recommendation systems
E-commerce and content streaming services leverage similarity search to dramatically improve their user engagement rates. By converting user browsing histories, past purchases, and product descriptions into a shared vector space, the database can instantly recommend items that share deep conceptual similarities. This approach delivers highly personalized recommendations that capture subtle taste patterns traditional tag filtering overlooks entirely.
Example: Instacart utilized vector similarity search to map millions of user query patterns and grocery products into a shared high-dimensional space. By leveraging Milvus to index their embeddings, they successfully processed massive user click streams in real time, increasing item discovery rates and search conversion by 15% (Source: Milvus Vector Database Case Studies).
6.4. Semantic search engines
Enterprise search tools frequently frustrate employees when they fail to return relevant results due to minor spelling variances or missing keywords. Semantic search engines solve this by analyzing the underlying intent behind every search phrase to find conceptually identical documents. A query for “revenue optimization strategies” can easily retrieve internal reports labeled “maximizing profit margins” because their vector embeddings reside in the exact same mathematical neighborhood.
Example: The language learning platform Duolingo integrated vector similarity search to scale its specialized user vocabulary and question matching databases. Shifting to an optimized vector database allowed them to execute nearest-neighbor queries across billions of tracking points with sub-10 millisecond latency, maintaining high user retention scores (Source: Qdrant Vector Search Success Stories).
6.5. Image and multimodal search
Vector databases are uniquely capable of handling multimodal applications where text queries are matched directly against non-text assets. A user can upload a cell phone photograph or type a descriptive phrase like “dark blue winter coat with silver buttons” to find identical visual items. The database matches the conceptual embeddings of the text prompt against the image embeddings, enabling rapid visual discovery without relying on manually entered alt-text tags.
6.6. Fraud detection and anomaly detection
Financial networks process millions of transaction events every minute, making manual oversight impossible. Security teams can convert transaction patterns,including timing, geographic locations, and spending amounts, into vector formats to monitor baseline network activity. When a fraudulent transaction occurs, its coordinates sit far away from normal consumer clusters, allowing automated monitoring systems to flag the anomaly instantly.
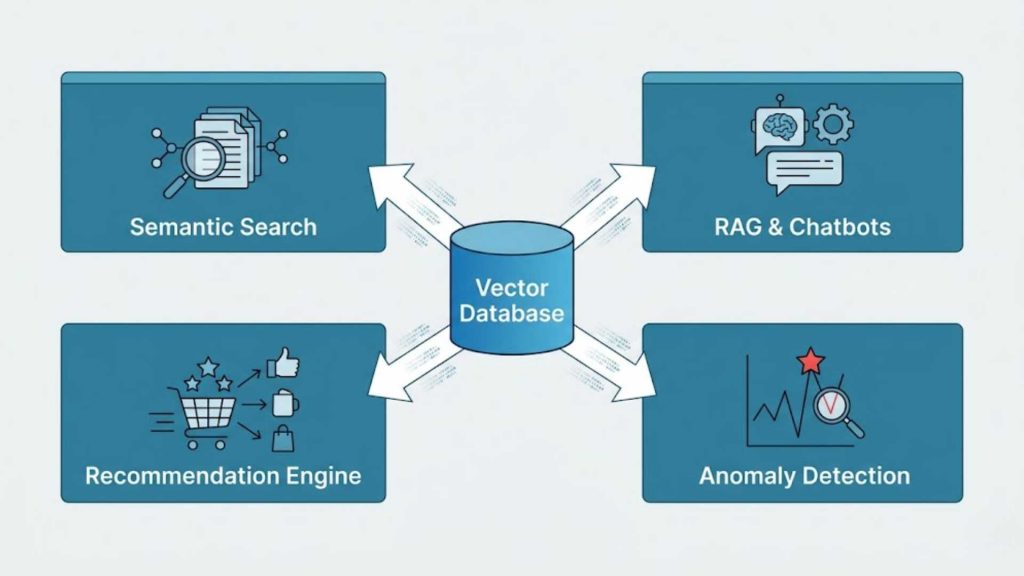
Real-world applications of vector search including enterprise RAG systems, smart recommendation engines, and fraud detection.
7. Vector Databases Challenges
Despite providing massive performance boosts for downstream model operations, multi-dimensional structures introduce unique hardware and mathematical obstacles. Engineering teams must carefully budget their hardware allocations to accommodate the extreme computational toll of similarity matching. Understanding these practical system bottlenecks prevents unexpected operational failures during production scaling phases.
While vector databases offer impressive capabilities for modern AI development, implementing them at an enterprise scale comes with specific engineering hurdles:
- High computational and memory requirements: Storing and querying high-dimensional vectors requires massive amounts of RAM and specialized hardware acceleration to maintain fast response speeds.
- Index maintenance complexity: As business applications add or update data continually, updating complex graph indexes like HNSW in real time without causing system slowdowns remains a major technical challenge.
- Lack of universal standardized query languages: Unlike the relational database world which relies universally on SQL, the vector ecosystem is highly fragmented, with different platforms using proprietary APIs.
- Difficulty measuring accurate precision and recall: Fine-tuning similarity parameters requires constant experimentation, as determining what constitutes a “correct” semantic match can be highly subjective.
- Data consistency and synchronization risks: Keeping standalone vector stores perfectly synchronized with primary relational enterprise databases introduces extra operational complexity to engineering pipelines.

Key engineering hurdles regarding high memory requirements and index maintenance complexity during production scaling.
8. FAQs
8.1. What is the difference between SQL and vector databases?
SQL databases store structured data in rigid rows and columns, retrieving information based on exact text matches, numeric ranges, and explicit relationships. Vector databases store data as high-dimensional numerical arrays, querying information using mathematical similarity metrics to find concepts that match the contextual meaning of an inquiry.
8.2 What is vector similarity search?
Vector similarity search is a mathematical retrieval process that calculates the distance between a user’s query vector and stored data vectors within a multi-dimensional space. Instead of checking for identical words, it uses formulas like Cosine Similarity to find data objects located closest to the query coordinate.
8.3 Which vector database is best for RAG?
The ideal choice depends on your specific infrastructure needs, data volume, and engineering capabilities. Popular open-source and native choices include Milvus and Qdrant for massive scale, Pinecone for a fully managed cloud experience, and pgvector extensions for teams wanting to stick with familiar PostgreSQL infrastructure.
Integrating geometric databases into modern enterprise applications marks a critical turning point in how companies extract value from unstructured data pools. These specialized engines provide the long-term memory layer that enables large language models to compute contextually flawless interactions. Maximizing these results requires a unified blend of strong hardware resources and managed software pipelines.
To accelerate your AI initiatives, you can deploy your workloads instantly using the advanced computing ecosystem provided by FPT AI Factory. New users can take advantage of our Starter Plan, offering a free $100 in credits valid for 30 days to immediately experience high-performance AI deployment. This starter package allocates $10 for GPU Container, $10 for GPU Virtual Machine, $10 for AI Notebook, and $70 for AI Inference & AI Studio. Your credit card configuration is securely encrypted with a minor $1 verification charge added directly back to your balance, granting you access to run up to 5M tokens with Llama-3.3 and over 20 advanced open-source models.
For enterprises, research institutions, and large-scale organizations requiring custom compute architectures or specialized infrastructure tuning, please contact our engineering specialists directly via the official FPT AI Factory contact form to build your bespoke solution.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more:
How to Deploy AI Model: A Step-by-Step Guide 2026
What Is Data Infrastructure? Key Components and How to Build It
What is an AI Data Platform and How Does It Work?
What Is an AI Data Center? Architecture & Key Benefits


