
Implementing an optimized framework for LLM orchestration is now essential to connect cognitive intelligence with practical enterprise software execution. As businesses build complex, data-driven applications, managing fluid data flows between multiple models and tools presents a major infrastructure challenge. Organizations can easily simplify this complexity and scale their advanced AI workflows by leveraging the high-performance cloud environment built by FPT AI Factory.
1. What Is LLM Orchestration?
LLM orchestration is the process of coordinating models, APIs, tools, memory, and workflows within an integrated AI system. It transforms standalone, isolated chat interfaces into centralized reasoning engines that handle dynamic, multi-step tasks seamlessly. This structural layer manages prompt execution, context retrieval, and model interactions, turning raw AI into reliable enterprise solutions.
LLM orchestration is essential because enterprise applications rarely rely on a single model or isolated prompt. It ensures consistent decision-making, connects AI with business systems, and automates complex workflows while reducing errors and operational overhead.
Example: An enterprise deploys an automated system to handle customer refund requests across various digital channels. When a user messages the system, the orchestration engine directs an LLM to analyze the intent and extract key invoice numbers. It then automatically checks internal databases, verifies purchasing compliance, and executes a refund through connected payment APIs.

The conceptual architecture of an orchestration engine positioning large language models at the center of enterprise software frameworks.
2. LLM Orchestration Architecture
A well-designed LLM orchestration architecture connects AI models, enterprise data, and external services into a unified workflow. Each layer has a distinct role in processing requests, maintaining context, and delivering reliable, real-time responses.
2.1 User or Application Layer
The user or application layer is the primary entry point for AI interactions. It receives requests from chatbots, web applications, mobile apps, or enterprise software. This layer collects user input and passes it to the orchestration engine for processing.
2.2 Orchestration Layer
The orchestration layer acts as the central coordinator of the entire AI workflow. It manages prompt construction, task routing, model selection, and decision logic. This layer also determines when to retrieve data, call external tools, or trigger additional processing steps.
2.3. Large Language Models
LLMs provide the core reasoning and language generation capabilities of the system. They analyze user queries, interpret context, and generate responses or structured outputs. Depending on the task, the orchestration layer may use one or multiple models to improve performance and accuracy.
2.4. Memory Layer
The memory layer stores contextual information that helps maintain continuity across interactions. It can preserve conversation history, user preferences, and intermediate task results. By retaining relevant context, the system delivers more personalized and coherent responses.
2.5. Vector Database and Retrieval Systems
Vector databases and retrieval systems store embeddings of documents, knowledge bases, and enterprise data. They enable semantic search to find information related to a user’s query. This retrieval process provides LLMs with up-to-date and domain-specific knowledge for more accurate outputs.
2.6. Tools and External APIs
Tools and external APIs extend the capabilities of LLMs beyond text generation. They allow the system to access databases, process payments, retrieve live information, or interact with business applications. The orchestration layer decides when and how to invoke these services during a workflow.
2.7. Monitoring and Observability
Monitoring and observability provide visibility into system performance and operational health. They track metrics such as response quality, latency, API usage, and error rates. These insights help organizations optimize workflows, improve reliability, and maintain compliance with enterprise requirements.
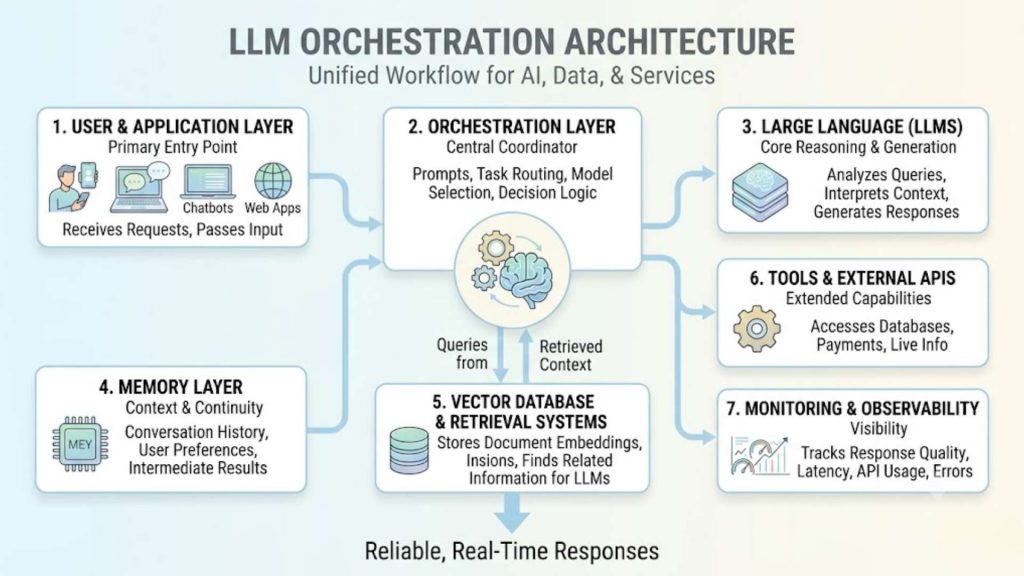
A simplified architectural diagram illustrating the 7 core layers of an LLM orchestration workflow for enterprise AI applications.
3. LLM orchestration workflow
Deploying large language models in enterprise environments requires a clear understanding of how different system components communicate under a unified management model. Modern orchestration frameworks provide the blueprint for this computational harmony, acting as the nervous system that connects raw model smarts with software integrations.
3.1. The Orchestration Layer
The orchestration layer sits directly between user-facing applications and the underlying foundational models or infrastructure. It functions as a central command center that intercepts user inputs, translates them into structured instructions, and routes them to the appropriate resources. By abstracting the complexities of direct model management, this layer ensures that data flows smoothly between vector databases, software tools, and different model checkpoints without hardcoding rigid logic.
3.2. Multi-Agent Orchestration
Multi-agent orchestration expands on this concept by dividing complex, large-scale tasks among several specialized AI agents rather than relying on a single model. Each agent is assigned a distinct role, such as data extraction, code generation, or quality assurance, and operates with its own specific prompts and toolsets. The orchestration framework manages the communication, state sharing, and task delegation between these agents, creating a collaborative digital workforce that resolves complex corporate objectives.

A structural layout demonstrating how the orchestration layer brokers communication between user applications and specialized model checkpoints.
4. How LLM Agent Orchestration Works?
To fully understand the power of automated systems, we need to trace exactly how an instruction travels through an orchestrated pipeline from start to finish. This multi-stage execution model relies on constant evaluation, continuous feedback, and smart tool utilization to deliver accurate results. The following diagram and detailed breakdown outline the step-by-step lifecycle of a modern orchestrated transaction.
4.1. Request Understanding and Routing
The process begins when a user or an external system submits a raw natural language query to the AI application. The orchestration framework analyzes the intent, extracts key variables, and determines the optimal path for fulfillment. If the query requires specialized domain knowledge, the framework dynamically routes the task to the specific model or agent best suited for the job.
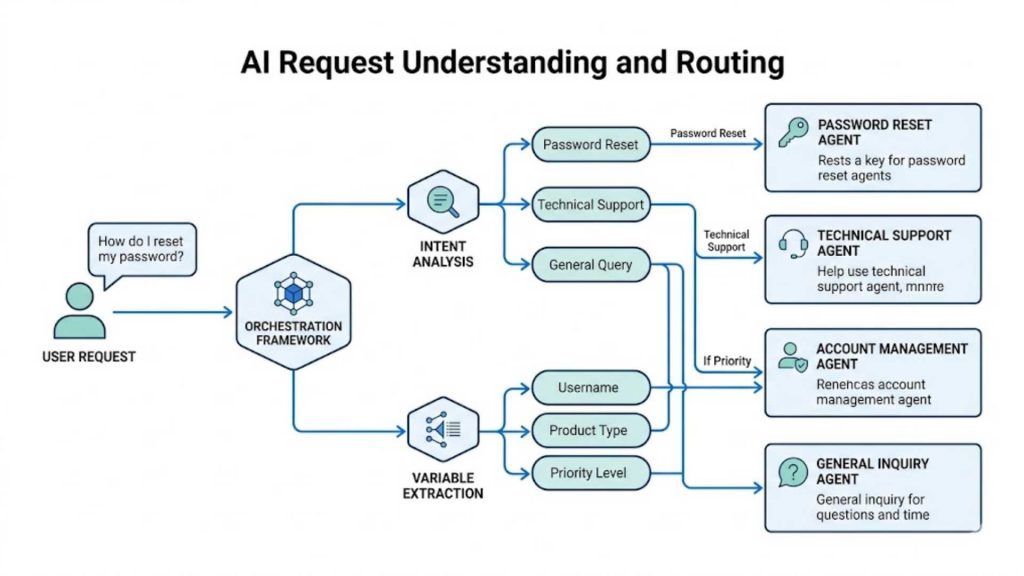
A minimalist blueprint illustrating intent analysis and automated routing logic to specialized AI domain agents.
4.2. Retrieval and External Data Access
Once the intent is established, the system gathers relevant background information to ground the model’s response and prevent hallucinations. The framework queries connected vector databases, enterprise document repositories, or live web search components to extract real-time data. This context is safely packaged and prepared for the next stage of the workflow execution.
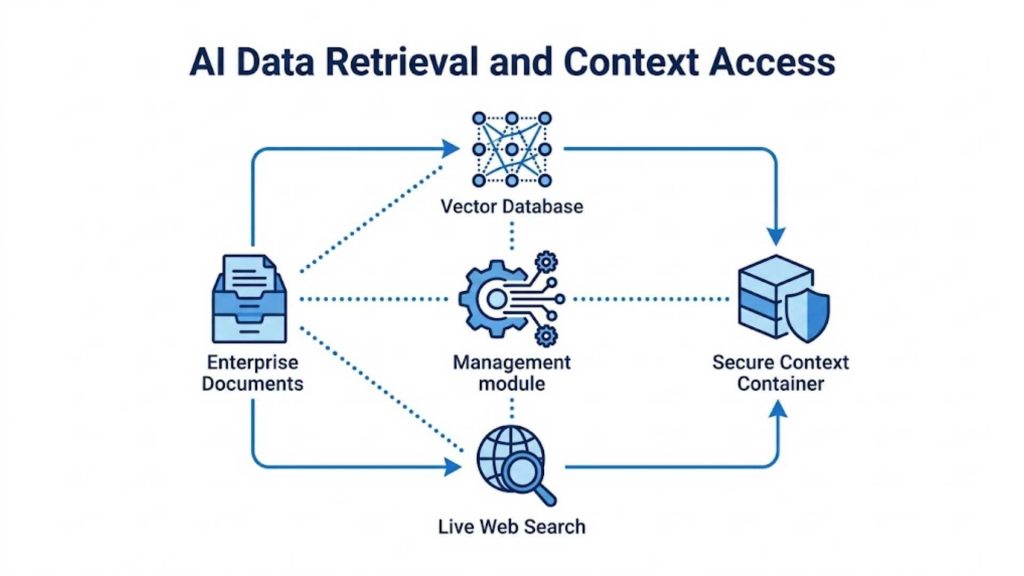
A conceptual diagram of the data retrieval flow connecting the central engine with secure vector databases and live document repositories.
4.3. Prompt Construction and Context Management
Raw user inputs and retrieved data are rarely sent directly to a large language model without processing. The orchestration engine dynamically compiles a structured prompt by merging system instructions, historical conversation logs, and newly retrieved data points. This process ensures strict token optimization while providing the model with the exact context required for accurate reasoning.
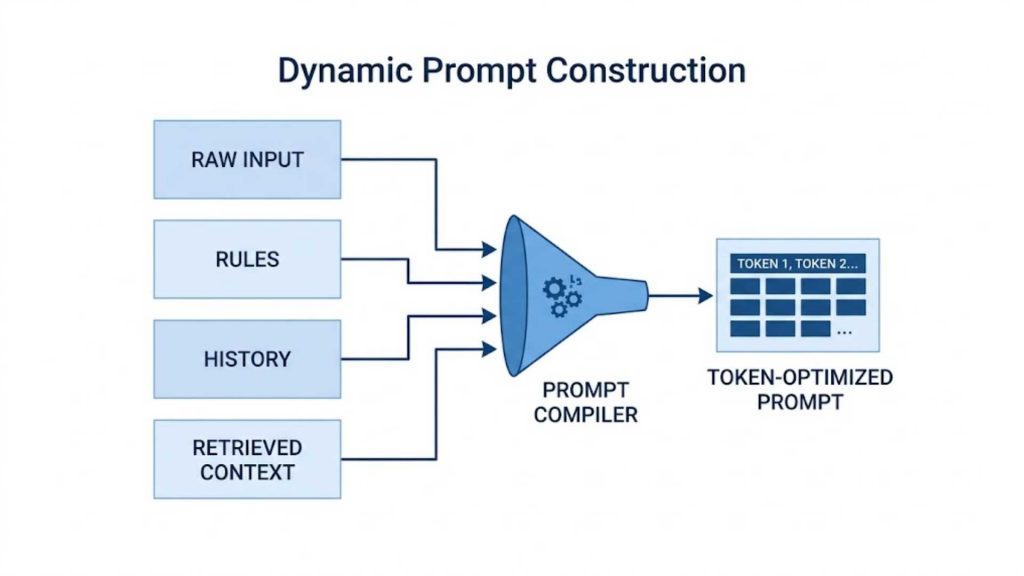
A layout displaying the prompt compiler merging user inputs, system logs, and context data into single token-optimized blocks.
4.4. Tool Calling and API Execution
When a query requires action rather than just text generation, the orchestration layer facilitates tool calling and external API execution. The model evaluates the prompt and outputs a structured command, such as a JSON object, indicating which tool to use. The framework intercepts this output, executes the live API call against an external system, and returns the payload to the model.
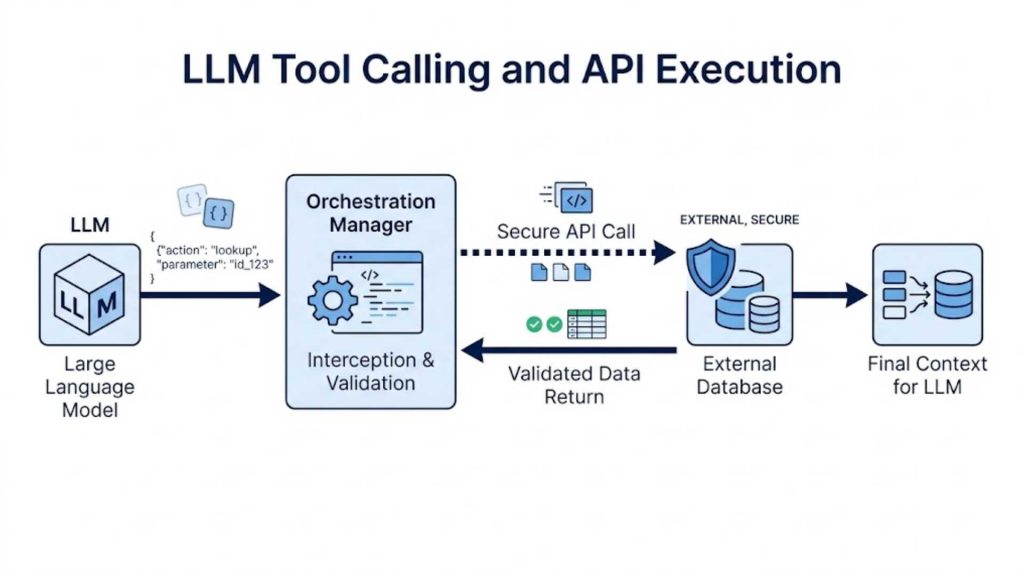
A functional flowchart showing how the system interprets JSON payloads to execute calls against external enterprise business servers.
4.5. Multi-Step Reasoning and Workflow Coordination
Complex corporate operations cannot be completed in a single conversational turn, requiring continuous evaluation and refinement. The framework guides the system through structured reasoning patterns, allowing it to evaluate intermediate results, fix errors, and modify its plans. This continuous execution loop persists until the orchestration framework confirms that the overarching task has been completely resolved.
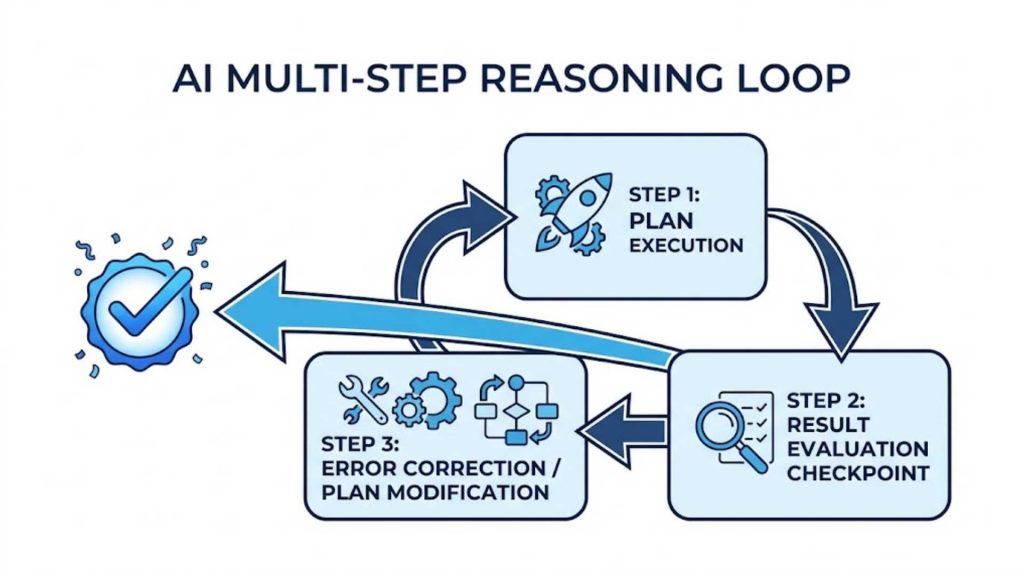
An iterative cyclic diagram mapping out the continuous planning, error correction, and task evaluation sequences within AI frameworks.
4.6. Response Generation and Monitoring
In the final phase, the system translates the fully synthesized technical data into a polished, user-friendly response. Before delivery, the orchestration layer passes the output through validation checks to enforce security boundaries and compliance standards. Concurrently, performance metrics, latency statistics, and token consumption rates are logged to analytical dashboards for continuous optimization.
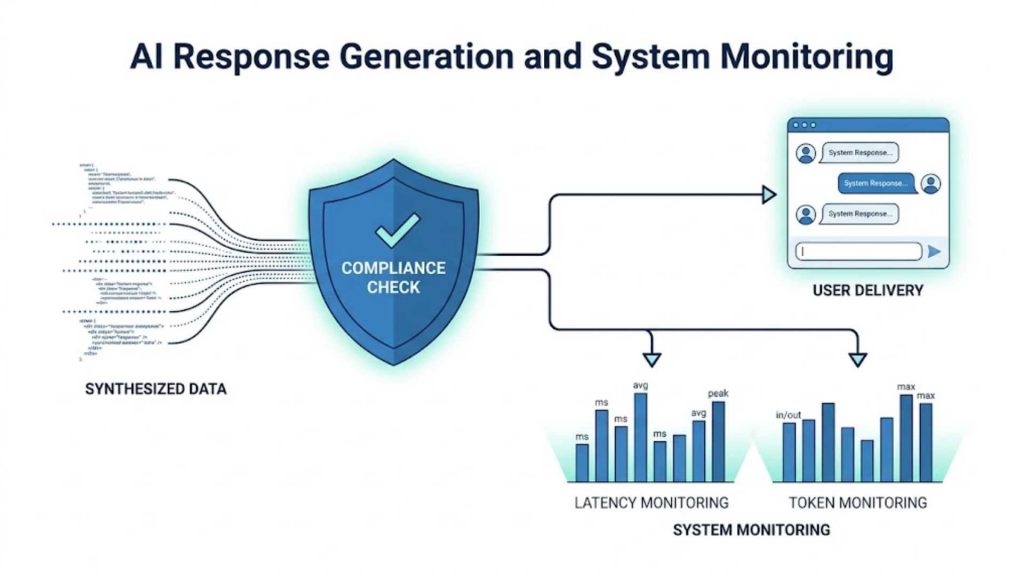
A structural chart demonstrating secure message delivery synchronized with immediate telemetry logging for latency and token costs.
5. Core Components of an LLM Orchestration Stack
Building an enterprise-ready orchestration framework requires combining several specialized software and hardware components into a secure, unified stack. Each layer has a specific job, ranging from managing prompt layouts to handling long-term memory across long user sessions. Understanding these core pieces helps engineering teams select the right software packages and avoid architectural bottlenecks down the road.
5.1. Orchestration Framework
This component serves as the structural skeleton that connects different parts of an AI ecosystem without requiring manual coding. It allows developers to easily arrange prompt execution paths and link large language models with internal software workflows.
Example: Developers utilize open-source tools like LangChain or LlamaIndex to establish automated execution chains for a customer service desk. When a customer sends a message, the framework identifies user intent and triggers matching solutions automatically.
5.2. Prompt Management
This system isolates system instructions and prompt templates from the core application codebase, allowing teams to modify them independently. It tracks prompt performance across multiple model versions and organizes diverse behavioral templates safely.
Example: An e-commerce platform stores all its tone-of-voice instructions inside a centralized manager like LangFuse. When marketing managers want to update the AI’s promotional style, they adjust the template directly inside the dashboard.
5.3. Retrieval Systems and Vector Databases
This system handles the processing, indexing, and vector mathematical embedding of unstructured business information. By storing these data chunks in high-speed vector engines, the AI can perform semantic lookups to pinpoint background answers in milliseconds.
Example: A corporate legal application integrates an embedding pipeline with a vector database like Pinecone to assist compliance officers. When a user queries a policy, the system converts the question into a vector and searches guidelines.
5.4. Memory and Conversation State
To maintain natural and coherent multi-turn user experiences, this component remembers past customer inputs and mid-process reasoning steps. The central engine constantly prunes this historical log to keep vital context alive without overloading model token limits.
Example: A virtual banking assistant uses a persistent caching layer to guide a customer through a multi-step credit card application. When the user returns after a break, the assistant remembers the previously provided name and figures.
5.5. Tool Calling and API Integration
This component functions as the operational hands of the AI, allowing language models to interact with real-world databases and software. This bridge converts passive text generation into active automation capable of modifying enterprise data.
Example: An HR agent is connected to an internal company calendar API to handle corporate scheduling requests from employees. When an employee requests a meeting room, the system generates a structured JSON payload to execute the booking.
5.6. Monitoring and Observability
Monitoring software monitors every step of an AI transaction, offering full visibility into infrastructure costs, system latency, and accuracy. This continuous stream of system telemetry data is vital for maintaining strict service level agreements.
Example: An engineering team deploys an analytical dashboard like Arize to track a live enterprise assistant application. The dashboard captures a sudden spike in response latency and traces the root cause to a slow database query.

The layered infrastructure stack displaying interconnected modules for memory, vector stores, prompt management, and observability tools.
6. LLM Orchestration vs AI Workflow Automation vs AI Agents Comparision
As organizations plan their long-term digital transformations, choosing the right automation pattern for specific business challenges can be difficult. While some tasks need fixed, step-by-step logic, others require high autonomy to handle unpredictable inputs and real-time conditions. Comparing these three primary design patterns directly helps decision-makers invest in the right framework for their operational needs.
| Feature / Criteria | LLM Orchestration | AI Workflow Automation | AI Agents |
| Definition | Connecting and managing models, data systems, and tools. | Executing structured business logic assisted by AI models. | Autonomous digital entities executing tasks via iterative planning. |
| Main Purpose | Synchronizing complex data flows and multi-model interactions. | Accelerating repetitive enterprise processes with fixed outcomes. | Resolving open-ended goals with minimal human intervention. |
| Decision-Making | Algorithmic routing based on real-time model outputs. | Fixed, deterministic pathways predefined by software developers. | High autonomy; self-directed planning and tool selection loops. |
| Workflow Complexity | Highly dynamic; paths change based on conversational context. | Rigid and linear; adheres strictly to branching logic conditions. | Iterative and unpredictable; adapts dynamically to failures. |
| Tool Usage | Managed and brokered through a central integration layer. | Hardcoded integrations triggered at specific process steps. | Selected and executed dynamically by the agent based on intent. |
| Human Involvement | Low to medium; focuses on configuring architecture and guards. | Low; requires intervention only during process exceptions. | Low; acts independently and checks in primarily upon completion. |
| Best Use Case | Multi-model applications requiring deep contextual data. | High-volume data entry, document routing, and simple sorting. | Complex software engineering, market research, and optimization. |
| Example | An enterprise assistant querying multiple software platforms. | Automated invoice data extraction and processing systems. | An autonomous researcher finding and analyzing competitive data. |
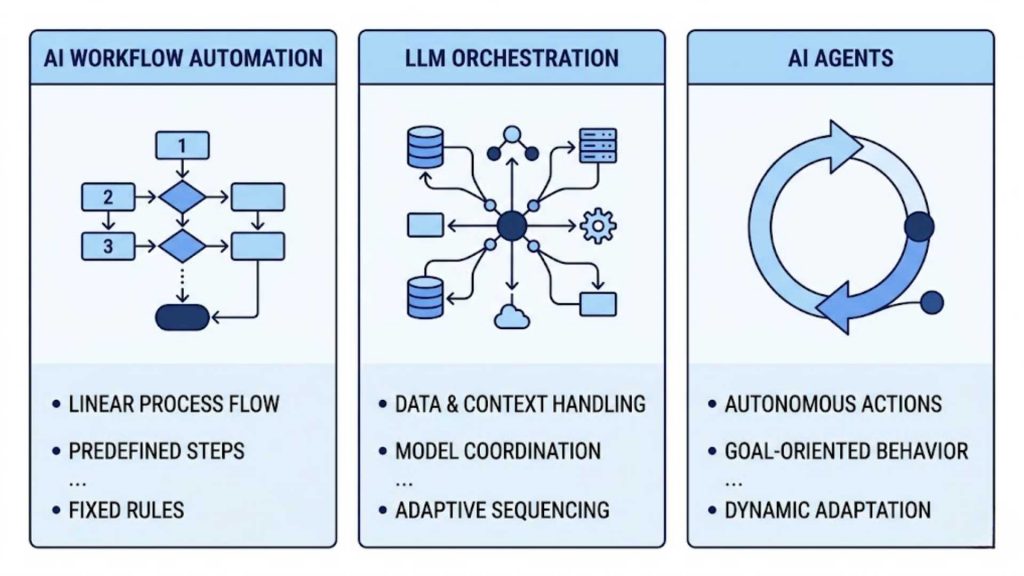
A comprehensive structural table evaluating the differences in decision-making, autonomy, and use cases across automated architectures.
7. Implementing LLM Orchestration in Applications
Transitioning an orchestrated concept from a local development environment into a scalable production system involves solving several practical engineering problems. Teams must build reliable data connections, manage data state carefully, and ensure the entire app remains safe against data leaks. Walking through a real-world example across the core development stages shows how to successfully launch these advanced applications.
7.1. Designing the Orchestration Workflow
Building a production-ready application requires mapping out the execution graph and defining clear boundaries for model interactions. For example, a customer service system must be designed to parse user intent, evaluate sentiment, and route requests to specialized sub-routines. Developers must establish explicit conditional logic to handle unexpected inputs or failures safely, ensuring that the system remains stable regardless of user behavior.
7.2. Integration of External Data Sources
To ground the application in accurate business context, developers must establish robust data pipelines connecting to internal repositories. Consider a financial advisory application that connects to real-time market feeds and historical investment databases. The orchestration layer must securely connect to these APIs, parse incoming data structures, and format the results into clear, concise context windows that the language model can easily interpret.
7.3. State Management Across Interactions
Maintaining state across long, multi-step conversations requires a reliable caching and database architecture. In a multi-step travel booking assistant, the system must securely store user preferences, flight choices, and payment selections as the user navigates the booking process. The orchestration layer saves these variables to a persistent data store, updating the active context window with each interaction to prevent memory loss.
7.4. Performance Monitoring and Optimization
Once an application goes live, teams must continuously track telemetry data to maintain fast response times and low operational costs. For instance, developers can monitor an e-commerce product recommendation agent to identify bottlenecks in vector database lookups or long API call times. By analyzing these interaction logs, engineers can optimize prompt layouts, implement smart caching, and fine-tune routing logic to maximize system efficiency.
7.5. Ensuring Scalability
As user traffic grows, the orchestration architecture must scale up gracefully without dropping connections or causing spikes in response times. For a global logistics platform processing thousands of inventory queries simultaneously, a centralized framework must handle concurrent operations effortlessly. Teams can maintain reliable performance by decoupling heavy processing tasks, deploying distributed queues, and using elastic computing resources.
7.6. Security and Privacy
Protecting sensitive corporate data and user information is a foundational requirement when deploying orchestrated applications in production environments. An automated healthcare document analyzer, for example, must scrub personally identifiable information (PII) before routing data to public model endpoints. Implementing role-based access controls, auditing API calls, and enforcing strict data compliance ensures that the orchestration layer remains secure.

An engineering lifecycle blueprint detailing design, security integration, and scalability optimization phases for enterprise deployments.
8. Use Cases for LLM Orchestration
Orchestrated language models are driving major efficiency gains across a wide range of industries, including healthcare, global logistics, and finance. By connecting core model capabilities with internal databases, companies can automate tasks that used to require hours of manual work. Examining these diverse enterprise use cases highlights how orchestration delivers measurable business value day in and day out.
8.1. AI Copilots and Enterprise Assistants
Enterprise copilots use orchestration frameworks to break down vague user requests into precise technical tasks across internal corporate software. By connecting to enterprise resource planning (ERP) platforms and customer relationship management (CRM) systems, these assistants can pull up data, generate reports, and update account statuses across departments. This centralized approach eliminates manual data silos and lets employees access complex business info using natural language. Microsoft reported that nearly 90% of surveyed workers wanted AI assistance to reduce repetitive tasks
8.2. IT Incident Response Automation
When critical IT infrastructure fails, orchestrated workflows can immediately ingest system alerts, query log files, and isolate root causes without human delay. The system can run diagnostics, check recent code deployments, and route urgent remediation tickets to the right on-call engineering teams. This automated response significantly lowers mean time to resolution (MTTR) and keeps core business operations running smoothly.
8.3. Customer Support and Ticket Routing
High-volume customer support operations rely on orchestration to process complex customer issues that extend beyond standard FAQs. The orchestration layer analyzes the emotional sentiment of incoming emails, references historical purchase records, and triggers account lookups to address issues directly. If a problem requires manual review, the system automatically packages the conversation history and hands it off to a human agent, minimizing resolution delays.
Cisco reported that its AI-powered intelligent routing system correctly routed nearly 88% of approximately 1.5 million annual customer service cases on the first attempt, reducing redundant handoffs and improving customer experience.
8.4. Financial Compliance Workflows
Financial institutions use orchestrated systems to automate complex auditing and fraud detection routines across multiple transaction networks. The platform can pull real-time transaction data, cross-reference it with regulatory guidelines, and flag anomalies for compliance officers to review. This continuous automated oversight helps firms avoid compliance penalties, protect consumer accounts, and scale operations without exponentially increasing headcount.
For example, Complidata uses generative AI to perform trade finance document reviews and compliance checks, reducing document examination time from hours to seconds while automating more than 1,000 validation checks.
8.5. Healthcare Document Processing
Processing medical records and clinical trial documents requires extracting unstructured text from various sources while maintaining strict data privacy. Orchestration frameworks guide medical data through text extraction, medical term verification, and structured categorization routines. This automated pipeline gives doctors summarized, highly accurate patient histories faster, reducing paperwork overhead and allowing them to focus more on patient care.
In practice, healthcare provider Omega Healthcare reported processing more than 100 million transactions through AI-powered document automation, saving over 15,000 employee hours per month and reducing turnaround times by approximately 50%.
8.6. AI Agent Workflow Automation
Modern automated AI systems require scalable inference infrastructure for dynamic AI workloads and API-driven applications. When running multiple specialized agents, developers use advanced solutions like Serverless Inference from FPT AI Factory to manage resource distribution dynamically. This architecture handles fluctuating API traffic smoothly, scaling computing resources up during busy processing periods and scaling down during lulls to maximize efficiency.
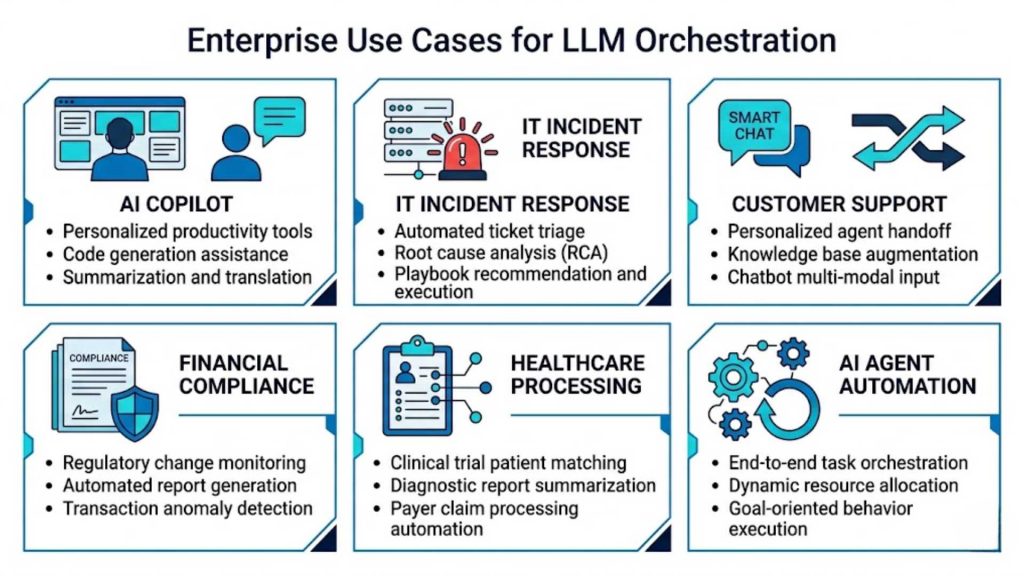
A clear visual layout mapping real-world applications across financial compliance, customer service, healthcare processing, and IT operations.
9. Infrastructure Considerations for LLM Orchestration
Running multi-step orchestration chains creates heavy computing workloads that can strain standard corporate cloud setups. To prevent slow response times and keep computing costs under control, companies need specialized hardware optimized for rapid AI math. Evaluating your core infrastructure choices ensures your applications stay highly responsive and efficient as user demand grows.
9.1. GPU Infrastructure and Scaling
Running complex LLM orchestration frameworks requires enterprise-grade infrastructure capable of supporting high-performance inference, multi-model serving, vector retrieval, containerized deployment, and continuous monitoring. As orchestration pipelines become more sophisticated, organizations need scalable GPU resources that can handle concurrent requests while maintaining low latency and high throughput.
FPT AI Factory provides an integrated AI infrastructure stack designed for these workloads. Serverless Inference enables low-latency model serving without infrastructure management, while GPU Container supports multi-model deployment and containerized AI applications. For enterprises requiring dedicated, isolated environments, GPU Virtual Machine delivers flexible GPU resources, and AI Notebook provides a GPU-powered development workspace for building, testing, and optimizing orchestration pipelines. Together, these services help organizations deploy production-ready LLM orchestration systems across the entire AI lifecycle.
Furthermore, FPT AI Factory has officially launched its next-generation AI infrastructure powered by NVIDIA HGX B300 GPUs, purpose-built for reasoning and agentic AI workloads. Built on the NVIDIA Blackwell Ultra architecture, each GPU offers 288 GB of memory, with up to 2.1 TB of GPU memory per node, enabling trillion-parameter models and long-context inference with fewer bottlenecks. The platform also delivers up to 1.5× higher dense FP4 performance, up to 66% lower inference costs, and significant cost-per-token optimization, making it well suited for enterprise-scale LLM orchestration and multi-agent AI applications.

FPT AI Factory’s NVIDIA HGX B300 infrastructure powers next-generation enterprise AI workloads.
9.2. Latency and Inference Optimization
Multi-turn conversational chains can introduces noticeable delays if the underlying computing infrastructure is not optimized for streaming data. Developers must use model acceleration techniques like quantization, speculative decoding, and optimized key-value caching to keep response times fast. Minimizing physical network distance between orchestration engines and inference endpoints ensures a fluid, near-instant user experience.
9.3. Multi-Model Serving Environments
As applications grow more complex, single-model architectures often become too rigid and costly, prompting a shift toward multi-model setups. An optimized architecture routes simple text processing to lightweight models while saving complex logical reasoning tasks for large foundational models. Managing this hybrid setup requires an infrastructure layer that can load, run, and swap multiple model weights dynamically without causing system downtime.
9.4. Security and Access Control
Operating AI orchestrators across enterprise networks requires strict security controls to safeguard sensitive data and proprietary code. Companies must implement granular access permissions, isolate multi-tenant computing environments, and encrypt data both in transit and at rest. These protective measures keep corporate data isolated and secure, preventing unauthorized access and mitigating data leak risks.
9.5. Monitoring, Logging, and Observability
Maintaining deep visibility into system infrastructure is vital for troubleshooting complex bugs and tracking system health over time. Engineers need comprehensive logging pipelines to capture system outputs, track database lookups, and monitor infrastructure health in real time. This detailed tracking lets teams spot performance drops early, optimize resource use, and keep applications running reliably.
9.6. Cost Management and Token Usage Optimization
Because orchestrated applications frequently run recursive loops and query multiple data sources, unoptimized token consumption can quickly drive up operational costs. Teams must implement smart chunking methods, optimize prompt layouts, and set up precise execution limits to control costs. Using tiered memory storage and caching common search queries also helps reduce total API usage, making large-scale deployments financially sustainable over the long term.

A technical hardware layout mapping distributed GPU workloads, elastic virtual scaling, and multi-model environment management. (Source: FPT AI Factory)
10. FAQs
10.1. What is the difference between LLM orchestration and AI workflow automation?
LLM orchestration dynamically manages real-time data and conversational reasoning paths based on natural language inputs. In contrast, AI automation follows fixed logic paths to complete repetitive tasks using models only for simple extraction.
10.2. What are common LLM agent orchestration patterns?
Common patterns include sequential chains, intent routers, and supervisor structures. Chains process data linearly, routers delegate tasks by intent, and supervisors coordinate multiple sub-agents.
10.3. Which frameworks support LLM orchestration?
Popular choices include LangChain, LlamaIndex, AutoGen, and CrewAI. These tools provide pre-built abstractions to easily integrate vector databases and build multi-agent execution graphs.
10.4. Does orchestration improve AI scalability?
Yes, it improves scalability by decoupling application logic from model endpoints and distributing processing workloads. This efficient structure successfully prevents system overloads as user traffic scales up.
Building production-grade AI systems requires more than just calling foundational models; it demands a resilient orchestration layer that connects cognitive reasoning with structured business logic. By managing prompt state, retrieval systems, and external tools, orchestration turns standalone language models into dependable enterprise solutions. Partnering with the right infrastructure provider ensures your AI applications scale smoothly while remaining highly cost-effective.
Are you ready to build high-performance, orchestrated AI workflows for your enterprise operations? Access the FPT AI Factory Starter Plan today to redeem a free $100 credit allocation and launch your deployments instantly! This complimentary starter credit includes $10 for GPU Container allocations, $10 for GPU Virtual Machine nodes, $10 for interactive AI Notebook sessions, and $70 dedicated to high-speed AI Inference and AI Studio workflows.
For large-scale corporate deployments requiring custom technical support, dedicated hardware environments, or specialized architectures, please visit the official form on our website to connect with our enterprise solutions team.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more:
What is LLM Inference? How it works, metrics, and scaling


