
What is distributed machine learning and why is it a critical step in optimizing AI models for specific tasks? Understanding this approach helps businesses improve model accuracy, adapt to domain-specific data, and unlock better performance in real-world applications. At FPT AI Factory, we deliver advanced AI solutions that empower organizations to leverage distributed training effectively within their AI development workflows.
1. What Is Distributed Machine Learning?
Modern AI models require massive computing power to process billions of parameters. When datasets and architectures grow too large, standard single-hardware setups face severe memory and processing bottlenecks. Distributed machine learning solves this problem by dividing heavy computational tasks among interconnected resources.
At its core, distributed machine learning means training AI models across multiple GPUs, servers, or compute nodes simultaneously. Instead of relying on a single machine, this method breaks the training workload down to execute operations concurrently. This collective infrastructure allows teams to easily handle workloads that a single system cannot process.
Imagine you need to read and summarize a massive 10,000-page book:
- Traditional Way: One person reads the entire book from start to finish. They will take months to complete it, or face severe information overload and stop completely.
- Distributed Way: You split the book into 10 sections and give them to 10 people to read at the same time. Afterward, you combine their findings into one final summary, drastically saving time.
This approach is essential because it overcomes the physical memory limits of individual graphics cards. By pooling computational resources, organizations accelerate their development cycles and bring AI products to market faster. Without it, training modern foundation models would require years of slow, sequential computing.

High-performance AI model training executed concurrently across multiple distributed GPU compute nodes and servers.
2. How Distributed Machine Learning Works
The mechanics of distributed training rely on systematic orchestration to ensure that separate hardware units function as a cohesive ecosystem. This process requires precise scheduling, data partitioning, and constant communication between all participating nodes. By coordinating these elements, the system achieves massive computational throughput without losing data integrity.
2.1 Splitting the training workload
The initial step requires dividing the workload into manageable portions that can be distributed across the infrastructure. Depending on the chosen strategy, the system partitions either the massive dataset into smaller batches or the model architecture itself into distinct layers. This allocation ensures that every available compute node receives a specific piece of the overall task to process.
Example: In an e-commerce project, a dataset of 10 million customer product reviews is chopped into 10 smaller batches of 1 million reviews each. These distinct text batches are then prepared for simultaneous allocation across different hardware units.
2.2 Running parallel computation across GPUs or nodes
Once the workload is partitioned, individual GPUs or compute nodes execute their assigned calculations simultaneously. Each node processes its allocated data or model layers independently, utilizing its local memory and arithmetic units to perform forward and backward passes. This parallel execution forms the foundation of the speed tracking benefits found in distributed environments.
Example: Ten separate GPU servers light up at the same moment, each independently analyzing its assigned batch of 1 million e-commerce reviews. This concurrent processing allows the system to compute linguistic patterns ten times faster than a single graphics card.
2.3 Synchronizing gradients or model parameters
Because individual nodes work on separate components, they must regularly exchange their findings to maintain model coherence. This step involves gradient synchronization, where nodes share the calculated mathematical adjustments across a high-speed network. Efficient communication protocols ensure that all separate computations are periodically aligned before moving forward.
Example: After processing a batch, each GPU broadcasts its localized learning notes and error corrections across an NVLink network. This instant data exchange ensures that what GPU 1 learned from its data batch is immediately shared with GPU 10.
2.4 Updating the model across distributed resources
After the gradients are successfully synchronized and aggregated, the global parameters of the machine learning model are updated. Every participating node adjusts its local version of the weights based on the combined intelligence gathered from the entire cluster. This step guarantees that the model advances uniformly across the infrastructure.
Example: The master framework combines the notes from all 10 hardware units and calculates a unified mathematical update. Every individual GPU then rewrites its local neural network model with these new, fully integrated intelligence weights.
2.5 Managing communication and coordination
The final ongoing element involves continuous orchestration to handle network traffic and reduce latency overhead during data transfers. Centralized schedulers or decentralized protocols manage the data packets traveling via interconnects, preventing data collisions and optimizing cluster efficiency. Proper coordination ensures that hardware units spend more time computing than waiting for network updates.
Example: A central software orchestrator acts like a digital traffic cop, managing the massive flow of mathematical data between nodes. It prevents network jams, ensuring no single GPU sits idly waiting for updates from slower servers.

The step-by-step distributed training workflow from workload partitioning to global gradient synchronization.
3. Types of Distributed Training Approaches
Selecting the appropriate training methodology depends heavily on the specific size of your dataset and the complexity of your neural network. Different strategies alter how workloads are distributed across your hardware cluster to maximize performance. Choosing the right approach prevents resource idling and optimizes overall training efficiency.
3.1 Data Parallelism
Data parallelism replicates the entire machine learning model across every single GPU or compute node within the infrastructure. Each individual worker processes a distinct portion of the dataset, executing forward and backward passes independently before synchronizing gradients globally. This method is highly effective when the model fits comfortably into a single GPU’s memory but the training dataset is exceptionally large.
Example: You clone a 7-billion parameter model onto four separate enterprise GPUs. Each individual GPU is then fed a different chunk of a massive 100GB text dataset to read and process simultaneously.
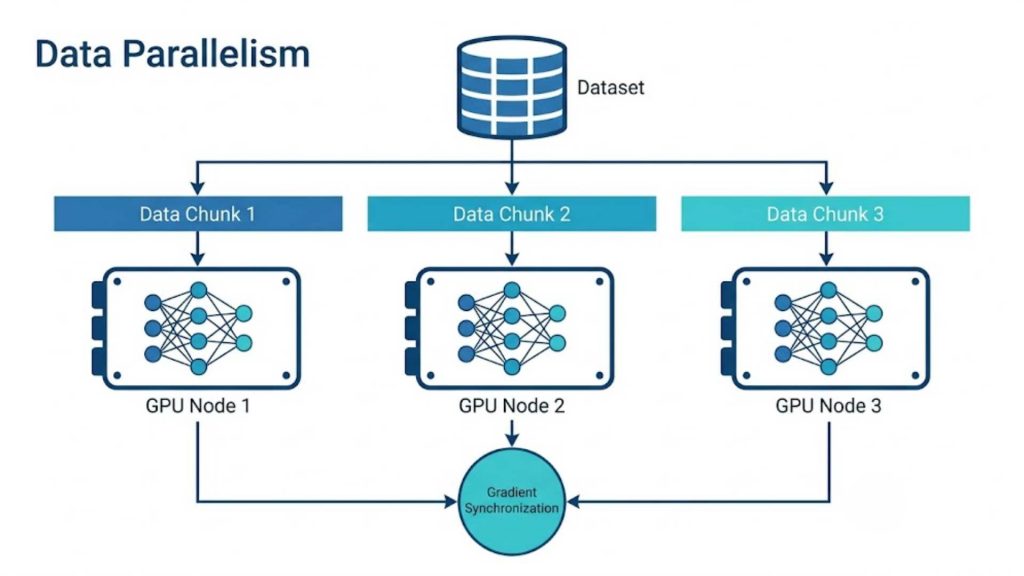
Data parallelism architecture replicating the complete AI model across separate GPUs to process distinct data chunks.
3.2 Model Parallelism
Model parallelism splits a large neural network into separate segments and distributes those pieces across multiple distinct processing units. This approach becomes necessary when a model is too massive to fit into the memory capacity of a single graphics card. Each node handles only its designated mathematical layers, collaborating with other nodes to complete a full training cycle.
Example: A massive 70-billion parameter model exceeds the memory limit of a single graphics card. You cut the model in half, placing layers 1 to 40 on GPU 1 and layers 41 to 80 on GPU 2.
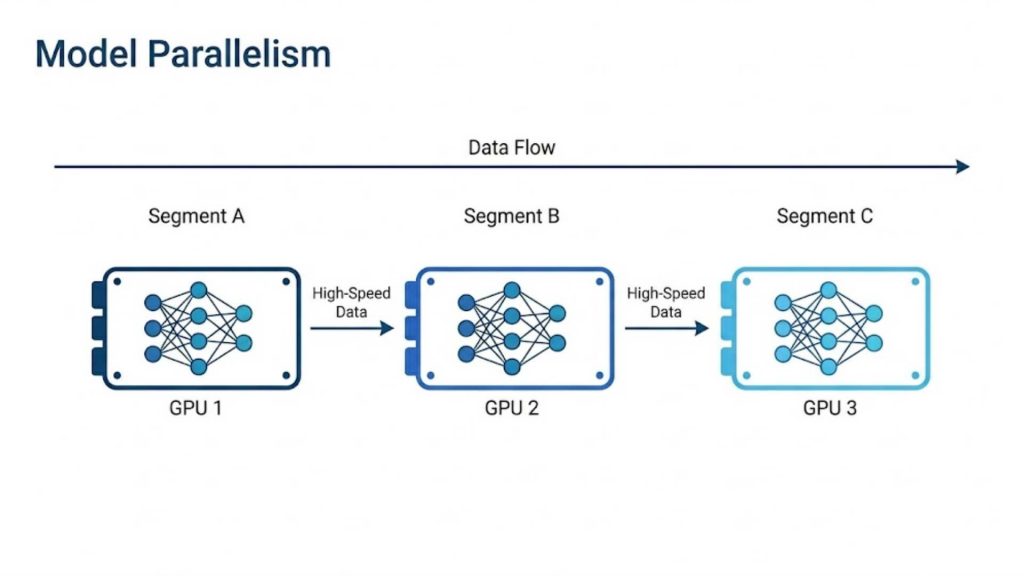
Model parallelism splitting a massive neural network architecture across multiple processing units due to memory limits.
3.3 Pipeline Parallelism
Pipeline parallelism divides model layers sequentially across a series of separate processors, creating an assembly line for training computations. As one GPU finishes processing an early layer for a batch of data, it passes the results to the next GPU while immediately starting on the next batch. This sequential streaming reduces idle time across nodes, maximizing hardware utilization.
Example: GPU 1 processes the first data batch through layers 1-40 and passes it to GPU 2. While GPU 2 works on that first batch, GPU 1 immediately starts processing the second data batch.
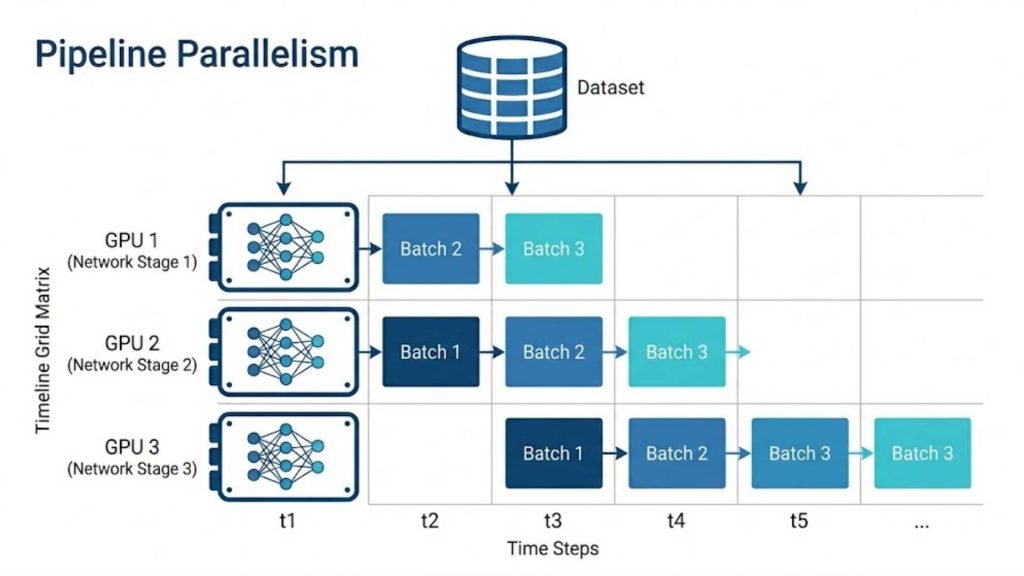
Pipeline parallelism executing sequential model layers across a GPU cluster like a continuous assembly line.
3.4 Hybrid Parallelism
Hybrid parallelism combines multiple distribution strategies, such as data and model parallelism, into a single integrated training workflow. This advanced technique is frequently utilized for training foundation models with hundreds of billions of parameters across massive server clusters. It allows developers to fine-tune resource allocation, balancing memory constraints with network communication speeds.
Example: In a massive cluster, you apply model parallelism by cutting a giant neural network across two GPUs. You then clone this exact two-GPU combination across dozens of server racks to process different data shards.
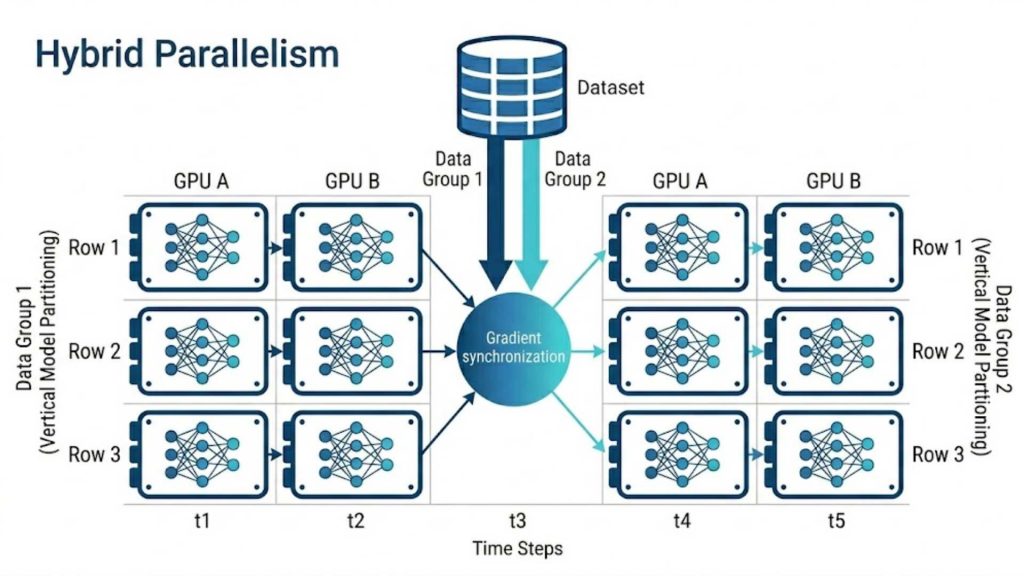
Hybrid parallelism combining data replication and model partitioning to optimize massive foundational AI training.
4. Frameworks for Distributed Machine Learning
Implementing distributed training requires specialized software frameworks that abstract the complexities of network communication and hardware coordination. These tools provide libraries to easily scale workloads from a single machine to thousands of nodes. Utilizing established frameworks ensures stability and optimal performance during complex AI training sessions.
4.1. PyTorch Distributed
PyTorch Distributed provides native, high-performance modules like DistributedDataParallel (DDP) to handle parallel computations with minimal configuration overhead. It is widely favored by research teams and enterprises alike due to its dynamic computational graphs and strong ecosystem integration. The framework excels at optimizing communication across distributed GPU setups.
4.2. TensorFlow Distributed
TensorFlow Distributed utilizes structured training strategies to scale models across various hardware configurations seamlessly. Its built-in APIs allow developers to distribute tasks using mirrored variables or parameter server architectures depending on their infrastructure design. This flexibility makes it a reliable choice for production-grade machine learning systems.
4.3. Ray
Ray is an open-source unified compute framework designed to scale Python applications and machine learning workloads efficiently. It simplifies the process of distributing data processing, hyperparameter tuning, and model training across large clusters. Its flexible actor model allows engineers to build highly customized distributed applications.
4.4. Apache Spark
Apache Spark focuses on large-scale data processing and distributed computing, making it ideal for managing heavy data pipelines. When integrated with machine learning libraries, it enables organizations to clean, transform, and analyze multi-terabyte datasets before training. Its memory-centric design ensures rapid data iteration across clusters.
4.5. Horovod
Horovod is a distributed deep learning training framework originally developed by Uber to make parallel training easier to implement. By leveraging efficient ring-allreduce communication algorithms, it drastically reduces the time spent on network synchronization between nodes. It plugs smoothly into existing PyTorch and TensorFlow scripts with minimal alterations.
4.6. DeepSpeed
DeepSpeed is a specialized deep learning optimization library developed by Microsoft that enables unprecedented scale and speed for model training. It introduces innovative memory optimization techniques, such as the ZeRO (Zero Redundancy Optimizer) protocol, to significantly reduce memory consumption. This framework allows teams to train massive models using standard hardware configurations.
Leading enterprise software frameworks and libraries optimized for large-scale distributed machine learning orchestration.
5. Distributed Machine Learning vs Traditional Machine Learning
Understanding the operational differences between these two methodologies helps organizations choose the right infrastructure strategy for their projects. While traditional approaches offer simplicity, distributed setups provide the raw power needed for scaling. The table below outlines the core distinctions across key technical criteria.
| Criteria | Traditional Machine Learning | Distributed Machine Learning |
| Training setup | Single-node execution on a single machine | Multi-node execution across clusters |
| Compute resources | Single CPU or a single GPU | Multiple GPUs, servers, or hardware nodes |
| Dataset size | Limited to local storage or memory capacity | Scalable across massive, multi-terabyte datasets |
| Model size | Small to medium architectures | Large-scale foundational architectures |
| Training speed | Slower; sequential processing bottlenecks | Highly accelerated via parallel computing |
| Scalability | Strictly limited by single-hardware constraints | Highly scalable by adding more compute nodes |
| Infrastructure complexity | Low; simple configuration and deployment | High; requires network orchestration tools |
| Cost considerations | Lower upfront cost; bounded resource usage | Higher infrastructure investment; highly cost-efficient at scale |
| Best use cases | Prototyping, tabular data, simple analytics | Generative AI, LLMs, computer vision at scale |
| Example workloads | Scikit-learn regressions, small XGBoost models | Training Llama architectures, large ResNet models |
In conclusion, while traditional machine learning remains effective for smaller, isolated datasets and simpler model structures, it introduces severe bottlenecks when scaling up. Distributed machine learning breaks through these limits by providing the parallel architecture needed to process cutting-edge enterprise AI. Transitioning to a distributed environment represents a crucial step for companies aiming to leverage high-performance foundation models.
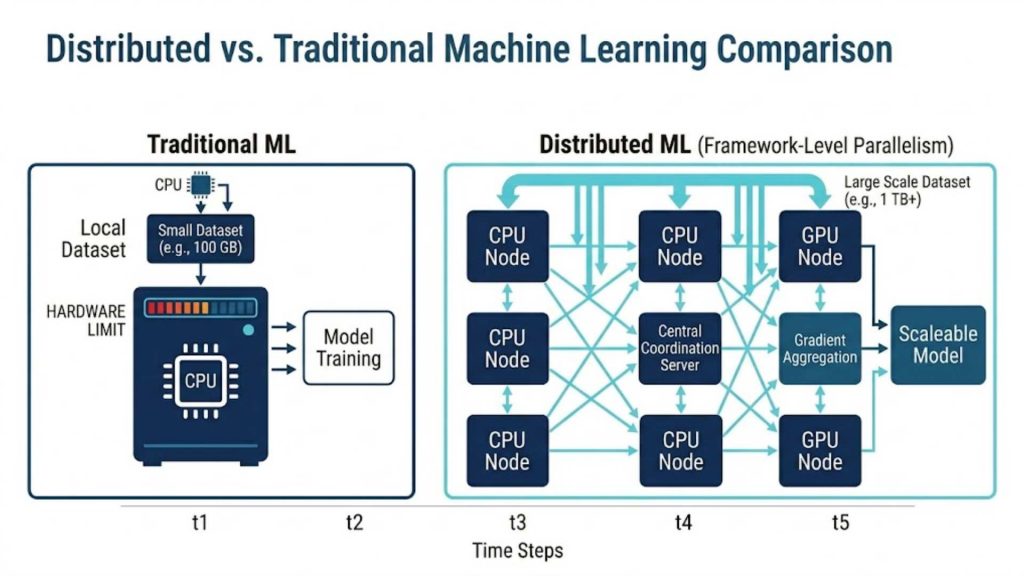
Architectural comparison highlighting the scalability and speed differences between single-node and multi-node training.
6. Benefits of Distributed Machine Learning
Embodying a distributed infrastructure yields profound performance advantages that directly impact an organization’s production timeline. By moving away from single-node computing, development teams can bypass traditional resource barriers entirely. This approach unlocks substantial gains in efficiency, hardware longevity, and model optimization.
- Faster training times: Parallel processing dramatically decreases the time required to complete training cycles from weeks to hours.
- Scalability for large models: Breaking up neural networks allows engineering teams to train architectures that exceed single-device limits.
- Better GPU utilization: Smart workload distribution prevents expensive hardware components from sitting idle during data ingestion.
- Support for massive datasets: Systems can stream and analyze massive, distributed datasets without overloading system memory.
- Reduced training bottlenecks: Efficient communication protocols minimize synchronization delays, streamlining the overall workflow.

Core efficiency gains achieved through parallel distributed computing, including faster training and optimized GPU utilization.
7. Use Cases for Distributed Machine Learning
The practical applications of distributed architectures cross numerous industries, driving breakthrough innovations in complex data environments. Enterprises leverage these parallel networks to solve problems that demand intense mathematical processing. Examining these use cases reveals how distributed computing transforms theoretical AI into scalable reality.
7.1. Generative AI applications
Creating highly realistic images, synthetic audio, and complex digital assets requires processing diverse multimedia data. Distributed setups enable generative models to analyze millions of style variants concurrently, improving synthesis quality. This accelerated workflow helps digital creators build high-end commercial imagery and production-ready videos efficiently.
Under standard conditions, training advanced video or high-resolution image generation models requires processing millions of heavy multimedia files. Without distributed computing, rendering and training times would stretch boundlessly.
Looking at major market models, OpenAI’s video generation model, Sora, along with frameworks like Stable Diffusion XL, rely on massive cluster scaling. Industry reports indicate that models of this scale require distributed clusters of thousands of NVIDIA H100 GPUs running continuously for weeks to handle billions of video frames, reducing training time from an estimated single-machine “decades” to just a matter of days. (Source: OpenAI Technical Reports / Factorial Funds Research)
7.2. Medical imaging and healthcare AI
Analyzing high-resolution 3D medical scans, such as MRIs and CT examinations, requires processing immense data files. Distributed infrastructure allows healthcare models to train on massive medical image registries across multiple secure servers simultaneously. This approach improves diagnostic accuracy and accelerates the discovery of localized pathologies.
In the medical sector, imaging AI requires training on massive, multi-gigabyte 3D datasets while strictly complying with patient data privacy regulations across different hospital networks.
To address this challenge, Google Health and the National Institutes of Health (NIH) utilize distributed and federated learning setups to train diagnostic models. By distributing workloads across multiple nodes, systems processed over 118,000 chest X-ray images simultaneously to detect lung diseases, improving classification accuracy by over 15% without moving sensitive data out of local hospital storage. (Source: Google Health Research / NIH Data Management)
7.3. Large language model training
Modern language models contain hundreds of billions of parameters, necessitating robust hardware setups for token processing. Distributed AI workloads require scalable GPU compute environments with high-speed interconnects. Utilizing an advanced infrastructure service like GPU Virtual Machine from FPT AI Factory ensures that large language models process extensive text corpora smoothly across clustered systems. In the near future, FPT AI Factory will offer services with the HGX B300 GPU, providing significantly improved performance.
On an industrial scale, foundational text models contain hundreds of billions of parameters and tokens, making them far too massive to fit into the memory of any single computing unit.
Mirroring this exact technical requirement, Meta’s Llama 3 model was trained using highly optimized distributed training strategies. Meta utilized a massive cluster of 24,576 NVIDIA H100 GPUs connected via high-speed RoCE networks to process a dataset of 15 trillion tokens. Distributed infrastructure allowed them to maintain over 95% training uptime and complete the massive computational workload in a fraction of the time. (Source: Meta AI Llama 3 Technical Performance Report)
7.4. Recommendation systems
E-commerce platforms and streaming networks analyze billions of consumer interactions daily to serve personalized content suggestions. Distributed learning allows these recommendation engines to update their parameters continuously across massive user databases. This immediate processing ensures consumers receive accurate suggestions, enhancing platform engagement.
For modern digital platforms, algorithms must process hundreds of millions of active user clicks, streams, and purchase events every second to refresh user feeds in real time.
Driven by this rapid data processing need, Netflix uses distributed machine learning frameworks to run its recommendation algorithm, which drives up to 80% of the content watched on the platform. Their distributed system updates personalization parameters across a user base of over 260 million subscribers daily, processing petabytes of streaming interaction data to dynamically serve tailored content within milliseconds. (Source: Netflix Tech Blog)
7.5. Scientific computing and HPC workloads
Fields like climate modeling, molecular dynamics, and physics simulations rely heavily on High-Performance Computing (HPC). Distributed training structures process complex differential equations and multi-dimensional datasets across clustered nodes rapidly. This computational throughput allows scientists to execute intricate simulations with superior resolution.
In the scientific community, global weather forecasting and molecular simulation require solving complex, multi-dimensional mathematical equations across planetary-scale datasets.
Achieving this level of precision, the European Centre for Medium-Range Weather Forecasts (ECMWF) utilizes distributed deep learning models running on supercomputing clusters. By processing over hundreds of terabytes of satellite and atmospheric data simultaneously across distributed nodes, their AI systems generate highly accurate 10-day global weather forecasts in under 10 seconds, outperforming traditional numerical prediction software. (Source: ECMWF AI Initiatives Report)

Practical enterprise applications of distributed learning crossing generative AI, medical imaging, and large language models.
8. Infrastructure Challenges in Distributed Machine Learning
Deploying a multi-node cluster introduces specialized technical hurdles that require constant monitoring and deliberate engineering design. Without a well-orchestrated infrastructure, network latency can easily degrade the performance speed gained from parallelization. Organizations must carefully address these complex operational obstacles to achieve stable and cost-efficient results.
- Cluster Coordination & Orchestration: Coordinating multiple GPUs, servers, or compute nodes requires sophisticated cluster management software. Handling cluster orchestration and job scheduling demands automated tools to distribute workloads fairly across the entire infrastructure.
- Network & Bandwidth Bottlenecks: Managing network latency is crucial to prevent processors from waiting on data. This requires high-speed interconnects such as NVLink or InfiniBand to ensure rapid, seamless data exchange between nodes.
- Data Pipelines & Storage Failures: Maintaining fast storage and reliable data pipelines prevents input/output operations from stalling training. Additionally, managing failed nodes, retries, and checkpointing protects progress by allowing training to resume smoothly after errors.
- Performance Monitoring & Cost Control: Monitoring GPU utilization, memory usage, and training performance helps teams identify and eliminate systemic inefficiencies. This constant oversight is essential for controlling infrastructure cost and avoiding underused GPU resources through precise capacity planning.

Key hardware and network challenges encountered when managing communication and data storage in multi-node clusters.
9. Distributed Machine Learning Infrastructure Requirements
Building a scalable distributed machine learning environment requires more than adding GPUs. Organizations need an integrated infrastructure that combines compute, networking, storage, and management capabilities to support demanding AI workloads.
- Compute Infrastructure: Distributed machine learning relies on high-performance GPU clusters capable of handling large-scale model training and inference. Flexible GPU resources allow organizations to scale compute capacity according to project requirements while reducing hardware management complexity.
- High-Speed Networking: Fast communication between compute nodes is critical for distributed training efficiency. Technologies such as NVLink and InfiniBand help reduce synchronization delays and support rapid data exchange across GPU clusters.
- Distributed Storage Systems: Large AI datasets require storage platforms that deliver high throughput and low latency. Distributed storage systems ensure that compute nodes can access training data efficiently while maintaining redundancy and reliability.
- Orchestration and Cluster Management: Managing distributed AI infrastructure requires orchestration tools that automate resource allocation, workload scheduling, and cluster operations. These capabilities simplify infrastructure management and improve resource utilization across complex environments.
- Monitoring and Resource Optimization: Comprehensive monitoring provides visibility into infrastructure health, GPU performance, storage activity, and network utilization. Resource optimization helps organizations maximize hardware efficiency while controlling operational costs.
Modern AI platforms increasingly integrate these infrastructure components into unified environments. FPT AI Factory, for example, provides a range of services designed to support distributed machine learning workloads, including GPU Cluster for large-scale distributed training, GPU Container for flexible on-demand AI development environments. By providing compute, networking, and management capabilities within a single ecosystem, the platform helps organizations simplify AI deployment and accelerate the development of large-scale machine learning applications.

Distributed machine learning infrastructure requirements
10. FAQs
10.1 What is the difference between data parallelism and model parallelism?
Data parallelism replicates the entire model across multiple GPUs, with each unit processing a separate slice of the training data. Model parallelism splits the actual neural network layers across separate processors because the architecture is too large for one GPU’s memory.
10.2 Which frameworks support distributed ML?
Popular enterprise frameworks that natively support distributed training include PyTorch Distributed, TensorFlow Distributed, DeepSpeed, Ray, Horovod, and Apache Spark. These libraries abstract network communications to simplify scaling workloads across clusters.
10.3 Does distributed training reduce training time?
Yes, distributed training substantially reduces overall training time by executing mathematical computations in parallel across multiple GPUs. This acceleration allows complex AI models to finish training cycles in hours rather than weeks.
Scaling your artificial intelligence initiatives requires robust infrastructure built to handle intense parallel computations. Distributed machine learning overcomes hardware limitations, accelerating training timelines and unlocking the power of massive datasets. Selecting the right processing ecosystem ensures your models deploy efficiently without budget overruns.
Ready to accelerate your AI development? FPT AI Factory is currently offering a $100 free trial credit program for users to explore the platform. New users get $10 for GPU Container, $10 for GPU Virtual Machine, $10 for AI Notebook, and $70 for AI Inference & AI Studio with access to Llama-3.3 and over 20 advanced models for 30 days.
For enterprises and organizations requiring customized, large-scale deployments, please fill out the contact form on our website to receive specialized consulting from our technical experts.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Read more:
Bare Metal vs Virtual Machine: Which Is Better for AI?
GPU Virtual Machine: Benefits, Use Cases, and How It Works
Edge Computing vs Cloud Computing: Key Differences
Top Cloud Service Providers with GPU for AI Workloads


