
Supervised fine-tuning is a key technique for adapting AI models to real-world business needs, enabling more accurate and task-specific outputs. By learning from labeled datasets, models can align better with domain knowledge and user expectations. At FPT AI Factory , enterprises can leverage scalable infrastructure and tools to implement supervised fine-tuning efficiently.
1. What is supervised fine-tuning?
Supervised fine-tuning is a technique used to adapt pre-trained language models to specific tasks by training them on labeled input–output data. While foundation models learn general knowledge from large datasets, fine-tuning helps them produce more accurate, consistent, and task-specific responses.
For example, Shopify can fine-tune a language model using labeled customer support data from its merchants, such as a customer asking “Where is my order?” paired with the correct response explaining tracking details or delivery timelines. After fine-tuning, the model can generate accurate, policy-aligned replies instead of generic answers, helping automate support at scale.
This process enables the model to move from general-purpose understanding to more reliable performance in real-world applications, as long as high-quality labeled data is available.
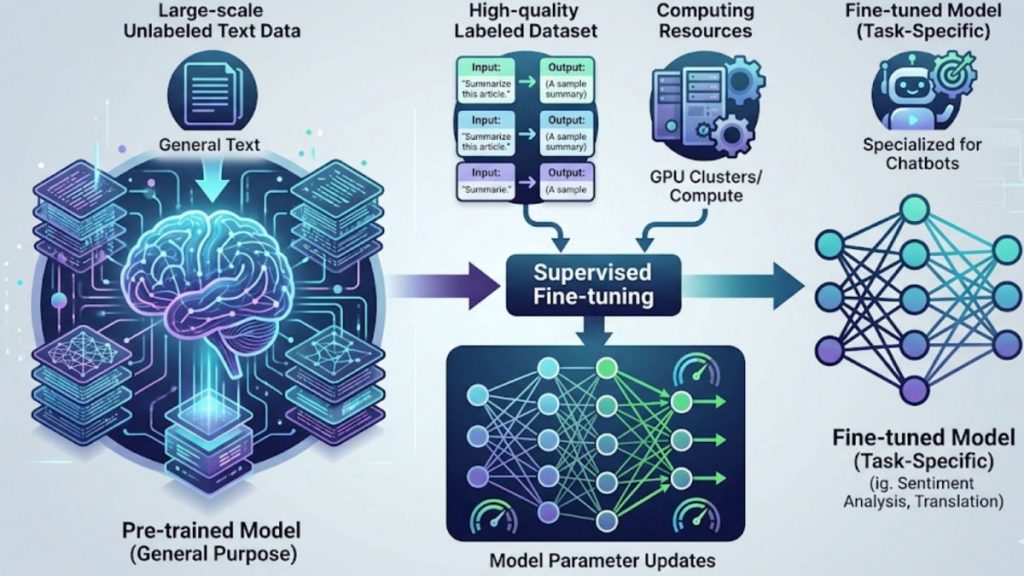
Fine-tuning of pre-trained models using labeled data for better task performance
>> Explore more: Prompt Engineering vs Fine-tuning: A Guide to better LLM
2. How does supervised fine-tuning work?
Supervised fine-tuning adapts a pre-trained model to specific tasks using labeled data, improving accuracy without the need to train from scratch. By learning from structured input – output examples, the model not only generates more precise results but also aligns better with expected behavior in real-world scenarios, making it well-suited for applications such as automation, virtual assistants, and data processing systems.
The process typically includes three main steps:
- Pre-training foundation model: A large model is first trained on massive, general datasets to capture broad knowledge across different domains
- Data collection and labeling: Task-specific data is gathered, cleaned, and labeled to reflect real use cases and expected outputs
- Fine-tuning and adaptation: During supervised fine-tuning, the model updates its parameters to improve performance on specific tasks. However, excessive specialization or narrow datasets may reduce some general capabilities, requiring careful tuning and evaluation.
In practice, supervised fine-tuning requires computational resources such as GPUs and suitable AI development environments to train models effectively. Even when dedicated fine-tuning services are not directly used, businesses can still implement the process by leveraging GPU infrastructure or AI Notebook platforms to run training workflows and manage experiments efficiently.
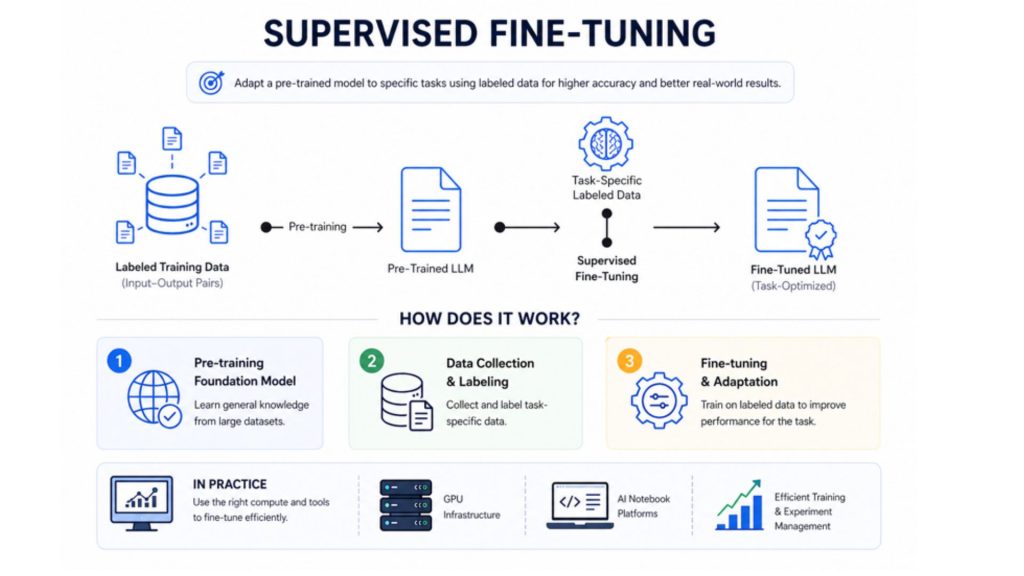
A pre-trained model is improved by training on labeled examples for targeted tasks
3. Supervised fine-tuning vs. prompt engineering vs. RAG
These three approaches solve different needs in AI development. Instead of replacing each other, they are often combined to build more powerful and practical AI systems.
| Comparison Criteria | Supervised Fine-Tuning | Prompt Engineering | RAG (Retrieval-Augmented Generation) | |
| What it changes (core difference) | Changes model behavior by learning new patterns | Controls output without changing the model | Adds external knowledge without retraining the model | |
| How it works | Trains on labeled input–output examples | Uses instructions written in prompts | Retrieves relevant external data and injects into prompt | |
| Data requirement | Requires labeled datasets | No training data required | Requires external data sources | |
| Model behavior change | Model behavior is permanently updated | No model change, only temporary output control | No model change, context added per request | |
| Best-fit use cases | Structured tasks, domain-specific behavior | Quick response control and prompt-based tuning | Knowledge-heavy or frequently updated information | |
| Cost and complexity | Higher due to training process | Low cost and easy to implement | Medium due to retrieval system setup | |
| Example | – A customer support team fine-tunes a model using past chat logs so it learns the company’s tone, escalation rules, and standard answer format.
– When users ask about orders, refunds, or warranties, the model responds consistently in the brand’s support style. |
– A support team writes a prompt such as: “Answer politely, keep responses under 80 words, and ask for the order ID if the customer asks about delivery.”
– The model follows these instructions during the conversation, but its behavior is not permanently changed. |
– A chatbot connects to the company’s order database and help center.
– When a customer asks, “Where is my order?”, the system retrieves the latest shipping status and return policy, then uses that information to generate an accurate response. |
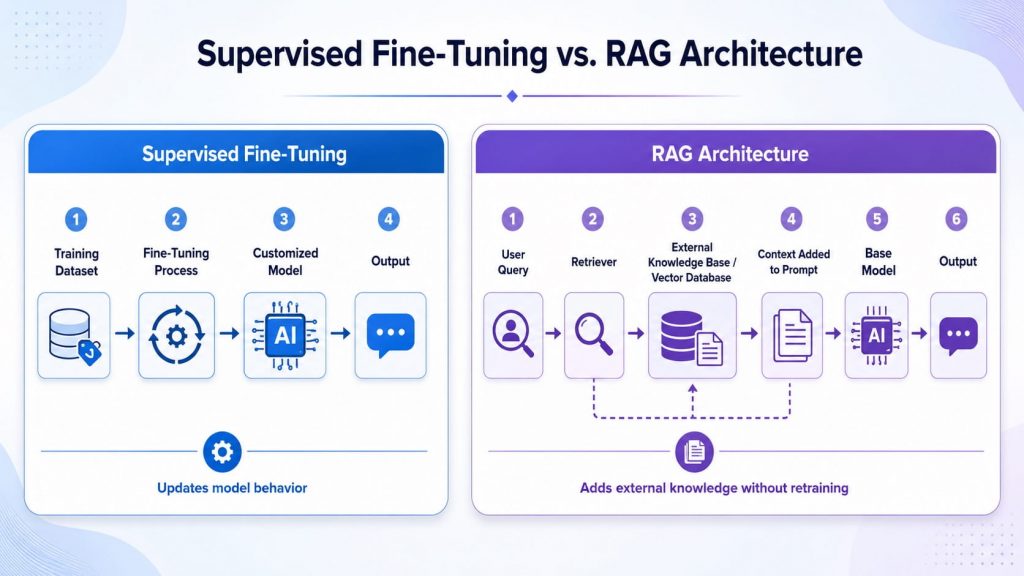
SFT updates the model through training, while RAG keeps the model unchanged and adds external knowledge at query time.
In real-world AI systems, these approaches are often used together: fine-tuning shapes the model’s behavior, prompt engineering controls how it responds, and RAG ensures responses stay updated with external knowledge.
>> Explore more: Prompt Engineering vs Fine-tuning: A Guide to better LLM
4. How supervised fine-tuning fits into the LLM alignment pipeline
Supervised fine-tuning is usually not the first or final step in building an aligned LLM. It often comes after pretraining and before preference optimization methods such as RLHF or DPO. This makes SFT an important bridge between a general-purpose pretrained model and an instruction-following model that can better serve real-world tasks.
- Pretraining: Builds the model’s general language and reasoning foundation from large-scale data.
- Supervised fine-tuning: Teaches the model to follow instructions and produce task-specific outputs using labeled examples.
- RLHF / DPO: Further refines model behavior using human preferences, rankings, or comparison data.
- Aligned LLM: Produces more helpful, consistent, and task-relevant responses for users.
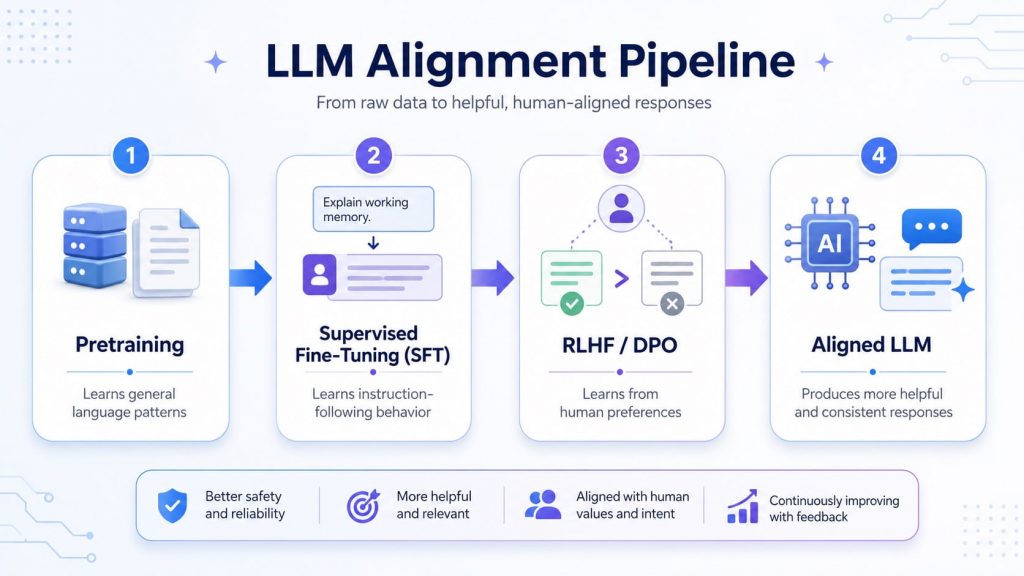
SFT helps turn a pretrained model into an instruction-following model before further alignment with RLHF or DPO.
5. Common use cases of supervised fine-tuning
Supervised fine-tuning is widely used to help AI models perform more accurately in specific business scenarios. It is especially valuable when organizations need consistent, task-oriented, and domain-aligned outputs.
5.1 Domain-specific assistants
These assistants are designed to support users in particular industries or internal systems where general responses are not enough. They help improve relevance and accuracy in specialized environments.
- Industry-focused chatbots designed for specific fields such as healthcare, finance, or retail
- Internal knowledge assistants that support employees with company-specific information
- Customer support systems that respond based on business workflows and policies
Example: A healthcare chatbot designed for diagnostic guidance and medical test consultation helps users check symptoms and receive appropriate test recommendations in real time, without waiting for human staff. By guiding users step-by-step through the consultation process, the system makes it easier for them to complete their decisions. After implementation, the chatbot achieved:
- 27% increase in order completion rate
- 7% increase in average order value (AOV)
- 7× faster response time compared to human agents
This demonstrates that domain-specific AI can not only provide faster responses but also actively support user decision-making and improve business outcomes in healthcare environments.

Specialized assistants designed for internal and industry use cases
5.2 Structured and task-specific outputs
This use case focuses on improving how models handle standardized tasks that require consistent formatting or clear outputs. It is commonly used in data processing and automation workflows.
- Document extraction from forms, invoices, or contracts
- Data classification tasks such as labeling or categorization
- Output formatting based on predefined templates
- Question-answering systems with fixed response structures
When businesses need to fine-tune models for structured outputs, domain-specific question answering, or workflow-based assistants, Model Fine-Tuning is a practical example of implementing supervised fine-tuning in real-world pipelines, covering stages from training to monitoring.
Example: Carvana used fine-tuned AI models to extract key information from complex vehicle title and legal documents, which are often inconsistent and difficult to process manually. With domain-specific training, the system learns to identify relevant fields such as ownership details, VIN numbers, and transaction data, then convert them into structured formats for internal workflows.
Results:
- Saves approximately 7–10 hours per week per legal team member
- Automates extraction and structuring of high-volume document workflows
- Reduces manual review effort in legal and compliance processes
This case shows how supervised fine-tuning helps transform unstructured legal documents into structured, actionable data, significantly improving operational efficiency.
5.3 Brand and experience optimization
This category focuses on aligning AI responses with brand identity and improving user experience consistency across interactions. It ensures the model behaves in a predictable and controlled way.
- Aligning responses with brand tone and communication style
- Ensuring consistent customer support experiences
- Improving instruction-following behavior in AI assistants
Example: Oscar Health fine-tuned its AI models to assist with “Clinical Documentation Improvement.” The goal was to take doctor-patient transcripts and turn them into clinical summaries that match the company’s internal medical standards and tone.
Results: This specialized fine-tuning helped handle administrative tasks for over 1 million members, significantly reducing the “administrative burden” on medical staff and improving the accuracy of member record-keeping.
6. Benefits of supervised fine-tuning
Supervised fine-tuning helps adapt large language models more effectively to specific tasks by training them on curated labeled datasets. Instead of learning from scratch, the model builds on existing knowledge and becomes more suitable for real-world, task-oriented applications.
- Enhanced task performance by learning patterns directly from labeled examples tailored to the use case
- Greater output accuracy and reliability with improved alignment to expected results
- Faster development cycles compared to full model training, since it builds on pre-trained foundations
- Efficient knowledge transfer from general-purpose understanding to specialized domains
- Better adaptability to business requirements using relatively smaller, high-quality datasets
- More stable and consistent outputs, improving usability in production environments

Supervised fine-tuning increases reliability and consistency
7. Challenges of supervised fine-tuning
While supervised fine-tuning is effective for adapting models to specific tasks, it also introduces several challenges that need to be carefully managed throughout the development process. These challenges are mainly related to data quality, model reliability, and evaluation requirements.
- Requires high-quality labeled data, which is often costly and time-consuming to collect
- Poor or biased datasets can negatively impact model behavior and reduce reliability
- Risk of overfitting when the model becomes too specialized on limited training data
- Can amplify existing biases present in the dataset, leading to unfair or inconsistent outputs
- Requires continuous evaluation to ensure improvements are real and generalizable to new inputs
8. Frequently Asked Questions
8.1. Where does supervised fine-tuning fit in the AI pipeline?
Supervised fine-tuning sits in the AI pipeline after pre-training and before deployment, acting as the step that adapts a general model into a task-specific one. It is also the first stage of post-training alignment, helping the model better follow instructions and produce more accurate, reliable outputs.
8.2. When should you NOT use supervised fine-tuning?
Supervised fine-tuning should not be used when high-quality labeled data is unavailable or when the dataset is noisy, inconsistent, or insufficient, as this can lead to poor model performance and unreliable outputs. It is also unsuitable when there are limited resources for training and evaluation, since the process requires careful validation to ensure stable results.
8.3. Do you need GPUs for supervised fine-tuning?
Yes, GPUs are typically needed for supervised fine-tuning, especially when working with large models, as they significantly speed up training and improve computational efficiency. In practice, this process is often supported by scalable AI infrastructure that provides the necessary compute power for training and experimentation, including solutions such as FPT AI Infrastructure.
In summary, supervised fine-tuning helps adapt pre-trained AI models to specific business tasks using labeled data, improving accuracy, consistency, and alignment with user requirements. Key takeaways include:
- Supervised fine-tuning (SFT) trains models on labeled input-output examples to improve task-specific performance.
- SFT helps bridge the gap between general-purpose models and real-world business applications.
- It is commonly used for domain-specific assistants, structured outputs, and brand-aligned AI experiences.
- SFT differs from prompt engineering and RAG, but these approaches are often combined in production AI systems.
- High-quality labeled data is critical for successful fine-tuning outcomes.
- Continuous evaluation is necessary to avoid overfitting and maintain model reliability.
At FPT AI Factory, you can get started quickly with $100 in credits upon signup, allowing you to immediately explore GPU resources and AI development tools. For enterprises or organizations with large-scale or customized AI requirements, you can also reach out via the official contact form for tailored consultation and deployment support.
Contact information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore Related Articles:
What is LoRA? A Complete Beginner’s Guide on How It Works
Prompt Engineering vs Fine-Tuning: A Guide to Better LLM


