
より知的でコンテキスト認識型のAIへの需要が高まる中、ビジョン・ランゲージモデル(VLM)は、画像とテキストの両方を理解できる強力なモデル群として登場しています。これらのモデルは、AIアシスタント、医療文書解析、自動保険請求処理などのアプリケーションを支えています。
本記事では、NVIDIA H100 GPUを活用したスケーラブルかつ高性能なAIインフラであるMetal Cloudを用いて、大規模VLMを学習させるための実践的なベストプラクティスを紹介します。AIエンジニア、データサイエンティスト、またはマルチモーダルAIシステムを効率的に拡張したいIT意思決定者の方に向けて、アーキテクチャ選定、学習パイプライン、最適化戦略について、実体験に基づくガイドを提供します。
1.実際のユースケースと導入成果
VLMは複数の産業を変革しています:
- 文書理解とインテリジェント文書処理(IDP):非構造化フォーマットや画像からの洞察抽出
- 医療・保険分析:請求処理の自動化(データ入力や調整プロセス含む)、不正請求の検出、医療文書の要約
- 医療文書の例:

- AI搭載アシスタント:マルチモーダル推論やコンテキスト認識を持つAIチャットボットの実現
- PDFデータ抽出のビジネスインパクト:
- 手作業によるデータ入力時間を15分から2分未満へ短縮
- 新しいデータセットへの迅速な対応で、学習期間を数ヶ月から数週間に短縮
- 人的リソースの増加なしに処理能力を拡大
- AIによる分析で不正検出能力を強化
- FPT AI Factoryは、NVIDIA VSS Blueprint Architectureを基に、自動車保険請求ビデオ処理に以下のアーキテクチャを実装しています:
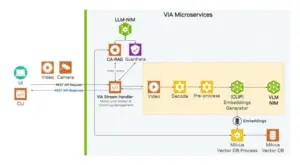
図.NVIDIA VSS Blueprint Architectureより出典
- 車両情報と損傷評価への自動アクセスによるビジネスインパクト:
- 損傷自動評価:VLMで請求内容やビデオを分析し損傷を自動評価。 VLMモデルは案件を重度損傷・軽度損傷・損傷なしに分類し、適切なプロセスや専門家に振り分け。 これにより軽度損傷の最大80%を自動化し、請求処理時間を20分から2分に短縮。
- 請求処理効率の向上:AI評価による人的介入の最小化と迅速な請求決済
- 不正検出・予防:請求報告の異常や不整合を特定し、不正請求を抑止
- 運用コスト最適化:手作業による検査・評価コストの削減
VLMによる車両損傷評価の例
 H100とA100のROI比較
H100とA100のROI比較
- 初期コストは高いが、効率の良さで総コストは削減
- 学習サイクル短縮でモデル展開が高速化
- A100に比べ全体学習コストを約43%削減
2. VLMアーキテクチャ・データ処理パイプライン・ハードウェア要件
2.1 VLMアーキテクチャ
標準的なVLMは以下3つの主要コンポーネントで構成されます:
- ビジョンエンコーダー: CNNやViT、CLIP Vision Encoder、Swin Transformerなどで画像特徴量を抽出
- ランゲージデコーダー:GPT、LLaMA、QwenなどのLLMで視覚プロンプトに基づくテキストを生成
- マルチモーダル融合モジュール:画像・テキスト埋め込みを統合し一貫性ある出力を生成
2.2 データ処理パイプライン
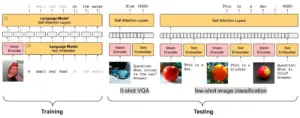
VLM学習時の画像・テキストデータ処理パイプラインは以下の通り:
【学習フェーズ】
- 画像データはビジョンエンコーダーで処理し、視覚特徴量を抽出
- テキストデータはテキストエンベッダーでベクトル表現に変換
- 両方の埋め込みを融合し、自己注意レイヤー付きランゲージモデルに入力、マルチモーダル学習を実現
【テストフェーズ】
- ゼロショットVQA:未見画像についての質問応答
- フューショット画像分類:少数ラベル例で新規画像を分類
 2.3 NVIDIAソフトウェアスタックの活用
2.3 NVIDIAソフトウェアスタックの活用
学習:
NVIDIA NeMoを使用してファインチューニングを実施。NeMoはVLMや音声・NLPモデルの大規模学習・ファインチューニングが可能なオープンソースフレームワークです。
NVIDIA NeMoの主な機能:
- 事前学習済み基盤モデル:特定用途向けに最適化されたモデルを提供
- モデル並列化: テンソル、パイプライン、シーケンス並列化で大規模モデル学習に対応
- LoRA/QLoRA対応: 効率的なパラメータチューニングで計算・メモリコスト削減
- NVIDIA HGX Cloud連携:H100クラスタ上でシームレスなクラウド学習を実現
NVIDIA NeMo on H100 GPUによるパフォーマンス向上
✅ FP8精度と最適化カーネルで2~3倍高速学習
✅ 混合精度とメモリ効率化オプティマイザーでメモリ使用量50%削減
✅ テンソル&パイプライン並列化でマルチGPUスケーリングもシームレス
NVIDIA NeMoとH100の組み合わせで、VLMの大規模・効率的なファインチューニングが可能となり、計算コストと展開時間を大幅に削減できます。
推論:
VLMの低レイテンシ・高スループット要件を満たすため、TensorRT-LLMを最適化に活用。これにより全体レイテンシとTTFT(初回推論時間)が大幅低減。INT8、SmoothQuant、FPT8、INT4、GPTQ、AWQなど多様な量子化もサポート。
2.4 ハードウェア面での考慮事項
- バッチサイズ・シーケンス長:GPU使用率最大化とメモリボトルネック回避の最適化
- メモリ管理:H100の大容量メモリ帯域を活用し効率的なデータ処理
- 並列化戦略:テンソル並列、パイプライン並列、分散学習技術で大規模モデルの最適化
3. .VLM学習におけるNVIDIA H100とA100のベンチマーク比較
NVIDIA H100はA100より1時間あたりの運用コストは高いものの、学習時間短縮で全体コストは大幅削減。事例では、H100での学習はA100に比べてコストが約43%削減され、学習速度も3.5倍向上。
パフォーマンス比較では、H100の高効率性が際立っています。
| 指標 | 2 x H100 (HBM3-80GB) | 2 x A100 (PCIe-80GB) | 数値が高い方が良いか? |
| エポックタイム (Qwen2.5VL-7B,batch_size=2, num_sample=200k) | |||
| 推論スループット (Qwen2.5VL-3B, token/sec, PyTorch) | ~410 | ~150 | Yes |
| 消費電力 (カードごとのGPU利用率100%) | 480W | 250W | No |
| 時間当たりコスト | 1.5 x A100 | Lower | No |
| トータル学習コスト | 0.57 x A100 | Higher | No |
4. 学びと最適化戦略
リソース最適化
- GPU使用率最大化:バッチサイズ、シーケンス長、キャッシュ機構の適切な調整
- 並列処理戦略:FSDP、ZeRO、NCCLなどを活用し学習速度向上
分散学習の課題
- データ同期:GPU間通信の効率化でボトルネック回避
- インフラ準備:H100クラスタ用の電源・冷却対応
システム統合・安定性
- ソフトウェアスタックの互換性:PyTorch/XLA、Triton、TensorRTとのシームレスな運用
- 継続的な性能監視:定期的なファインチューニングによる最適効率維持
5. VLM学習最適化の将来トレンド
モデルの複雑化・計算需要の増加に対応するため、以下のトレンドが見られます:
- スケーラビリティと効率:FP8精度、量子化技術、FlashAttentionによるメモリ最適化・高速処理
- 先進的な学習パイプライン:ZeRO(DeepSpeed)、FSDPなどでメモリオーバーヘッド削減・拡張性向上
- 高性能マルチGPU学習:H100のNVLink 4.0やPCIe 5.0によりGPU間通信速度向上
- 効率的ファインチューニング手法:LoRAやQLoRAでコスト削減と高速パラメータ調整
- ドメイン特化最適化:今後のVLMは医療画像、法務文書、技術分析など特化領域向けにファインチューニングされ、専用データセットや最適化学習戦略が必要に
6. 論と推奨
H100を選択すべき場合
- 7Bパラメータ以上の大規模VLM学習で大きなバッチ・長シーケンスが必要な場合
- NVLink 4.0による高速接続のマルチGPUクラスタ運用時
- リアルタイム推論・低遅延が求められるユースケース
A100で十分な場合
- 4Bパラメータ未満の小~中規模生成GenAIモデル
- 学習時間へのこだわりが少ないコスト重視プロジェクト
- 単一タスクで計算負荷が低いモデル
まとめ総括
高度なVLMへの需要拡大に伴い、ハードウェア・アルゴリズム・学習戦略の最適化は不可欠です。NVIDIA H100 GPUは大規模・高性能なVLM学習に最適であり、マルチモーダルAIの進化と実応用を加速させます。
FPT AI Factoryのサービスはこちらをご覧ください。
ホットライン:0800-300-9739
メール:support@fptcloud.jp


