
What is Data Annotation? Data annotation is the process of adding labels, tags or metadata to raw data so AI models can understand and learn from it. In machine learning, annotated data helps models recognize patterns in text, images, audio, video, and time-series signals. In this article, FPT AI Factory helps teams scale data annotation within a connected AI developer cloud, bringing data preparation, model development, and deployment into one streamlined AI workflow.
1. What is Data Annotation?
Data annotation means identifying important information inside raw data and attaching labels that explain what the data represents. These labels act as training signals for AI models. For example, an image of a street can be annotated with bounding boxes around cars, pedestrians, and traffic signs, while a customer review can be labeled as positive, negative, or neutral.
Data annotation is closely connected to training data because labeled examples help models learn the relationship between input data and the expected output. If the labels are clear, consistent, and relevant, the model has a stronger foundation for learning. If labels are incorrect or inconsistent, the model may learn the wrong patterns and perform poorly in production
2. Why is data annotation important for AI and machine learning?
Data annotation is important because most AI systems need examples before they can make useful predictions. In supervised learning, the model learns from input-output pairs, such as an image and its object label, or a sentence and its sentiment category. The more accurate and representative the annotations are, the easier it is for the model to understand the task.
Annotation quality also affects model evaluation. If the ground-truth labels are wrong, teams may misunderstand whether a model is actually accurate. This is why annotation should be connected with clear review workflows, dataset versioning, and evaluation metrics in machine learning. High-quality annotation helps teams compare models more objectively and decide whether the model is ready for deployment.
For businesses, good data annotation reduces the gap between AI prototypes and practical use cases. A chatbot needs correctly tagged intents, a medical imaging model needs expert-reviewed labels, and an autonomous vehicle system needs precise object and lane annotations. In each case, the model cannot learn the right behavior unless the dataset is prepared carefully.
3. How Data Annotation works?
Data annotation usually works as a structured process rather than a one-time task. Teams first define the AI use case, collect raw data, prepare annotation guidelines, label the data, review quality, store the approved dataset, and then use it for model training or validation. This workflow can be supported by a data pipeline that moves data from collection to preprocessing, annotation, training and deployment.
Step 1: Define the task and label schema
Teams decide what the model needs to learn. For image detection, this may include object classes such as vehicle, person, road sign or defect. For text analysis, it may include sentiment, intent, named entities or topic categories.
Step 2: Collect and prepare raw data
Raw data may come from documents, cameras, sensors, audio recordings, transaction systems or user interactions. Before annotation, the data should be cleaned, deduplicated, and organized so annotators can work efficiently.
Step 3: Create annotation guidelines
Guidelines explain exactly how labels should be applied. They help reduce disagreement between annotators and make the dataset more consistent. Good guidelines include positive and negative examples, edge cases, and quality rules.
Step 4: Annotate the data
Human annotators, subject experts or AI-assisted tools apply labels. The annotation method depends on the data type, such as bounding boxes for images, transcripts for audio, entity tags for text or event markers for time-series data.
Step 5: Review and validate quality
A second reviewer or quality-control process checks label accuracy and consistency. Teams may measure inter-annotator agreement, sample error rates and compare labels against gold-standard examples.
Step 6: Store, version and reuse datasets
Approved datasets should be centralized and versioned so teams can track which data was used for training, validation and testing. This makes experiments easier to reproduce and improves collaboration across AI teams.
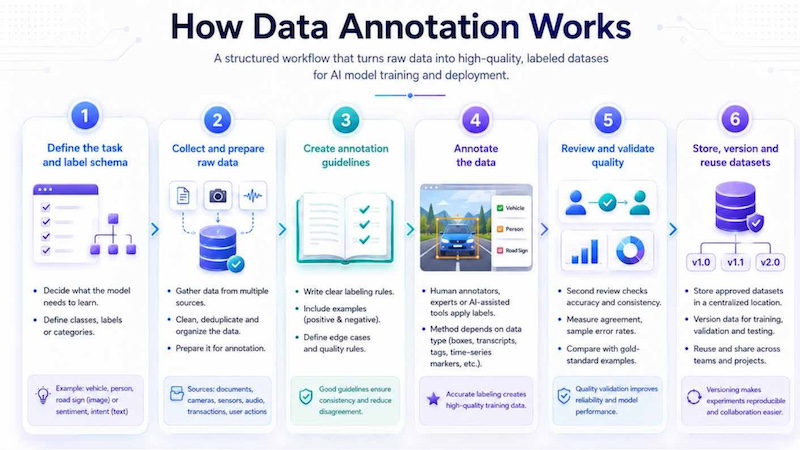
A data annotation workflow moves raw data through labeling, quality review, dataset versioning and model training
4. Types of Data Annotation
Data annotation can take different forms depending on the type of data and the AI task. Text, audio, image, video, and time-series data all require different labeling methods, quality checks, and domain knowledge
4.1. Text annotation
Text annotation adds labels to words, sentences or documents so natural language processing models can understand meaning. Common tasks include sentiment labeling, named entity recognition, intent classification, topic tagging and relation extraction. For example, a customer support message such as “I want to change my delivery address” may be labeled with the intent “delivery_update” and the entity “address.”
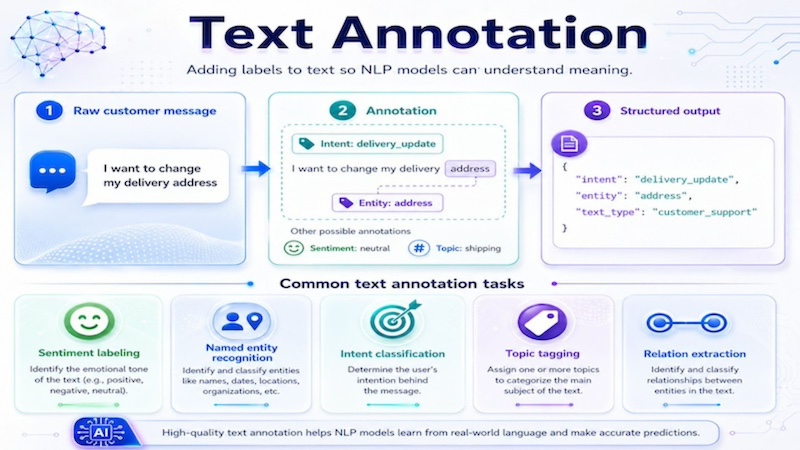
Text annotation helps NLP models understand customer messages by labeling intent, entities, sentiment, topics and relationships in structured data.
4.2. Audio annotation
Audio annotation adds labels to sound recordings. It may include transcription, speaker identification, emotion labeling, background-noise tagging, timestamps or phoneme-level labels. For example, a call-center recording can be annotated with speaker turns, customer intent, and moments of dissatisfaction to train speech analytics or voice assistant systems

Audio annotation labels call recordings by speaker, intent, sentiment helping AI systems understand conversations for speech analytics and voice assistants.
4.3. Image annotation
Image annotation labels visual content so computer vision models can detect, classify or segment objects. Common methods include image classification, bounding boxes, polygons, semantic segmentation, instance segmentation and keypoint annotation. For example, a retail shelf image can be annotated with bounding boxes around each product to help a model detect out-of-stock items
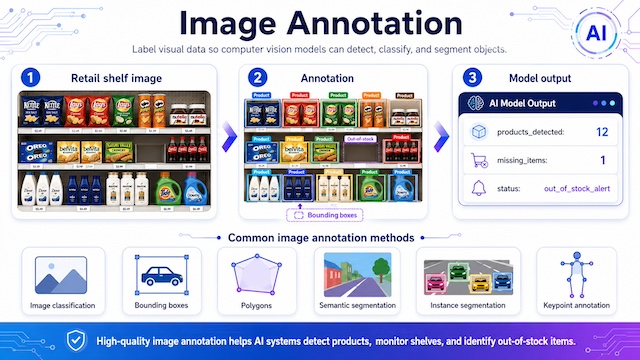
Computer vision models detect products, monitor retail shelves and identify out-of-stock items through labeled visual data
4.4. Video annotation
Video annotation labels objects, actions or events across multiple frames. It is useful when models need to understand movement, behavior or changes over time. For example, a traffic video may be annotated with vehicles, lane changes

Video annotation labels objects, actions and events frame by frame, helping AI models understand movement, behavior and changes over time.
4.5. Time series annotation
Time series annotation labels events, anomalies or states in data that changes over time. It is common in sensor data, finance, IoT, energy monitoring and industrial operations. For example, a machine vibration dataset may be annotated with “normal,” “warning” and “failure” periods to train a predictive maintenance model.
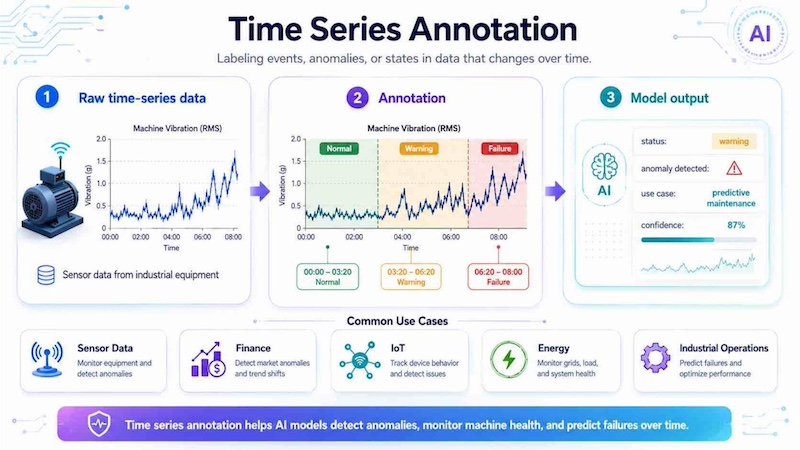
Time series annotation labels changing data over time, helping AI models detect anomalies, monitor machine health and predict failures.
5. Challenges of Data Annotation
Although data annotation is essential, it can be expensive, complex, and difficult to scale. The main challenges usually come from quality control, data volume, task complexity, domain expertise, and ethical considerations.
5.1. Data quality and consistency
Inconsistent labels are one of the biggest risks in data annotation. If two annotators label the same example differently, the model receives conflicting signals. This can happen when the guidelines are unclear, the task is subjective or the dataset contains many edge cases. Teams should use clear instructions, reviewer checks, and sample audits to improve consistency.
5.2. Data quantity and scalability
Modern AI systems often require large volumes of labeled data. As datasets grow, manual annotation becomes slower and more expensive. Teams may need a mix of human annotators, AI-assisted pre-labeling, active learning, and scalable storage to manage annotation at production scale.
5.3. Annotation complexity
Some annotation tasks are simple, such as classifying a product image. Others are complex, such as drawing pixel-level segmentation masks for medical images or tracking objects across video frames. More complex tasks take longer, require better tools, and need stricter review processes.
5.4. Subject matter expertise
Certain datasets require expert annotators. A general annotator may label simple objects, but a radiology dataset, legal contract dataset or satellite imagery dataset may require domain experts. Without the right expertise, labels may be technically incorrect even if they look consistent.
5.5. Ensuring ethical and unbiased data
Data annotation can also introduce bias. If the dataset underrepresents certain groups, locations, accents or scenarios, the model may perform unevenly in real-world use. Annotation guidelines should include fairness checks, privacy rules and escalation paths for sensitive data. This connects directly with AI governance, which helps organizations build AI systems responsibly through clear rules, processes and accountability.
6. Data Annotation Use Cases by Industry
Data annotation supports many industry-specific AI applications. The right annotation strategy depends on the data type, business goal, and level of risk in the final AI system
6.1. Automotive & Autonomous Driving
Autonomous driving systems rely on annotated camera, LiDAR, and sensor data to detect roads, vehicles, pedestrians, signs, and obstacles. Labels may include bounding boxes, lane markings, segmentation masks, and object tracking across frames. These annotated datasets help models understand real-world driving conditions and react more safely. This use case is closely related to Physical AI, where AI systems perceive and act in the physical world through sensors, robots, and autonomous systems.
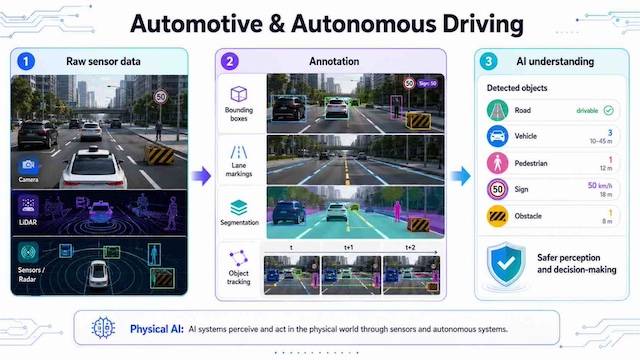
Autonomous driving annotation labels camera, LiDAR, and sensor data to help AI detect roads, vehicles, pedestrians, signs, and obstacles for safer real-world decision-making.
6.2. Healthcare & Medicine
Healthcare annotation can include labeling tumors in scans, identifying organs in radiology images, tagging clinical entities in medical notes or classifying pathology slides. Because errors can affect patient care, medical annotation often requires expert review and strict privacy protection. High-quality labels help AI systems support diagnosis, triage, and research more reliably.
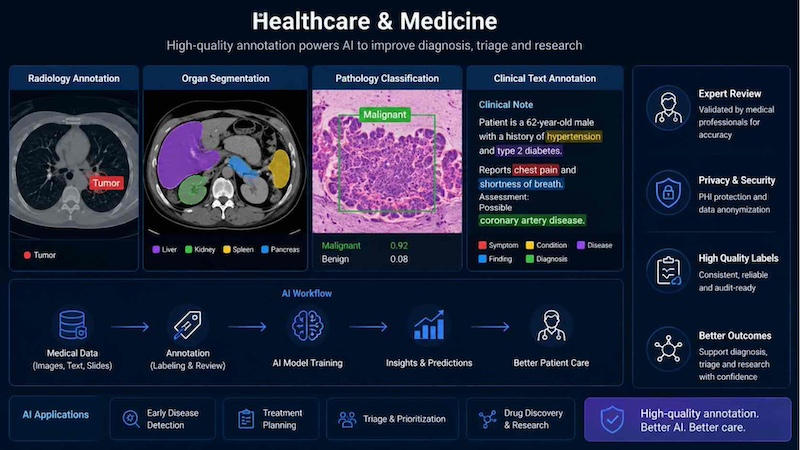
Healthcare annotation labels medical images, pathology slides and clinical notes to help AI support diagnosis, triage and research with expert review and privacy protection.
6.3. Retail & Stores
Retail teams use data annotation for product recognition, shelf monitoring, customer behavior analysis, and recommendation systems. For example, images from store shelves can be annotated to detect missing products, incorrect placement or damaged packaging. Customer text data can also be annotated by topic or sentiment to improve support and personalization.

Retail data annotation helps AI identify products, detect shelf issues and understand customer feedback to improve store decisions and shopping experiences.
6.4. Satellite & Drone Imagery
Satellite and drone imagery annotation helps models identify buildings, roads, crops, vehicles, damage, land use and environmental changes. This supports agriculture, disaster response, urban planning, logistics and infrastructure monitoring. The task often uses segmentation masks or polygons because objects may be small, irregular or viewed from above.
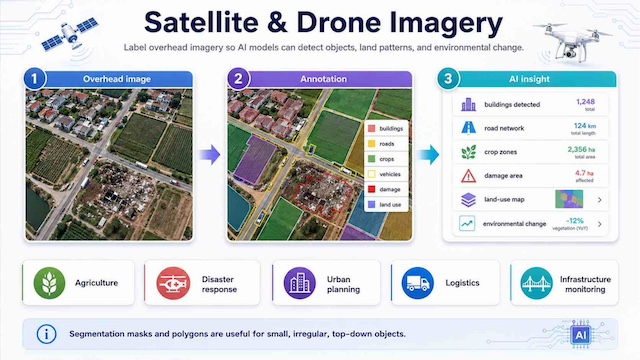
Satellite and drone imagery annotation turns overhead images into labeled data, helping AI monitor land use, infrastructure, crops, damage and environmental changes.
6.5. Security & Surveillance
Security and surveillance systems use annotated video and image data to detect objects, restricted-area entry, unusual behavior or safety incidents. For example, a model can be trained to identify whether a person is wearing required safety equipment in a factory. However, teams must also consider privacy, consent and responsible monitoring practices.
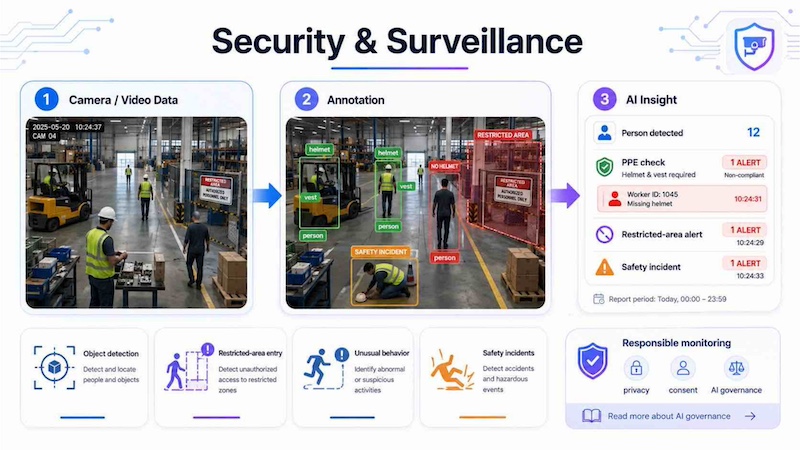
Security and surveillance annotation trains AI to detect safety risks, restricted areas and unusual activities while promoting responsible, privacy-conscious monitoring.
6.6. Education & AI Research
Education and AI research use annotated datasets for model benchmarking, learning analytics, automated feedback and experimental model development. Researchers may annotate student responses, research papers, code examples or multimodal learning data. In this context, FPT AI Studio’s Data Hub lets teams and businesses centralize and version annotated datasets instead of storing data across scattered folders, making datasets easier to access, manage and reuse.
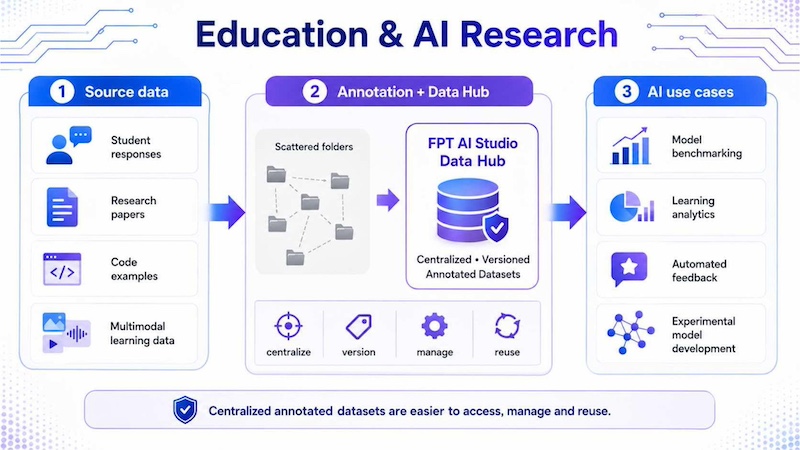
Education and AI research annotation organizes labeled datasets for benchmarking, learning analytics, automated feedback, and model development.
6.7. Generative AI & LLMs
Generative AI and large language models (LLMs) depend on annotated data to improve instruction following, response quality, safety, and domain relevance. Annotation tasks may include labeling prompt-response pairs, ranking preferred answers, identifying harmful or inaccurate outputs, tagging document topics, and preparing question-answer datasets for retrieval-based applications. These labels help models generate responses that are more useful, consistent, and aligned with user needs.
For example, when training a customer support chatbot, human annotators may compare multiple AI-generated responses to the same customer question and rank the most helpful, accurate, and polite answer. These preference labels are then used to fine-tune the model, helping it produce higher-quality responses in future interactions.
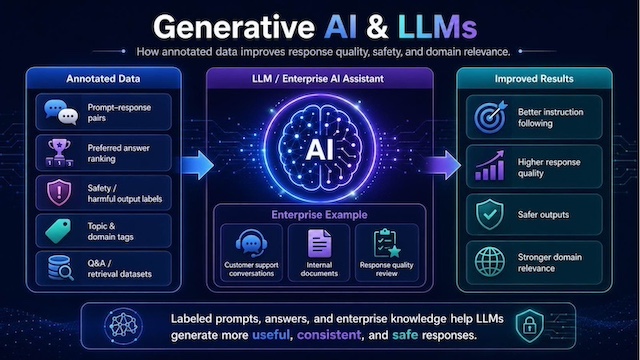
Generative AI and LLM annotation helps improve response quality, safety and domain relevance through labeled prompts, answers and enterprise knowledge data.
7. Current Trends in Data Annotation Development
Data annotation is evolving as AI systems become more multimodal, more domain-specific, and more connected to production workflows. Businesses are moving from simple manual labeling toward hybrid systems that combine automation, human review, dataset management, and AI model deployment. The goal is no longer just to label data, but to create reliable datasets that can support training, evaluation, and deployment at scale.
AI-assisted annotation: Pre-labeling tools can suggest labels before a human reviewer confirms or corrects them. This reduces manual work while keeping quality control in the loop.
Active learning: Instead of labeling data randomly, active learning helps teams prioritize uncertain or high-value samples for human review. This reduces annotation effort while improving dataset quality and model performance, especially in fields such as medical imaging or defect detection.
Human-in-the-loop quality control: Human reviewers remain important for complex, sensitive or ambiguous data. This is especially true in healthcare, security, and legal use cases.
Multimodal annotation: More projects now involve text, images, audio, and video together. For example, an AI assistant may need annotated chat messages, screenshots and voice inputs to understand a user task.
Synthetic data and simulation: When real data is limited, expensive or sensitive, teams may use synthetic data to expand coverage. This is common in autonomous systems, robotics, and rare-event scenarios.
Dataset versioning and data catalogs: As datasets grow, teams need to track label versions, data sources, access rights, and experiment history. This makes data catalogs and centralized dataset hubs more important.
Governance and privacy by design: Annotation workflows increasingly need privacy controls, bias checks, audit trails, and clear policies for sensitive data.
For teams that want to connect annotation, experimentation, and production more effectively, AI development platforms provide a structured environment that brings together compute infrastructure, data management, model training, deployment pipelines, and monitoring. Once models are trained and validated, services such as Serverless Inference can help integrate AI capabilities into applications through APIs.
8. Frequently Asked Questions
8.1. How a data catalog supports data annotation?
A data catalog supports data annotation by helping teams organize datasets, track metadata, manage ownership, and understand where data comes from. For annotation workflows, it helps teams find the right dataset, document label definitions, control access, and reuse approved data for future experiments.
8.2. Is data annotation the same as data labeling?
The two terms are often used together, but they are not always identical. Data labeling usually refers to assigning labels such as categories, classes or tags. Data annotation can be broader because it may include richer metadata, bounding boxes, segmentation masks, timestamps, relationships or explanatory notes. In practice, many teams use the terms interchangeably.
8.3. How does annotation quality affect model performance?
Annotation quality directly affects model performance because labeled data acts as the model’s learning signal. If labels are accurate and consistent, the model can learn useful patterns. If labels are noisy, biased or inconsistent, the model may make incorrect predictions or fail when deployed in real-world scenarios.
8.4. What types of data can be annotated?
Many types of data can be annotated, including text, images, audio, video, sensor data, tabular data, and time-series data. The annotation method depends on the AI task. For example, images may use bounding boxes, text may use named entities, and audio may use transcripts or speaker labels.
Data annotation is a core step in building reliable AI systems because it turns raw data into meaningful training signals. From text and image annotation to video, audio, and time-series labeling, the quality of annotation directly affects how well a model learns and performs in real-world use. As AI teams scale, they need structured workflows for annotation quality, dataset versioning, privacy control, and model evaluation.
Contact information
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more articles


