
As organizations continue to generate and manage growing volumes of enterprise data, many businesses are re-evaluating whether traditional data management approaches can still provide the visibility, accessibility, and governance required for modern analytics and AI workflows. In this article, FPT AI Factory breaks down what is a data catalog, how it works, and why it has become a critical solution for modern data management and enterprise analytics environments
1. What is a Data Catalog?
A data catalog can be understood as the combination of a Metadata Layer and a Discovery Layer for an organization’s data ecosystem. The metadata layer collects, enriches, and manages information about data assets, while the discovery layer enables users to easily search, understand, and access those assets. Rather than storing the actual data, a data catalog organizes metadata from datasets, databases, dashboards, data warehouses, and APIs, making data assets easier to find, understand, govern, and use.
By combining metadata management with powerful search and discovery capabilities, a data catalog helps users quickly locate trusted data, understand its context, and use it more effectively for analytics, reporting, and decision-making. Modern data catalogs also support data lineage, governance, and AI-powered recommendations to improve data accessibility and collaboration across teams.
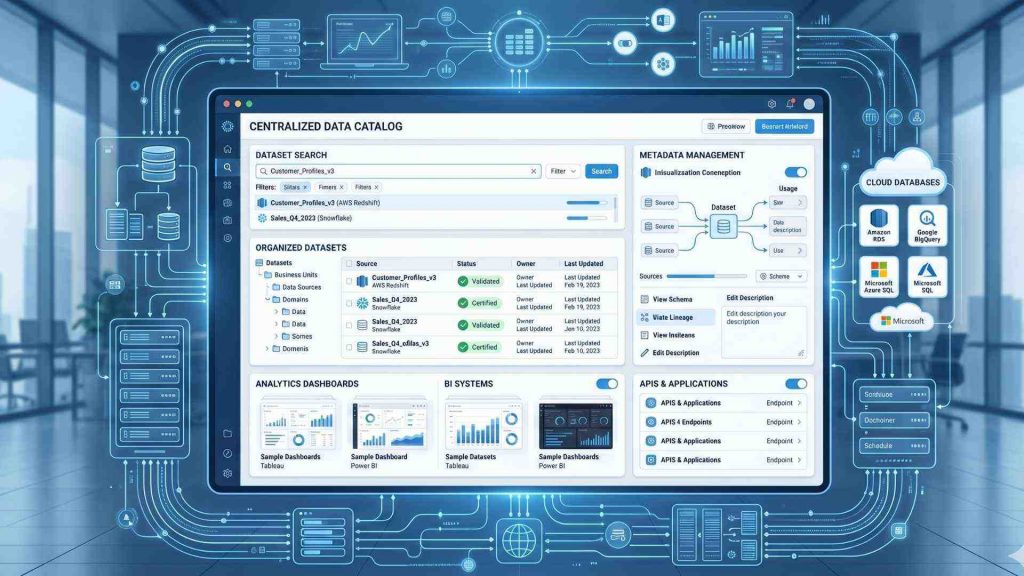
Data catalogs help organizations organize, search, and manage enterprise data assets more efficiently
2. Types of Data Catalog
Organizations use different types of data catalogs depending on their infrastructure, governance requirements, and analytics workflows. Each type is designed to support specific data management, discovery, and operational needs across modern business environments.
2.1. Based on Scope and Architecture
The scope and architecture of a data catalog determine how broadly it manages metadata and supports data discovery across an organization. Based on these characteristics, data catalogs are commonly divided into the following types:
- Enterprise Data Catalogs: Designed to provide a centralized view of data assets across the entire organization. These catalogs aggregate metadata from multiple systems, departments, and platforms, enabling enterprise-wide data discovery, governance, and collaboration.
- Cloud-Native Data Catalogs: Built specifically for cloud environments and modern data platforms. They integrate with cloud data warehouses, data lakes, and analytics services to support scalable metadata management and data discovery.
- Departmental Catalogs: Focused on the needs of a specific business unit or team, such as marketing, finance, or operations. They help departments organize and manage their own data assets while supporting local governance and analytics requirements.
- Tool-Specific Embedded Catalogs: Integrated directly into a particular platform, application, or analytics tool. These catalogs provide metadata and discovery capabilities within a specific ecosystem rather than across the entire organization.
2.2. Based on Functionality and Focus
Data catalogs can also be differentiated by the specific functions they perform and the users they are designed to support. Depending on whether the priority is business collaboration or governance management, data catalogs generally fall into the following categories:
- Business and Collaborative Catalogs: Designed to improve data accessibility and collaboration among business users. They typically include business glossaries, data definitions, ownership information, documentation, and search capabilities that make data easier to understand and use.
- Operational and Governance Catalogs: Focused on data governance, compliance, quality, and operational oversight. These catalogs often provide capabilities such as data lineage, metadata management, policy enforcement, access controls, and audit tracking.
2.3. Based on License and Accessibility
Another common way to classify data catalogs is by their licensing model and deployment method. Based on their technical resources and operational requirements, organizations can choose:
- Open-Source Catalogs: Freely available solutions that organizations can deploy, customize, and manage themselves. Open-source catalogs offer flexibility and community-driven development but may require more internal resources for maintenance and support.
- Data Catalog as a Service (DCaaS): Cloud-based managed services that provide data catalog functionality without requiring organizations to maintain their own infrastructure. DCaaS solutions typically offer faster deployment, automatic updates, and simplified administration.
3. How Does a Data Catalog Work?
A data catalog works by collecting metadata from databases, cloud platforms, applications, APIs, and other data sources across an organization. It automatically organizes this information into a searchable system that helps users discover, understand, and access relevant data more efficiently.
Modern data catalogs often use automation, metadata indexing, lineage tracking, and AI-powered search capabilities to improve data discovery and governance across enterprise data pipelines. Teams can search datasets, review data ownership, track data movement, and understand how information is being used across business workflows and analytics environments.
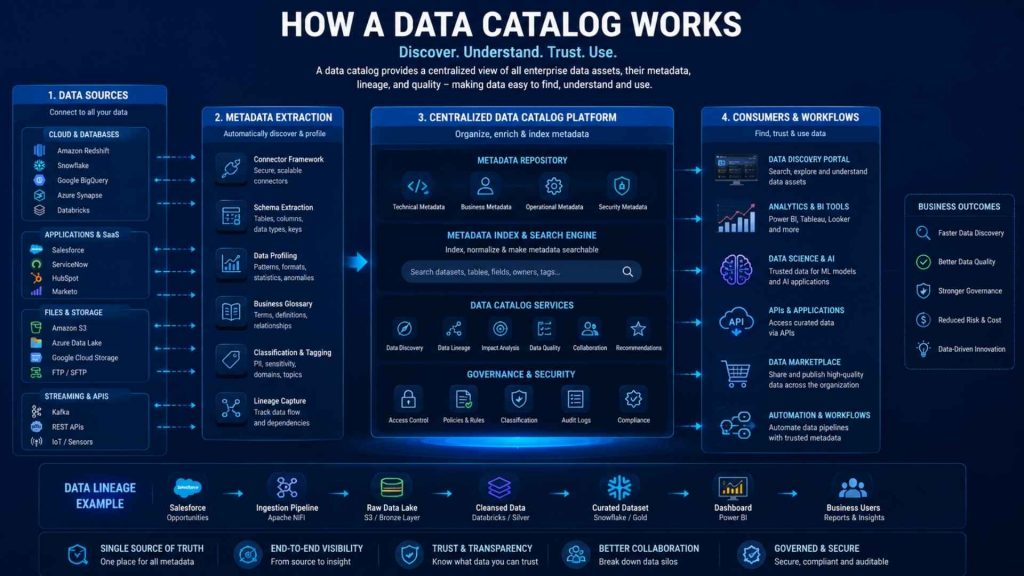
Data catalogs centralize metadata and improve data discovery across enterprise systems
4. Core features & Functions of Data Catalog
Modern data catalogs provide features that help organizations improve data discovery, governance, accessibility, and collaboration across different teams and business environments. Here are some important capabilities that make data catalogs essential for modern enterprise data management.
4.1. Discover and search data
Data catalogs enable users to efficiently search and locate datasets, databases, dashboards, APIs, and other data assets across the entire organization. By centralizing all data sources into a unified search interface, they significantly improve data accessibility and reduce the time required to find relevant information for analysis and decision-making processes.
4.2. Metadata management
Metadata management organizes and standardizes information about datasets, including descriptions, formats, ownership, classifications, and usage context. It ensures that data assets are well-documented and easily understood across teams. This improves data transparency, consistency, and trust, while reducing ambiguity when multiple systems use shared or overlapping datasets.
4.3. Data lineage tracking
Data lineage tracking visualizes how data flows through systems, applications, and analytical pipelines. It provides a clear view of data origins, transformations, and dependencies across the entire lifecycle. This helps teams quickly identify issues, assess the impact of changes, and ensure data reliability for reporting, analytics, and machine learning use cases.
4.4. Data governance and access control
Data catalogs enforce governance policies and manage user permissions through structured access control mechanisms. They ensure that sensitive data is protected while still being accessible to authorized users. This supports compliance with regulations and helps organizations maintain security, consistency, and accountability across different teams and environments.
4.5. Self-service analytics
Self-service analytics empowers users to independently explore, access, and analyze data without heavy reliance on IT or engineering teams. By providing curated datasets and intuitive tools, it accelerates reporting processes and enables faster insights. This approach supports more agile decision-making and strengthens a data-driven culture within the organization.
4.6. Collaboration supports
Data catalogs enhance collaboration by allowing teams to share insights, document datasets, and add business context directly within the platform. Users can communicate effectively across departments, improving knowledge sharing and data understanding. This helps align technical and business teams, ensuring more consistent and informed data usage across the organization.
5. Benefits of a Data Catalog
Data catalogs help organizations improve data accessibility, governance, collaboration, and analytics efficiency across modern business environments. Here are certain benefits of using data catalogs:
5.1. Faster data discovery
Data catalogs allow users to quickly search and locate relevant datasets across multiple systems and platforms. This reduces manual search time significantly and improves efficiency in accessing data. Faster discovery helps teams work more productively and supports better decision-making processes based on timely and accurate information.

Data catalogs help users discover and access datasets more efficiently.
5.2. Improved data governance
Organizations can manage metadata, permissions, policies, and access controls through centralized catalog systems. This improves consistency in governance and strengthens data security across departments. It also helps ensure compliance with regulations and supports standardized data usage practices across the entire organization.
5.3. Better collaboration across teams
Data catalogs enable technical and business teams to share knowledge and data context more effectively. Users can document datasets, add descriptions, and communicate insights within a shared platform. This improves understanding of data assets and supports more consistent collaboration in analytics and reporting workflows.

Data catalogs improve collaboration between technical and business teams.
5.4. Reduced duplicate datasets
Improved visibility into data assets helps organizations identify duplicate or redundant datasets across systems. This reduces data inconsistency and minimizes unnecessary storage usage. It also improves overall data quality and ensures teams rely on a single, consistent source of information for analysis and operations.
5.5. Improved AI and analytics workflows
Data catalogs support AI and analytics workflows by making datasets and metadata easier to access and organize. Teams can quickly find training data and relevant analytical resources. This accelerates model development and improves efficiency in data-driven projects, including machine learning and advanced analytics initiatives.

Data catalogs support AI and analytics workflows through better dataset management
5.6. Stronger compliance and auditability
Data lineage tracking and governance features help organizations monitor how data is accessed and used across systems. This improves audit readiness and supports regulatory compliance requirements. It also increases transparency and accountability, ensuring proper control of data usage in enterprise environments.
6. Data Catalog Use Cases Across Industries
Data catalogs are widely used across industries to improve data discovery, governance, analytics workflows, and operational efficiency in complex business environments.
6.1 In Financial Services
Financial organizations use data catalogs to manage large volumes of transactional, compliance, and customer data across multiple systems and platforms. This improves governance, reporting accuracy, and regulatory compliance while also supporting fraud detection, risk analysis, and real-time financial decision-making across enterprise workflows.
For example, a bank can use a data catalog to track transaction data across different systems, helping detect suspicious activities faster and ensuring compliance with financial regulations.

Data catalogs help financial organizations improve compliance, fraud detection, and data governance
6.2 In Healthcare
Healthcare providers use data catalogs to organize patient records, clinical data, medical research, and operational information across multiple departments. This improves data visibility, enhances collaboration between medical and analytics teams, and supports better decision-making while ensuring strict compliance with healthcare data privacy regulations.
For instance, a hospital can use a data catalog to unify patient information from various departments, making diagnosis and treatment processes more accurate and efficient.
6.3 In Technology
Technology companies use data catalogs to manage engineering data, APIs, cloud infrastructure, and analytics resources across development workflows. This improves data accessibility, system transparency, and operational efficiency for engineering teams while also supporting large-scale software development and infrastructure monitoring processes.
For example, Uber built Databook, an internal metadata platform that manages metadata for datasets, dashboards, and business metrics. Uber says Databook helps employees discover, explore, and use data more effectively (Databook: Turning Big Data Into Knowledge With Metadata at Uber, n.d.).

Technology companies use data catalogs to organize engineering and cloud data more efficiently
6.4 In Technology and SaaS
SaaS companies use data catalogs to manage customer analytics, application logs, and business intelligence datasets across cloud environments. This improves metadata organization and enables teams to access and analyze data more efficiently while supporting faster product development, feature optimization, and data-driven operational decisions.
For instance, a SaaS platform can use a data catalog to analyze user activity logs and improve product features based on real usage behavior.
6.5 In Retail and E-commerce
Retail and E-commerce businesses use data catalogs to manage product data, customer behavior, sales analytics, and inventory information across systems. This improves data organization, supports personalized marketing strategies, demand forecasting, and operational planning while ensuring consistent reporting across departments.
For instance, Allegro, one of Europe’s major e-commerce marketplaces, used Alation to gain faster value from data (What Is Data Lineage?, 2025). This helps teams understand how product, transaction, and inventory data moves across systems before it reaches business reports.

Data catalogs help retailers improve analytics, inventory management, and personalized shopping experiences
6.6 In AI and Machine Learning
AI and machine learning workflows require large volumes of structured datasets for training, testing, and evaluation processes. Data catalogs help organize datasets, metadata, and model resources, improving accessibility and collaboration while reducing time spent searching for data and accelerating development cycles across AI projects.
For instance, an AI team can use a data catalog to quickly locate labeled training datasets, speeding up model training and experimentation.
When preparing training datasets for AI models, having a well-organized data catalog becomes especially important for maintaining data consistency and improving AI workflow management. Platforms such as FPT AI Studio’s Data Hub provide a centralized environment to manage, version, and access datasets before integrating them into AI pipelines or Model Fine-Tuning workflows.
7. Frequently Asked Questions
7.1 What are common challenges in adopting data catalogs?
Organizations may face challenges such as inconsistent metadata, integration complexity, poor data quality, and limited adoption across teams. Maintaining accurate and updated metadata also requires ongoing governance and management.
7.2 What is the difference between a dataset and a data catalog?
A dataset is a collection of related data used for storage, processing, analysis, or machine learning. It can come from multiple sources and supports decision-making. A data catalog helps organize, manage, and search datasets and other data assets across an organization for easier access and use.
7.3 What is the difference between a data catalog and a data dictionary?
A data dictionary stores technical definitions of data fields and database structures, focusing mainly on schema-level information. A data catalog offers broader features such as metadata management, data discovery, governance, and lineage tracking, helping organizations manage and understand data assets more effectively.
7.4 Why are data catalogs important for AI?
Data catalogs are important for AI because AI workflows depend on well-organized and accessible datasets for training, testing, and analytics. They improve dataset management, traceability, collaboration, and overall workflow efficiency, helping teams build and deploy AI models faster and more reliably.
7.5 How does a data catalog improve data governance?
Data catalogs improve data governance by centralizing metadata, permissions, lineage tracking, and access controls across systems. This enables organizations to enhance data security, ensure regulatory compliance, increase transparency, and maintain consistent governance practices across all data assets.
In summary, data catalogs help organizations improve data discovery, governance, collaboration, and analytics efficiency across modern business environments. They play an important role in managing growing volumes of enterprise data while supporting AI, machine learning, and data-driven decision-making workflows.
Businesses can get started with FPT AI Factory and receive $100 in credits to use services immediately after signing in, allowing quick access to cloud infrastructure, AI development environments, and scalable computing resources directly on the platform. For enterprises or organizations with customized requirements, large-scale deployments, or AI-intensive workloads, FPT AI Factory also provides consultation and tailored infrastructure solutions based on specific project needs through the contact form.
Contact information
- Hotline: 1900 638 399
- Email: support@fptcloud.com


