
Active learning in machine learning is a powerful training strategy that allows models to achieve high accuracy by selectively querying the most informative data points. Understanding how active learning works helps organizations build smarter, more efficient AI systems without the need for massive labeled datasets. At FPT AI Factory, we provide cutting-edge AI solutions that empower businesses to apply active learning effectively across real-world machine learning pipelines.
1. What Is Active Learning in Machine Learning?
Active learning is a machine learning approach where the model takes an active role in its own training. Rather than passively consuming a pre-labeled dataset, it proactively selects the most informative data points from a pool of unlabeled data and queries a human annotator to label them. This gives the model more control over what it learns, making each labeled example count significantly more than in traditional training pipelines.
This approach becomes especially valuable when you’re dealing with large volumes of unlabeled data but face tight constraints on labeling budgets or annotation resources. Instead of requiring massive amounts of annotated data upfront, active learning identifies uncertain or difficult examples, those where the model lacks confidence, and requests human input only for those specific instances. The result is a leaner, more cost-effective path to building high-performing models.

Active learning is a machine learning approach where the model takes an active role
2. How Does Active Learning Work?
At its core, active learning operates as a continuous feedback loop between the model and a human annotator. Below is a simplified flow of how the process unfolds:
2.1 Start with a small labeled dataset
Every active learning pipeline begins with a modest seed of labeled data, just enough for the model to start recognizing basic patterns. This initial labeled set gives the model a foundation to work from, allowing it to perform better than random guessing right out of the gate. The goal here isn’t perfection, it’s giving the model enough context to make meaningful decisions about what to learn next.
2.2 Train an initial model
With the seed dataset in hand, you train a first version of the model. This baseline model won’t be highly accurate yet, but that’s expected and intentional. Its primary purpose at this stage is to evaluate the unlabeled data pool and identify where it feels least confident. Think of it as the model raising its hand and saying, “I’m not sure about these – can you help?”
2.3 Select the most informative unlabeled samples
This is where active learning truly differentiates itself. Rather than labeling data at random, the model actively identifies which unlabeled points are most uncertain or ambiguous, concentrating effort on the examples most likely to improve its performance. Common selection strategies include uncertainty sampling, diversity sampling, and query by committee, each suited to different data types and task requirements.
2.4 Human-in-the-loop labeling
The selected samples are then passed to a human annotator, a domain expert who provides accurate labels for those specific data points. This makes active learning a key component of the human-in-the-loop paradigm, where human judgment is applied precisely where the model needs it most. By focusing annotation effort on high-value samples, teams can dramatically reduce the time and cost associated with data labeling.
2.5 Retrain and repeat the cycle
Once the newly labeled samples are added to the training set, the model is retrained, and the entire cycle begins again. Each iteration feeds the model high-impact examples rather than random ones, continuously improving accuracy without requiring large volumes of labeled data. Over multiple rounds, the model converges toward strong performance far more efficiently than conventional supervised learning approaches.
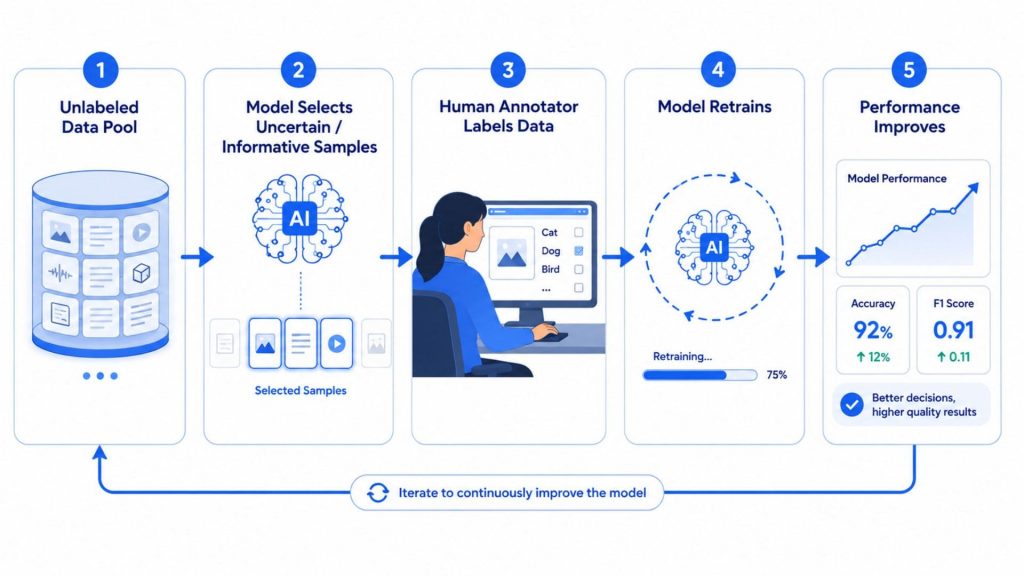
Active learning operates as a continuous feedback loop between the model and a human annotator
3. Active Learning vs Traditional Supervised Learning
Traditional supervised learning relies on a pre-defined, static set of labeled data, while active learning algorithms actively participate in the data selection process, making the two approaches fundamentally different in both philosophy and practice. The table below breaks down the key distinctions:
| Criteria | Traditional Supervised Learning | Active Learning |
| Training data approach | Trains on a fixed, fully labeled dataset prepared in advance | Starts with a small labeled set and grows it iteratively through querying |
| Labeling process | All data is labeled upfront before training begins | Data is labeled incrementally, only when the model requests it |
| Human involvement | Heavy upfront annotation effort; minimal involvement after that | Continuous but targeted, humans label only the most informative samples |
| Data efficiency | Requires large volumes of labeled data to perform well | Achieves comparable or better accuracy with significantly fewer labeled samples. |
| Cost efficiency | High cost due to mass annotation requirements | Lower cost: Annotation budget is focused on high-impact data points |
| Model improvement cycle | One-shot training: Improvements require full retraining with new data | Iterative loop: Model improves continuously with each labeling round |
| Best use case | Abundant labeled data, stable domains, and sufficient budget | Limited time, budget, or annotation resources; large pools of unlabeled data available |
| Example | Training an image classifier on 100,000 pre-labeled photos | Training a medical image detector using only 500 expert-labeled scans, selected by the model |
4. Common Active Learning Strategies
Not all active learning setups look the same. Depending on your data type, infrastructure, and annotation constraints, different query strategies will follow different scenarios. Here are the most widely used ones.
4.1 Pool-based active learning
In pool-based sampling, data samples are chosen for labeling from a pool of unlabeled data, allowing the model to focus on more than one data point at a time and select the most informative ones based on a chosen informativeness measure. This is the most common active learning setup and works well when you have a large static dataset ready to be mined.
Researchers applied pool-based active learning to breast cancer detection, where the model selected the most uncertain medical images from a large unlabeled pool and asked pathologists to label only those. This approach significantly reduced annotation effort while maintaining high diagnostic accuracy.
4.2. Uncertainty sampling
Uncertainty-based strategies are among the most convenient approaches for querying labels, and despite their simplicity, they have shown strong performance across a wide range of tasks. The model identifies data points it is least confident about and prioritizes those for human annotation.
A 2026 Springer study applied uncertainty sampling alongside BERT-based classifiers for text classification, selecting samples near the decision threshold for human annotation across 10 datasets. The results showed a significant reduction in labeled data requirements without sacrificing model performance.
4.3. Query-by-committee
Query-by-committee involves training multiple models on different subsets of the labeled dataset and selecting samples based on the level of disagreement among those models. Where the committee disagrees most, that’s where the most learning opportunity lies.
In a wood dating study, query-by-committee was used to train multiple models and identify samples where predictions disagreed most, directing labeling effort to the most ambiguous data points. This approach maximized knowledge gain per annotation compared to random selection.
4.4. Margin or entropy sampling
Margin sampling looks at the gap between a model’s top two predicted probabilities, a small margin signals high uncertainty. Entropy sampling takes a broader view, measuring uncertainty across all possible labels for a given sample, with higher entropy indicating a more uncertain and therefore more informative data point.
In a clinical NLP study using the i2b2/VA corpus, margin and entropy-based sampling were used to select the most uncertain sentences from clinical notes for expert annotation. Uncertainty sampling methods outperformed all other strategies in efficiently extracting medical concepts
4.5. Diversity sampling
Rather than only chasing uncertainty, diversity sampling ensures the model is exposed to a wide variety of data patterns. It ranks unlabeled examples based on how dissimilar they are from those already in the training set, with the most diverse examples selected to improve the model’s ability to generalize.
Researchers using active learning for autonomous driving found that diversity-aware strategies helped expose models to rare but safety-critical road scenarios, not just common driving patterns. This was particularly effective in closing the performance gap between majority and minority object classes.
4.6. Stream-based selective sampling
In stream-based selective sampling, each incoming unlabeled instance is evaluated by the model in turn, and the model decides whether to request a label for that instance or let it pass, based on an informativeness criterion such as model uncertainty. This strategy is particularly suited to real-time applications where data arrives continuously.
In real-life credit card fraud detection, transactions arrive as a continuous stream and human investigators can only review a limited number of cases per day, making stream-based active learning a natural fit for targeting the riskiest transactions for labeling. This setup allows the model to stay accurate despite evolving fraud patterns over time.
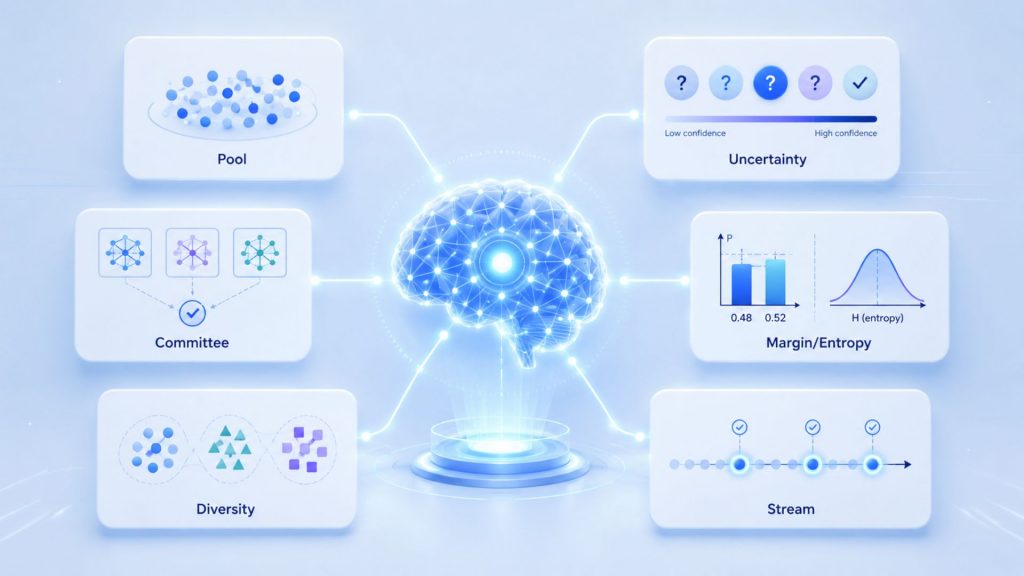
Different query strategies will follow different scenarios
5. Benefits of Active Learning in Machine Learning
Active learning delivers meaningful advantages for teams looking to build high-performing AI systems without the overhead of traditional data labeling workflows:
- Reduces data labeling costs: Annotation effort is concentrated on the samples that matter most, significantly cutting the volume of data that needs human review.
- Improves model accuracy with fewer labeled samples: By training on the most informative data points, models can achieve strong performance levels with a fraction of the labeled data typically required.
- Speeds up model development cycles: Iterative training loops allow teams to ship better models faster, without waiting for large labeled datasets to be assembled upfront.
- Focuses annotation effort on high-value data: Human expertise is directed precisely where it has the greatest impact, reducing wasted time on redundant or easy-to-classify samples.
- Helps models adapt to new data patterns: The continuous retraining cycle allows models to stay current as data distributions shift over time, making them more resilient in production environments.
- Supports human-in-the-loop machine learning workflows: Active learning keeps domain experts meaningfully involved in the training process, ensuring model outputs remain accurate, contextual, and aligned with real-world requirements.

Active learning delivers meaningful advantages for teams looking to build high-performing AI systems (Source: FPT AI Factory)
6. Active Learning Use Cases
Active learning is proving its value across a wide range of industries, anywhere that labeled data is scarce, expensive, or requires specialized expertise to produce. Below are some of the most impactful areas where this approach is making a difference.
6.1 Image classification and computer vision
In computer vision, labeling large volumes of images or video frames for tasks like object detection, segmentation, and classification is one of the most resource-intensive bottlenecks in AI development. Active learning helps by having the model identify only the most ambiguous or informative frames for human annotation, drastically cutting the amount of manual labeling required.
NVIDIA implemented a scalable active learning approach for autonomous driving, finding that data selected with active learning yielded 3x improvement in pedestrian detection precision and 4.4x on bicycle detection compared to manually curated data. This was achieved by using an ensemble of models to flag the most uncertain frames for human annotation, rather than labeling footage at random.
6.2 Natural language processing
NLP tasks such as text classification, named entity recognition (NER), and sentiment analysis require domain-annotated text data, which is both costly and slow to produce. Active learning reduces this burden by targeting only the most uncertain or ambiguous examples for expert review, making it possible to build high-performing NLP models with far fewer labeled samples.
6.3 Fraud detection
Financial fraud detection systems must process millions of transactions continuously, yet labeling every suspicious case for human review is neither practical nor cost-effective. Stream-based active learning is particularly well-suited here, as it allows the model to select data points for labeling as they arrive in a stream, enabling real-time adaptation to evolving fraud patterns.
6.4 Medical diagnosis and healthcare AI
Medical AI models require expert annotation from clinicians, a resource that is both limited and expensive. Annotating large volumes of medical images, lab results, or clinical notes is often impractical. Active learning enables healthcare teams to build accurate diagnostic models by focusing labeling effort on the most clinically ambiguous cases.
6.5 Recommendation systems
Recommendation engines depend heavily on user preference data, but collecting sufficient ratings, especially from new users, is a persistent challenge. Active learning addresses this by strategically selecting which items to present to users for feedback, maximizing the informativeness of each interaction rather than relying on passive behavior signals alone.
6.6 AI model experimentation and training workflows
Beyond domain-specific applications, active learning plays a central role in how data science teams structure and iterate on their ML development workflows. Experimenting with different query strategies, evaluating model uncertainty thresholds, and tracking performance improvements across retraining cycles all require a flexible, reproducible development environment.
This is where having the right tooling makes a significant difference. Data scientists need a dedicated notebook environment to experiment with datasets, test active learning strategies, retrain models iteratively, and track performance across development cycles, all within a single platform.
FPT AI Factory’s AI Notebook is built for exactly this kind of workflow, providing a collaborative, cloud-based workspace where ML teams can run active learning experiments at scale, manage data versions, and move seamlessly from prototyping to production-ready models.
FPT AI Factory’s AI Notebook provides a collaborative, cloud-based workspace (Source: FPT AI Factory)
7. Active Learning in Modern ML Workflows
Active learning doesn’t exist in isolation, it fits naturally into the broader ecosystem of modern ML development, from how teams handle human feedback to how they manage model performance over time. Here’s how it connects with each key layer of a production ML workflow.
7.1. Human-in-the-loop AI systems
Human-in-the-loop (HITL) means that humans are involved at some point in the AI workflow to ensure accuracy, safety, accountability, or ethical decision-making, and active learning is one of the most powerful implementations of this paradigm. Rather than treating human annotation as a one-time setup cost, HITL systems use active learning to continuously route the most uncertain or edge-case samples back to human experts.
This is especially critical in high-stakes domains like healthcare, legal AI, and financial services, where model errors carry significant consequences. Keeping human experts in the AI training and evaluation loop is the most effective way to maintain output quality, since even the most capable models struggle with niche edge cases that only subject matter experts can resolve.
7.2. Data annotation and feedback loops
Active learning fundamentally transforms the role of data annotation in ML workflows, shifting it from a one-time, bulk effort to a continuous, targeted process. The iterative cycle of selecting uncertain samples, sending them to human annotators, incorporating newly labeled data, and retraining the model repeats until the desired performance level is achieved or the labeling budget is exhausted.
This creates a structured feedback loop where every annotation round makes the model smarter and more selective. AWS reports that implementing active learning-based annotation pipelines can reduce labeling costs by over 90% and accelerate the annotation process from weeks to hours, while enabling reusability across similar ML data labeling tasks.
7.3. Iterative model retraining
One of the defining characteristics of active learning in practice is that model training is never truly “finished.” The active learning loop repeats the steps of query strategy, human annotation, and model update in a cycle, continuing until the model reaches a desired level of performance, stops improving, or meets a predefined stopping rule.
This iterative retraining approach makes models progressively more robust without requiring large labeled datasets upfront. Each new batch of high-quality labeled samples sharpens the model’s decision boundaries, reduces uncertainty in previously ambiguous regions, and prepares it to handle real-world data distributions more reliably.
7.4. Experiment tracking and evaluation
Running active learning cycles across multiple retraining rounds generates a significant amount of experimental data, different query strategies, varying uncertainty thresholds, and incremental model versions all need to be tracked and compared systematically. In ML systems, tracking what worked and what didn’t while maintaining reproducibility is a core challenge, and without systematic experiment tracking, development becomes difficult to manage or replicate.
Robust evaluation at each retraining iteration is equally important. Teams need to measure not just overall accuracy, but also how the model performs on rare or underrepresented classes, the very cases that active learning is designed to improve. Tools like MLflow, Weights & Biases, or integrated notebook environments help data scientists log parameters, compare runs, and make informed decisions about when to continue or stop the active learning loop.
7.5. Continuous learning pipelines
At scale, active learning becomes the engine of a continuous learning pipeline, a system that keeps improving automatically as new data flows in. Continuous monitoring is a critical part of the MLOps pipeline lifecycle, as it helps identify and minimize the impact of data drift and concept drift, which can cause models to become obsolete and respond with less accurate results over time.
By embedding active learning into a CI/CD-style ML pipeline, teams can automate the process of selecting uncertain samples, triggering annotation jobs, retraining models, and deploying updated versions, all without manual intervention at each step. This is the foundation of an adaptive AI system that learns from production data continuously, not just at deployment time.

Active learning doesn’t exist in isolation, it fits naturally into the broader ecosystem
8. Challenges of Active Learning
Despite its advantages, implementing active learning in real ML workflows comes with a distinct set of challenges that teams should anticipate:
- Requires reliable human annotators: The cost of human annotation is one of the primary challenges, especially for complex tasks that require experts with in-depth domain knowledge to provide accurate labels. Inconsistent or low-quality annotations can degrade model performance across retraining cycles.
- Depends on initial model quality: Active learning relates to the model’s uncertainty estimates to guide sample selection. A weak initial model may produce unreliable signals, leading the query strategy to select poor or redundant samples in early rounds – a problem sometimes called the “cold start” issue.
- Can introduce sampling bias: Sampling bias is a recognized risk in active learning, along with poor uncertainty calibration, class imbalance in the labeled set, and annotation errors on hard examples. Over time, this can skew the training distribution and hurt generalization.
- Needs careful query strategy selection: Most selection strategies are hand-designed, and it has become clear that there is no single best active learning strategy that consistently outperforms all others across all applications, meaning teams must evaluate and tune their approach for each specific task and dataset.
- May increase workflow complexity: Compared to standard supervised learning, active learning introduces additional pipeline components, query engines, annotation interfaces, retraining triggers, and performance monitors. Setting up a complete active learning framework can be quite time-consuming, especially when combining multiple methods.
- Requires monitoring model performance across iterations: Because the model evolves with each retraining round, performance can fluctuate between cycles. Without consistent evaluation metrics and monitoring in place, teams risk deploying a version that underperforms on certain data segments, particularly rare or newly emerging classes.
9. FAQs
9.1. Is active learning supervised or unsupervised learning?
Active learning is generally considered a form of supervised learning because it relies on labeled data to train models. However, what makes it unique is that the model actively selects the most informative unlabeled samples and queries a human (or oracle) to label them. So while it operates within the supervised learning paradigm, it reduces labeling costs by choosing which data should be labeled.
9.2. What is the difference between active learning and supervised learning?
The key difference is in how training data is obtained. In traditional supervised learning, the model passively learns from a fully labeled dataset that is prepared in advance. In contrast, active learning allows the model to iteratively select the most useful unlabeled data points and request labels for them. This makes active learning more efficient, especially when labeling data is expensive or time-consuming.
9.3. Why is human-in-the-loop important in active learning?
Human-in-the-loop is crucial because active learning depends on accurate labeling of selected data points. Humans provide high-quality annotations that guide the model toward better performance. Without human involvement, the system cannot obtain reliable labels for uncertain or complex cases, thereby limiting the effectiveness of the learning process.
9.4. Is active learning useful for large language models?
Yes, active learning can be useful for large language models (LLMs), especially during fine-tuning. It helps prioritize which data samples should be labeled or reviewed, improving efficiency when dealing with massive datasets. Combined with techniques like reinforcement learning from human feedback (RLHF), active learning can enhance model performance while reducing the need for extensive manual labeling.
If you are ready to take the next step, explore the capabilities of FPT AI Factory and unlock a more efficient approach to building intelligent systems. If you are ready to accelerate your development, explore our Starter Plan today.
New users receive a free $100 credit and can start using it immediately after logging in, with no setup delay. This credit is valid for 30 days and includes:
- $10 for GPU Container and $10 for GPU Virtual Machine
- $10 for AI Notebook and $70 for AI Inference & AI Studio
- Access to up to 5M tokens with Llama-3.3 and 20+ other state-of-the-art models
For enterprises or organizations requiring customization or large-scale deployment, we encourage you to contact FPT AI Factory directly via the official contact form to receive tailored support and solutions.
In conclusion, active learning in machine learning offers a powerful way to build smarter models with less labeled data by focusing only on what truly matters. With the support of FPT AI Factory, businesses can accelerate this process, optimize resources, and bring intelligent solutions to market faster than ever before.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more articles
Transfer Learning vs. Fine-Tuning: Key Differences Explained
What is Fine-Tuning? An In-Depth Guide for When to Use
What Is Training Data? Examples, Types & Why It Matters


