
To improve the accuracy of AI-generated content, many systems now combine generation with external data sources. This article explains what is retrieval augmented generation and how it works in modern AI systems, with practical insights from FPT AI Factory.
1. What is retrieval augmented generation?
Retrieval augmented generation (RAG) is an AI approach that combines information retrieval with generative models to produce more accurate and context-aware responses. Instead of relying only on what a model learned during training, RAG retrieves relevant data from external sources and uses that information to guide the output.
In practice, retrieval augmented generation helps AI systems:
- Ground responses in real data: The model uses retrieved documents as context, reducing reliance on memorized knowledge.
- Stay up to date: External knowledge bases can be updated without retraining the model.
- Reduce hallucination: By referencing actual data, the system is less likely to generate unsupported or incorrect information
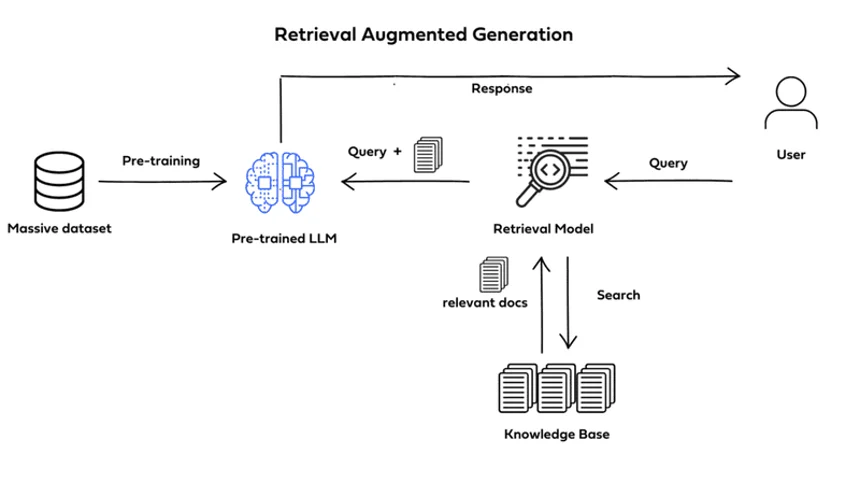
Retrieval augmented generation consists of multiple steps
2. How does retrieval augmented generation work?
Retrieval augmented generation works by adding a retrieval step before the generation process, allowing the model to use external knowledge dynamically. At a high level, the workflow includes:
- Query understanding: The system processes the user query and converts it into a vector representation for search.
- Document retrieval: Relevant information is retrieved from a knowledge base using semantic search.
- Context injection: The retrieved content is added to the model input as additional context
- Response generation: The language model generates an answer based on both the query and the retrieved data
This pipeline allows the system to produce responses that are both fluent and grounded in relevant information.
3. What are the key components of retrieval augmented generation?
A retrieval augmented generation system is not a single model but a combination of components that work together to retrieve, process, and generate information. At the core, a RAG system typically includes four main layers:
- Retriever: Finds relevant documents based on semantic similarity rather than keyword matching, typically using vector search.
- Knowledge base: Stores structured or unstructured data such as documents, PDFs, or databases that can be queried in real time.
- Embedding model: Transforms text into vector representations, enabling efficient similarity search during retrieval
- Generator (LLM): Produces natural language responses using both the original query and retrieved context
4. When should you use retrieval augmented generation?
Retrieval augmented generation is most useful in situations where knowledge is dynamic and cannot be fully embedded into a model during training. In practice, RAG is often chosen over fine-tuning when systems need to work with continuously evolving data. For example, enterprise knowledge bases, product documentation, or internal reports are updated regularly, making retraining inefficient.
Another important factor is accuracy and traceability. Because RAG retrieves real documents, it becomes easier to understand where an answer comes from. This is especially relevant in business environments where explainability matters.
In general, RAG is better suited for knowledge-driven systems, while fine-tuning is more appropriate for behavior or style adaptation. To make the distinction clearer, here is a practical comparison:
| Scenario | Retrieval Augmented Generation | Fine-tuning |
| Frequently updated data | Works well without retraining | Requires retraining |
| Need for explainable answers | Can reference documents | Limited traceability |
| Custom tone/style | Limited control | Strong control |
| Implementation complexity | Moderate | Higher upfront effort |
5. Common use cases of retrieval augmented generation
Retrieval augmented generation is commonly applied in systems where answering questions accurately is more important than generating creative text.
- Enterprise knowledge search: Instead of navigating multiple documents, users can ask questions and receive direct answers grounded in internal data. This significantly reduces the time spent searching for information.
- Customer support automation: RAG allows chatbots to retrieve relevant help center articles or documentation, leading to more accurate and consistent responses compared to traditional rule-based systems.
- Document-heavy environments, such as legal, finance, or research. In these cases, the system can process large volumes of text and return concise insights without requiring users to manually read through entire documents.
- AI copilots and assistants: RAG has been integrated so that responses need to be both conversational and fact-based. By combining retrieval with generation, these systems can provide more reliable outputs in real-time scenarios.
In Retrieval Augmented Generation (RAG) systems, the ability to deliver real-time responses depends heavily on efficient model inference. Solutions like Serverless Inference from FPT AI Factory enable seamless deployment of large language models via API, allowing applications to scale automatically based on demand without the need to manage underlying infrastructure. This approach not only reduces operational complexity but also optimizes cost, making it well-suited for production-grade RAG use cases such as intelligent search, chatbots, and AI assistants.

RAG supports chatbots in the customer support industry for many businesses
6. What challenges does retrieval augmented generation have?
While retrieval augmented generation improves accuracy, it also introduces additional layers of complexity that need to be managed carefully. The main challenges includes:
- Retrieval quality: If the system retrieves irrelevant or low-quality documents, the generated response may still be incorrect, even if the language model performs well. This makes the retrieval step just as important as the generation step.
- Latency: Because RAG involves multiple steps, such as query processing, retrieval, and generation, the response time can be higher compared to standard language model inference. This becomes more noticeable when working with large-scale datasets.
- Complex system design: Unlike standalone models, RAG requires coordination between multiple components, including databases, embedding pipelines, and inference systems. This increases both development effort and maintenance overhead.
- Data management: The knowledge base must be continuously updated, cleaned, and structured to ensure relevant results. Poor data quality can directly impact system performance.
Because of these factors, implementing RAG effectively often depends not only on model selection but also on having the right infrastructure and system architecture in place.
Understanding what is retrieval augmented generation helps explain how modern AI systems improve accuracy by combining retrieval and generation. As retrieval augmented generation becomes more widely adopted, it plays a key role in building reliable and scalable AI applications. Individuals will receive $100 in credits upon registration, which can be used immediately after logging in, no setup or approval process required, so you can start building and experimenting right away. For businesses with more advanced needs, please reach out via FPT AI Factory contact form. FPT team will provide tailored consultation and support to match your specific requirements.
Contact information
- Hotline: 1900 638 399
- Email: support@fptcloud.com


