
NVIDIA’s latest AI GPUs are reshaping how enterprises build large-scale AI infrastructure, generative AI systems, and high-performance computing environments. As organizations scale AI workloads, choosing the right GPU architecture becomes critical for both operational efficiency and long-term ROI. In this article, FPT AI Factory helps you understand H200 vs B200, including architecture differences, AI workload performance, infrastructure requirements, and enterprise deployment considerations.
1. What Is NVIDIA H200?
NVIDIA H200 is a high-performance GPU designed for enterprises to run large-scale AI models and process massive amounts of data. Its key advantage is its large memory capacity of up to 141GB and ultra-fast memory bandwidth of around 4.8 TB/s, which helps accelerate data processing and enables AI systems to operate more efficiently, with smoother and faster performance compared to previous generations.
For example, a company running an AI infrastructure to analyze millions of customer conversations in real time can process data more efficiently with NVIDIA H200, enabling faster responses and smoother AI operations.

NVIDIA H200 GPU architecture powering enterprise AI training and large language model workloads
2. What Is NVIDIA B200?
NVIDIA B200 is an enterprise AI GPU built on the Blackwell architecture, designed for next-generation AI data centers and GPU clusters. Its key advantages include up to 192GB of HBM3e memory, memory bandwidth of around 8 TB/s, and advanced FP4 support, helping accelerate AI training and inference while improving efficiency for massive AI systems compared to previous generations.
For instance, a company building an AI infrastructure to train a large language model with billions or trillions of parameters can use NVIDIA B200 to process massive datasets across multiple GPUs more efficiently.

NVIDIA B200 Blackwell GPU infrastructure optimized for next-generation generative AI workloads
>> Explore more: What is Nvidia Blackwell? Architecture and specs overview
3. H200 vs B200: Key Differences
Organizations evaluating modern AI infrastructure increasingly compare Hopper and Blackwell GPU architectures based on scalability, efficiency, and workload optimization. Here is a table comparing the key differences between H200 and B200.
| Criteria | H200 | B200 |
| Architecture | Hopper | Blackwell |
| GPU generation | Current-generation AI GPU | Next-generation AI GPU |
| Memory type and capacity | 141 GB HBM3e | 192 GB HBM3e |
| Memory bandwidth | ~4.8 TB/s | ~8 TB/s |
| Tensor Core and precision support | FP8, FP16, BF16 | FP4, FP8, FP16, BF16 |
| FP8 vs FP4 optimization | Optimized for FP8 workloads | FP4 support for higher inference efficiency |
| AI training performance | Enterprise LLM training and fine-tuning | Trillion-parameter model training |
| AI inference optimization | Enterprise generative AI inference | Hyperscale inference workloads |
| Energy efficiency | High performance-per-watt | Improved efficiency with FP4 |
| NVLink and networking ecosystem | NVLink Gen 4 | NVLink Gen 5 |
| Multi-GPU scalability | Enterprise-scale training | Hyperscale AI clusters |
| Best workload type | AI training, inference, and HPC | Frontier AI, AI agents, massive models |
| Deployment cost | High | Very high |
H200 remains highly capable for enterprise AI training, inference, and HPC workloads, especially in existing Hopper environments. However, B200 offers stronger efficiency and scalability for next-generation large-scale generative AI workloads.
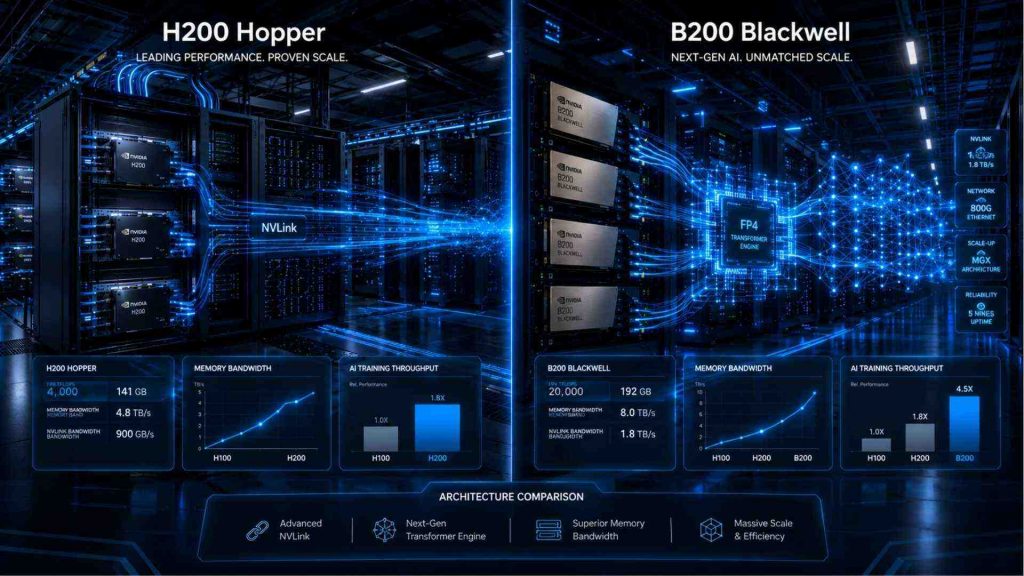
Enterprise comparison between NVIDIA H200 Hopper and B200 Blackwell AI GPU architectures
4. H200 vs B200 Performance for AI Workloads
Modern AI infrastructure performance depends on workload type, model architecture, memory requirements, and scaling efficiency. The following table summarizes the key differences between H200 and B200 across major AI workloads.
| AI Workload | H200 | B200 | Recommended GPU |
| Large Language Model (LLM) Training | Strong performance for enterprise LLM training | Higher performance for trillion-parameter models with FP4 acceleration | B200 for large-scale training |
| AI Inference at Scale | Optimized for enterprise generative AI inference | Higher throughput and lower latency for hyperscale inference | B200 for hyperscale inference |
| Retrieval-Augmented Generation (RAG) | Strong memory bandwidth for vector retrieval and inference | Better scalability for distributed RAG systems and reasoning models | H200 for enterprise RAG |
| Generative AI and Multimodal Models | Suitable for multimodal AI workloads | Optimized for next-generation multimodal foundation models | B200 for foundation models |
| Scientific Computing and HPC | Excellent support for HPC and simulation workloads | Higher compute density and scaling efficiency | H200 for standard HPC |
Overall, both H200 and B200 deliver strong AI computing capabilities, but they serve slightly different enterprise needs. The following sections discuss these workload-specific differences in greater detail.
4.1 Large language model training
H200 supports enterprise LLM training, fine-tuning, and transformer workloads that require strong memory bandwidth and multi-GPU performance. It is suitable for businesses training domain-specific or medium-to-large AI models.
B200 is better for larger-scale LLM training, especially frontier or trillion-parameter models. With Blackwell architecture and FP4 acceleration, B200 provides stronger scaling efficiency and faster training performance for more demanding AI infrastructure.
For example, NVIDIA states that DGX B200 systems can deliver significantly higher AI training performance for large enterprise LLM workloads compared to previous Hopper-generation infrastructure (NVIDIA DGX B200, n.d.).
>> Explore more: LLM Large Language Model Training & Fine Tuning Guide
4.2 AI inference at scale
H200 performs well for enterprise inference workloads, including chatbot deployment, generative AI applications, and transformer-based production models.
B200 is stronger for hyperscale inference environments that need lower latency, higher throughput, and support for many concurrent AI requests. In short, H200 fits enterprise inference, while B200 fits hyperscale inference.
For instance, NVIDIA reports that Blackwell infrastructure is optimized for large-scale AI inference environments supporting massive concurrent AI requests and real-time generative AI services (AI Inference at Scale With NVIDIA Blackwell, n.d.).

Enterprise AI inference infrastructure using H200 and B200 GPUs for scalable production deployment
>> Explore more: What is AI inference? How it works, types, and use cases
4.3 Retrieval-augmented generation (RAG)
H200 is suitable for most enterprise RAG workloads, such as internal knowledge search, document intelligence, and customer support assistants. Its memory bandwidth helps support vector retrieval and LLM inference efficiently.
B200 is more suitable for large-scale RAG systems that involve larger knowledge bases, longer context windows, distributed infrastructure, or advanced reasoning models.
For example, NVIDIA GB200 NVL72 infrastructure is designed to accelerate reasoning models and large retrieval-based AI workloads across distributed AI environments (NVIDIA GB200 NVL72, n.d.).
4.4 Generative AI and multimodal models
H200 can support enterprise generative AI and multimodal workloads, including text, image, audio, and video-based AI applications. It provides strong performance for model training, fine-tuning, and inference across a wide range of business AI use cases.
Meanwhile, B200 is better for next-generation multimodal foundation models that require higher compute density, stronger scaling efficiency, and more advanced AI pipelines.
For instance, NVIDIA highlights Blackwell GPUs as infrastructure optimized for multimodal generative AI and trillion-parameter foundation models across enterprise AI platforms (NVIDIA Blackwell Architecture, n.d.).
Multimodal generative AI infrastructure using next-generation NVIDIA GPU platforms
4.5 Scientific computing and HPC
H200 is a strong option for standard enterprise HPC, simulation, and memory-intensive scientific computing workloads, delivering a good balance of performance, scalability, and cost efficiency.
At the same time, B200 provides better performance for large-scale HPC, AI supercomputing, and advanced simulation workloads that require higher compute density, stronger scalability, and faster processing across large GPU clusters.
For example, NVIDIA DGX SuperPOD powered by Blackwell GPUs is designed for large-scale AI supercomputing and scientific computing environments handling complex HPC workloads (NVIDIA DGX SuperPOD – a Turnkey AI Supercomputer, n.d.).
5. Infrastructure and Deployment Considerations
Enterprise GPU adoption depends not only on raw performance but also on infrastructure readiness, scalability, and operational efficiency. Here are several important deployment considerations organizations should evaluate when comparing H200 and B200 infrastructure.
5.1 Power and cooling requirements
Modern AI GPUs consume significant power during large-scale AI training and inference operations. B200 infrastructure may require higher power density and more advanced cooling systems because next-generation AI clusters operate at larger compute scales. Enterprises deploying hyperscale GPU infrastructure often need upgraded power delivery and thermal management systems to maintain operational stability. As AI clusters continue growing in density, efficient cooling architecture becomes increasingly important for long-term datacenter sustainability.

Enterprise AI datacenter cooling and power infrastructure supporting advanced GPU clusters
5.2 Rack density and data center readiness
Higher GPU density improves compute scalability but increases infrastructure complexity across datacenter environments. Blackwell-based deployments may require more advanced rack-level power and airflow planning to support next-generation AI scaling requirements. Enterprises modernizing AI infrastructure often redesign rack architecture to support larger GPU clusters and higher networking throughput. Consequently, infrastructure readiness becomes a major consideration before adopting large-scale AI systems.
5.3 NVLink and networking requirements
Distributed AI workloads depend heavily on high-speed networking and low-latency GPU communication. Both H200 and B200 leverage NVLink ecosystems for scalable multi-GPU communication across enterprise AI clusters. However, Blackwell infrastructure expands networking scalability further for next-generation AI environments requiring larger distributed deployments. This helps enterprises improve synchronization efficiency across massive transformer model training operations.
Advanced NVLink networking infrastructure connecting enterprise AI GPU clusters
5.4 Multi-GPU cluster scalability
Modern generative AI systems frequently require distributed multi-GPU and multi-node scaling architectures. H200 already supports large-scale enterprise GPU clusters for AI training and inference operations. B200 further enhances scaling efficiency for future AI infrastructure requiring thousands of interconnected GPUs.
For example, hyperscale AI platforms may deploy Blackwell clusters across distributed datacenters. This works because advanced interconnect architecture improves synchronization and distributed workload efficiency.
5.5 Cloud vs on-premise deployment
Cloud-based GPU infrastructure provides flexibility and rapid scalability for organizations managing dynamic AI workloads. Meanwhile, on-premise deployments may offer stronger control over data governance, networking optimization, and long-term infrastructure economics. H200 is already widely available through enterprise cloud providers, while B200 adoption will expand progressively across hyperscale AI infrastructure platforms. Organizations should evaluate workload predictability, compliance requirements, and operational maturity before choosing deployment strategies.

Enterprise comparison between cloud-based and on-premise AI GPU infrastructure
6. Cost and ROI Considerations
GPU infrastructure investments increasingly require enterprises to balance performance, scalability, operational cost, and long-term ROI. Here is a table comparing important financial considerations between H200 and B200 infrastructure.
| Criteria | H200 | B200 |
| GPU acquisition cost | Typically around $30,000 – $40,000+ per GPU depending on configuration and deployment scale | Estimated $40,000 – $60,000+ per GPU for next-generation enterprise deployments |
| Cloud GPU pricing | Premium pricing around $3 – $10/hour depending on provider and region | Higher premium pricing estimated around $5 – $15+/hour |
| Training efficiency per dollar | Strong efficiency for enterprise LLM training and distributed AI workloads | Higher efficiency at hyperscale with improved throughput and FP4 acceleration |
| Inference cost efficiency | Excellent for FP8 inference and generative AI serving workloads | Improved efficiency for next-generation low-latency AI inference environments |
| Infrastructure upgrade cost | Moderate upgrades for Hopper-compatible AI clusters and networking | Significant upgrades may be required for Blackwell-scale infrastructure and power systems |
| Long-term operational cost | High but relatively stable with mature Hopper ecosystem | Potentially lower over time through better energy and compute efficiency |
| ROI for enterprise AI workloads | Strong ROI for current enterprise AI training and inference deployments | Strong long-term ROI for trillion-parameter AI scaling and hyperscale AI infrastructure |
H200 may provide stronger near-term ROI for enterprises already operating Hopper-based AI environments. However, B200 infrastructure could deliver greater long-term efficiency for organizations planning large-scale generative AI expansion and future AI infrastructure modernization.
7. Which GPU Should Businesses Choose?
Selecting between H200 and B200 depends heavily on workload scale, infrastructure maturity, operational goals, and long-term AI strategy. Here are several scenarios organizations should evaluate when comparing enterprise AI GPU investments.
7.1 When H200 Is the Better Option
H200 is suitable for enterprises needing stable AI infrastructure for LLM training, inference, and HPC workloads. The GPU delivers strong FP8 performance, high memory bandwidth, and scalable NVLink communication for distributed AI clusters and enterprise AI deployments.
For example, enterprises deploying large-scale transformer training workloads may choose H200 to balance AI performance, infrastructure maturity, and scalable multi-node GPU environments.
Managing large-scale AI workloads across multi-node GPU clusters can become difficult when teams must handle container orchestration, dependency management, and GPU resource allocation manually. GPU Container from FPT AI Factory helps enterprises deploy and manage scalable containerized AI environments more efficiently while improving GPU utilization and workload management across distributed AI infrastructure.
7.2 When B200 is the better long-term investment
B200 is more suitable for organizations planning long-term AI scaling, trillion-parameter model training, and next-generation generative AI infrastructure. The Blackwell architecture improves FP4 acceleration, energy efficiency, and multi-GPU scalability for future hyperscale AI deployments.
For instance, enterprises developing advanced multimodal AI systems may invest in B200 infrastructure for stronger long-term scaling efficiency and next-generation AI processing capabilities.
7.3 Cost-to-performance considerations
H200 offers strong enterprise AI performance with lower deployment complexity and a mature Hopper ecosystem, while B200 may deliver better long-term efficiency for hyperscale AI workloads despite higher infrastructure costs and upgrade requirements.
For example, enterprises with stable production AI workloads may prefer H200, while hyperscale AI providers may prioritize B200 for future large-scale AI expansion.
8. FAQs
8.1 Is B200 faster than H200 for AI training?
B200 is expected to deliver stronger AI training performance because the Blackwell architecture introduces FP4 optimization, improved Transformer Engine capabilities, and more advanced multi-GPU scaling. These improvements help accelerate trillion-parameter AI models and hyperscale training workloads more efficiently than current-generation Hopper infrastructure.
8.2 Which GPU is better for inference?
Both H200 and B200 are highly optimized for enterprise AI inference workloads. H200 performs strongly for generative AI and transformer inference, while B200 introduces FP4 optimization and improved inference efficiency for future hyperscale AI deployments handling massive concurrent AI requests and lower-latency inference environments.
8.3 Is B200 worth upgrading to?
B200 may be worth upgrading to for organizations planning long-term AI scaling, trillion-parameter model training, or advanced generative AI deployments. The Blackwell architecture improves energy efficiency, transformer optimization, and multi-GPU scalability, making it suitable for next-generation enterprise AI infrastructure modernization.
8.4 Can H200 handle large language models?
Yes, H200 is highly capable of supporting large language model training and inference workloads. The GPU provides up to 141GB HBM3e memory, strong FP8 acceleration, and scalable NVLink communication for distributed transformer models, making it widely used across enterprise generative AI infrastructure and cloud AI environments.
In summary, both H200 vs B200 GPUs play important roles in supporting modern AI infrastructure, large-scale model training, generative AI, inference workloads, and high-performance computing environments. While H200 provides strong performance for current enterprise AI deployments, B200 introduces next-generation scaling, FP4 optimization, and improved efficiency for trillion-parameter AI models and hyperscale AI infrastructure.
Individuals can get started with FPT AI Factory and receive $100 in credits through the Starter Plan, allowing quick access to GPU infrastructure, AI development environments, and scalable cloud computing resources directly on the platform. For enterprises with customized AI requirements, distributed AI deployments, or GPU-intensive workloads, FPT AI Factory also provides consultation and tailored infrastructure solutions designed for modern AI and high-performance computing environments.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore Related Articles:


