
The NVIDIA H100 GPU is a powerful accelerator for large-scale AI workloads, including LLM training, inference, and scientific computing. With an advanced architecture optimized for FP8 and FP16 performance and extremely high memory bandwidth, it sets the benchmark for modern AI infrastructure. However, its high cost makes direct adoption challenging for many businesses. FPT AI Factory enables flexible access to NVIDIA H100 GPU resources via a pay-as-you-go model, helping businesses scale compute power on demand without heavy upfront investment.
1. What Is the NVIDIA H100?
The NVIDIA H100 is a next-generation data center GPU built on the Hopper architecture, designed for large-scale AI, high-performance computing (HPC), and generative AI workloads. It is widely regarded as one of the most powerful accelerators for training and deploying modern AI models.
The NVIDIA H100 is engineered for extreme scalability. With high-bandwidth NVLink interconnect, advanced Tensor Cores, and ultra-fast memory bandwidth, it supports distributed training across massive GPU clusters. This makes it suitable for enterprise AI infrastructure, research institutions, and cloud-scale deployments.
In transformer-based workloads, the NVIDIA H100 can deliver up to 4x faster training performance compared to A100-class systems, depending on model architecture, workload configuration, and scaling efficiency. In financial services, this acceleration can support AI systems that process large transaction volumes in real time, detect anomalies faster, and improve fraud detection, risk analysis, and quantitative modeling workflows.
In financial institutions, GPUs like the NVIDIA H100 are used to power AI systems for fraud detection and risk analysis. For example, a bank can deploy machine learning models that continuously monitor millions of transactions in real time to identify unusual spending behavior or potential fraud. With the H100’s high-speed inference and parallel processing capabilities, these systems can flag suspicious activities within milliseconds, helping prevent financial losses. Additionally, in areas like quantitative trading, large-scale models can be trained faster to simulate market trends, optimize portfolios, and support data-driven investment decisions.

Unlike traditional GPUs, the H100 is optimized for transformer-based AI models (Source: FPT AI Factory)
>> Explore more: NVIDIA H100 vs H200: Key GPU differences and AI power
2. NVIDIA H100 full specs
The NVIDIA H100 Tensor Core GPU, built on the Hopper architecture, represents a major redesign of NVIDIA’s data center GPU stack. Instead of focusing only on raw compute performance, the H100 combines compute density, high-bandwidth memory, and interconnect scalability to support transformer-based AI workloads at enterprise and exascale levels.
Different H100 variants are optimized for different deployment scenarios.
- SXM is commonly used for high-performance training clusters where dense server design and maximum GPU-to-GPU bandwidth are important.
- PCIe is designed for flexible server integration, making it suitable for organizations that need to add H100 acceleration to existing data center systems.
- NVL is optimized for memory-heavy inference workloads, especially large language model serving, where higher GPU memory capacity and fast interconnects are critical.
These differences become clearer when looking at the H100’s core specifications, starting with its memory architecture, which plays a key role in supporting large-scale AI training and inference workloads.
2.1. VRAM (Memory Architecture)
The standard H100 integrates 80 GB of HBM3 memory in a 3D-stacked configuration, physically co-located with the compute die to minimize memory access latency and maximize data throughput to Tensor Cores.
This capacity allows large-scale AI models, including dense transformers with tens to hundreds of billions of parameters to retain model weights, optimizer states, and activation tensors on-device without frequent CPU offloading, which reduces inter-device data movement and improves training stability in distributed setups:
| Variant | Memory | Type |
| H100 SXM5 | 80 GB | HBM3 |
| H100 PCIe | 80 GB | HBM2e |
| H100 NVL | 94 GB | HBM3 |

The H100 uses 80GB of HBM3 memory in a stacked design for fast, high-bandwidth data access.
2.2. Memory Bandwidth
The H100 delivers up to 2.0–3.35 TB/s of memory bandwidth, depending on system configuration and form factor, which is achieved through an expanded HBM3 interface combined with an optimized memory controller architecture that is specifically engineered to handle concurrent high-volume tensor access patterns typical in transformer attention mechanisms.
Memory bandwidth varies significantly by form factor:
| Variant | Peak Memory Bandwidth |
| H100 SXM5 | ~3.35 TB/s |
| H100 PCIe | ~2.0 TB/s |
| H100 NVL | ~3.94 TB/s |
In practice, this level of bandwidth is critical because modern AI workloads are increasingly memory-bound rather than compute-bound, meaning that the GPU’s ability to continuously feed data into Tensor Cores directly determines training efficiency, and the H100 addresses this bottleneck by significantly increasing sustained data throughput across the entire memory subsystem.
2.3. Compute Performance (TFLOPs Across Precision Formats)
The compute architecture of the H100 is centered around 4th-generation Tensor Cores combined with the Transformer Engine, which introduces native support for FP8 precision and dynamically adapts computation formats at runtime in order to maximize throughput while preserving numerical stability across different layers of deep neural networks.
H100 SXM5 peak theoretical performance:
| Precision | Dense | With Sparsity |
| FP8 | ~1,979 TFLOPS | ~3,958 TFLOPS |
| FP16 / BF16 | ~989 TFLOPS | ~1,979 TFLOPS |
| TF32 | ~495 TFLOPS | ~989 TFLOPS |
| FP32 | ~67 TFLOPS | — |
| FP64 | ~34 TFLOPS | ~67 TFLOPS |
The key architectural advantage here is not only the raw increase in FLOPs compared to previous generations, but the introduction of a dynamic precision management system that automatically selects the most efficient numerical format per tensor operation, which effectively reduces memory traffic and increases sustained utilization during large-scale transformer training.
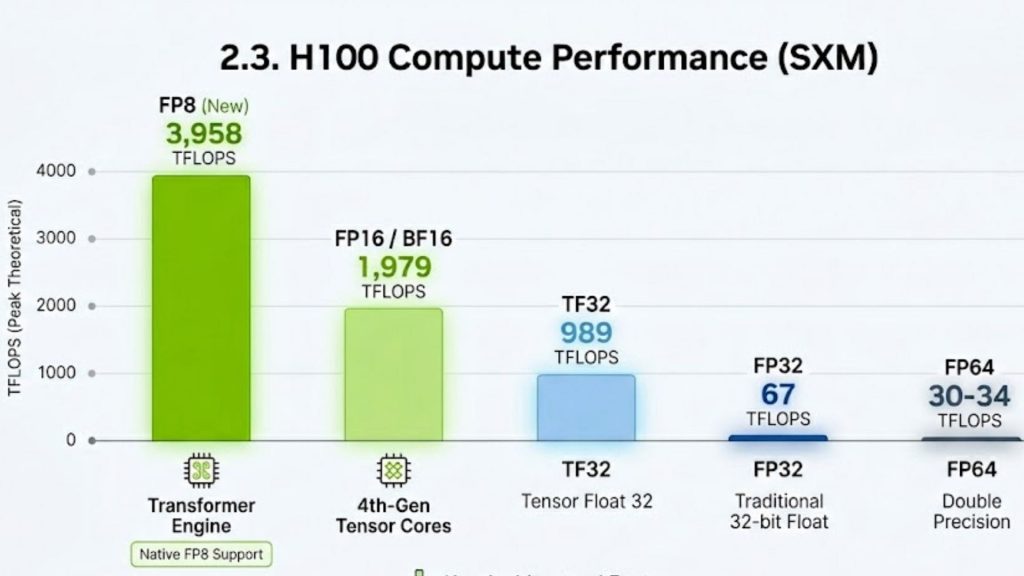
NVIDIA H100 GPU’s peak theoretical TFLOPS across various precision formats
2.4. Power and Thermal Design (TDP)
The H100 operates within a relatively high power envelope, with the SXM variant reaching up to 700W and the PCIe variant operating in the range of 350–400W, which reflects its positioning as a rack-scale compute accelerator rather than a traditional standalone GPU, where performance density and sustained utilization are prioritized over low-power operation.
| Variant | TDP |
| H100 SXM5 | Up to 700 W |
| H100 PCIe | 350 W (default) / up to 400 W |
| H100 NVL | Up to 400 W |
From a system engineering perspective, this TDP level is directly tied to the increased transistor density, expanded Tensor Core throughput, and higher memory subsystem activity, which means that the H100 is designed to operate in fully optimized datacenter environments with advanced cooling solutions and high-efficiency power delivery systems rather than general-purpose compute environments.
2.5. Interconnect Architecture (NVLink, NVSwitch, and Cluster Scaling)
The H100 is not designed to function as an isolated compute unit, but rather as a tightly integrated component of a multi-GPU and multi-node system architecture, where interconnect bandwidth becomes as critical as compute performance itself in determining overall system efficiency for distributed AI workloads.
With 4th-generation NVLink delivering up to 900 GB/s of bidirectional GPU-to-GPU bandwidth, the H100 enables direct peer-to-peer memory access between GPUs without CPU intervention, while NVSwitch further extends this capability into fully connected intra-node GPU fabrics that eliminate traditional PCIe bottlenecks in multi-GPU training setups.
| Variant | NVLink Bandwidth (bidirectional) |
| H100 SXM5 (with NVSwitch) | 900 GB/s |
| H100 PCIe / NVL (3x NVLink bridges) | 600 GB/s |
At the cluster level, integration with NDR InfiniBand enables high-speed, low-latency inter-node communication using RDMA-based data transfer mechanisms, which ensures that large-scale distributed training workloads such as trillion-parameter transformer models can scale efficiently across hundreds or even thousands of GPUs with reduced synchronization overhead.
3. NVIDIA H100 performance in real-world AI workloads
The NVIDIA H100 demonstrates its true capability not only through theoretical throughput metrics but through how consistently it sustains performance across real-world AI workloads, where bottlenecks dynamically shift between compute, memory bandwidth, and interconnect communication depending on model size, batch configuration, and distributed system architecture.
3.1. LLM Training (GPT-Scale Models)
In large-scale LLM training such as GPT-style dense transformers or MoE models with hundreds of billions to trillion parameters, the H100 significantly accelerates training by leveraging FP8 mixed-precision via the Transformer Engine while maintaining numerical stability across deep transformer layers.
From a system standpoint, these workloads are typically bottlenecked by matrix multiplications, attention computation, and multi-GPU gradient synchronization, and the H100 mitigates these limits through high-bandwidth HBM3 memory combined with NVLink intra-node communication and InfiniBand-based inter-node scaling.
Example: Training a GPT-175B-class model typically requires thousands of GPUs and weeks of compute time on A100-class infrastructure, but on H100-based clusters, the same training pipeline can achieve up to 4× faster convergence, meaning that a training run that previously took ~30 days can be reduced to roughly 7–10 days depending on parallelism strategy and batch scaling efficiency.
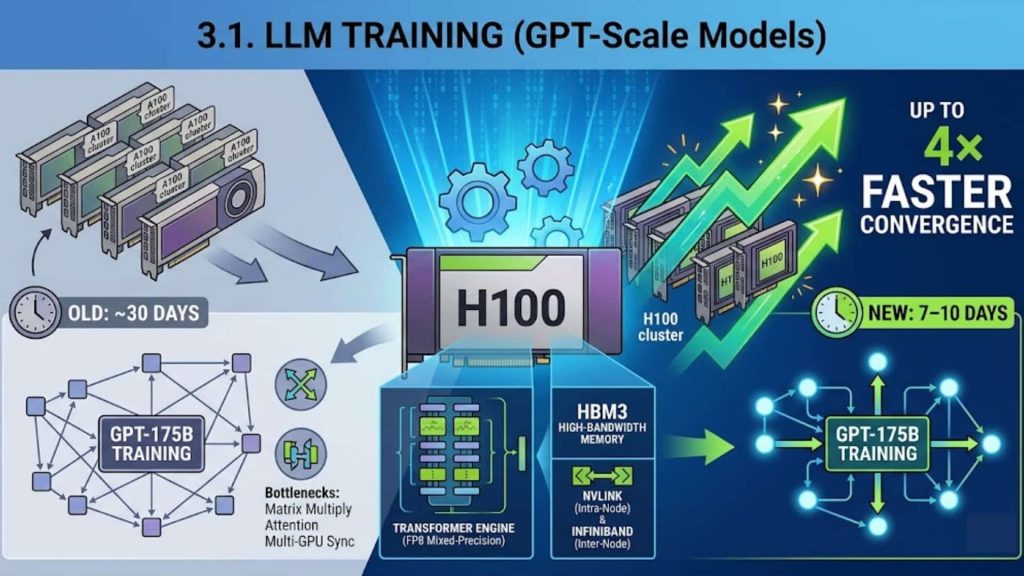
Training GPT-scale LLMs (e.g., GPT-3/4-class models) on NVIDIA H100 clusters can significantly accelerate training throughput
3.2. Fine-Tuning and Inference
In fine-tuning workloads such as SFT, RLHF, or parameter-efficient methods like LoRA and QLoRA, the H100 provides an optimized execution environment where smaller batch sizes and irregular computation patterns still achieve high utilization thanks to improved scheduling efficiency and reduced memory access overhead.
In inference workloads, especially large-scale LLM deployments like chatbots, code generation systems, or RAG pipelines, the H100 leverages FP8 and INT8 execution paths to reduce latency while maintaining high throughput under heavy concurrent request traffic.
Example: A 70B parameter model such as Llama-class architectures deployed for real-time conversational AI can achieve up to 5× higher throughput per GPU compared to A100 systems, meaning a single H100 GPU can handle significantly more concurrent users while maintaining sub-second response latency in optimized serving stacks.
Another practical example is high-concurrency API inference systems, where thousands of short prompts are processed simultaneously; in this scenario, the H100’s optimized memory reuse patterns and Tensor Core scheduling allow it to maintain stable latency even under burst traffic conditions, which is critical for production-grade AI services.
3.3. Scientific Simulation (HPC + AI Fusion)
In scientific computing workloads such as molecular dynamics, CFD, genome sequencing, and protein structure prediction, the H100 extends beyond traditional GPU acceleration by combining stronger FP64 performance with DPX instructions optimized for dynamic programming tasks used in bioinformatics and sequence alignment.
From an architectural perspective, these workloads typically involve irregular memory access patterns and compute-intensive iterative solvers, and they benefit not only from higher FP64 throughput but also from sustained high memory bandwidth and improved parallel efficiency across large-scale GPU clusters.
Example: In genome sequencing tasks using Smith-Waterman alignment algorithms, the H100 can achieve up to 40× speedup compared to CPU-based implementations, reducing processing time for large genomic datasets from hours to minutes in optimized HPC pipelines.
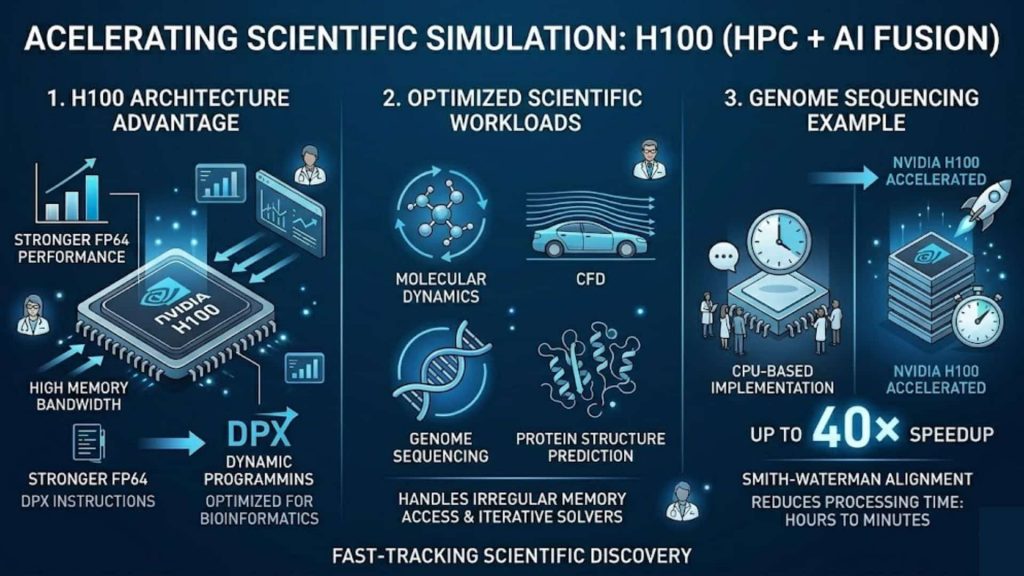
In scientific computing, the H100 accelerates workloads like genomics and CFD with FP64 and DPX support, delivering up to 40× speedup over CPUs.
4. NVIDIA H100 price: What does it cost?
The NVIDIA H100 is a high-end AI GPU designed for large-scale training and inference workloads. In practice, it is rarely purchased directly as hardware; instead, it is typically accessed through cloud platforms where pricing is based on actual usage time.
At FPT AI Factory, NVIDIA H100 SXM5 GPU Virtual Machines are available in multiple configurations:
- 1× H100 SXM5 (80GB HBM3): around $2.54/hour
- 2× H100 SXM5: around $5.08/hour
- 4× H100 SXM5: around $10.16/hour
- 8× H100 SXM5: around $20.32/hour
Each GPU VM also comes with dedicated CPU, RAM, and NVMe storage, making it a ready-to-use environment for AI workloads rather than just raw compute power.
What stands out in this model is that FPT AI Factory integrates NVIDIA H100 into a fully managed GPU VM system, allowing businesses to access H100-level performance without investing heavily in physical infrastructure. Instead of spending tens of thousands of dollars upfront on hardware, teams can simply rent compute capacity by the hour or scale it up to multiple GPUs depending on workload needs.
This makes the H100 much more accessible for AI startups and enterprises that need high performance for training or fine-tuning models, but want to keep data infrastructure costs flexible and usage-based.
FPT AI Factory also lowers the entry barrier for new users with a Starter Plan that provides $100 free credits for the first 30 days. These credits can be used across services such as GPU Container, GPU Virtual Machine, AI Notebook, and Serverless Inference & AI Studio, making it easier to test workloads before scaling. The platform further supports 20+ AI models, including Llama-3.3, for experimentation and deployment.

On the FPT AI Factory, NVIDIA H100 SXM5 GPU virtual machines are offered in a range of different configurations.
5. Frequently Asked Questions
5.1. Is the H100 good for LLM inference?
Yes, the NVIDIA H100 is highly optimized for LLM inference because its Transformer Engine with FP8 precision allows models to run faster with lower memory usage while still maintaining accuracy, which directly improves throughput and reduces latency in production-scale deployments.
5.2. Is the H100 the best GPU?
The NVIDIA H100 is currently one of the industry-standard GPUs for large-scale AI training, inference, and HPC workloads because it offers a balanced combination of compute power, memory bandwidth, and interconnect scalability that is specifically designed for transformer-based architectures and distributed AI systems.
5.3. Why is H100 so expensive?
The NVIDIA H100 is expensive in terms of hardware manufacturing cost due to its advanced architecture, HBM3 memory, and complex interconnect design, but in real-world AI workloads it is often not considered expensive when evaluated based on performance per dollar, because it significantly reduces training time and inference cost at scale.
In conclusion, the NVIDIA H100 is a high-performance AI GPU built for large-scale transformer workloads. It improves efficiency in distributed systems by reducing training time and communication bottlenecks, and its availability via platforms like FPT AI Factory makes enterprise-grade AI infrastructure more accessible on a pay-as-you-go basis.
New users with a Starter Plan that provides $100 free credits when logging in. For enterprises or organizations that require custom configurations or large-scale deployments, FPT AI Factory also provides a dedicated contact form for consultation. Through this channel, businesses can receive support on infrastructure design, optimization, and workload-specific deployment strategies.
Contact information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more article:


