
AI infrastructure costs are becoming a critical consideration for enterprises building large-scale AI, machine learning, and generative AI applications. As NVIDIA H100 GPUs continue powering advanced AI workloads, businesses increasingly need to evaluate both performance and long-term infrastructure efficiency. In this article, FPT AI Factory helps you understand H100 cost, pricing factors, cloud rental models, workload-based cost estimation, and smart infrastructure choices for modern AI environments.
1. How Much Does an H100 Cost?
H100 cost varies depending on whether organizations buy NVIDIA H100 GPUs directly or rent cloud GPU infrastructure on demand. Buying usually requires an upfront investment of around $25,000 – $40,000+ per GPU, plus infrastructure costs for cooling, networking, storage, and power systems that can add 20 – 40% extra cost. Cloud rental offers flexible access at about $2 – $8 per GPU/hour without owning hardware.
Final pricing depends on GPU type, provider, region, availability, contract terms, and pricing models such as on-demand, reserved (often 20 – 60% cheaper), or spot instances (up to 40 – 70% discount). For large AI workloads, enterprises estimate cost based on total GPU-hours ranging from tens to thousands per project, rather than only hourly pricing.
2. H100 Purchase Cost vs Cloud Rental Cost
Organizations evaluating H100 infrastructure often compare the long-term economics of purchasing GPUs versus renting cloud-based GPU instances. Here is a table comparing the differences between H100 purchase and cloud rental models.
| Criteria | H100 Purchase | H100 Cloud Rental |
| Upfront cost | $25K – $40K+ per GPU (DeployBase, 2025) | Low upfront cost |
| Hourly/monthly cost | Lower over long-term utilization | $2 – $8 per GPU/hour (Carolyne, 2026) |
| Infrastructure setup | Requires datacenter, cooling, networking (adds 20 – 40% cost overhead) (Compute, 2026) | Managed by cloud provider |
| Maintenance responsibility | Internal IT teams | Provider-managed |
| Scalability | Limited by hardware capacity | Elastic (1 – 10x scaling) |
| Availability | Procurement-dependent | Instant access |
| Best use case | Stable long-term workloads | Dynamic / experimental workloads |
| Example | Enterprise AI cluster | Cloud training platform |
Organizations with predictable long-term AI demand may benefit from purchasing H100 infrastructure due to higher utilization efficiency over time. However, cloud-based H100 rentals provide greater flexibility for fluctuating workloads, experimentation, and rapid scaling across distributed AI environments.
3. H100 Cloud Pricing: What Affects the Hourly Rate?
Several infrastructure and deployment factors directly influence H100 cloud pricing across enterprise AI environments. Here are some important factors affecting H100 hourly costs.
3.1. Cloud provider and region
Cloud providers use different pricing structures depending on infrastructure availability, regional datacenter capacity, operational expenses, and local demand. GPU pricing in North America may differ substantially from pricing in Asia-Pacific or Europe because electricity costs, supply constraints, and infrastructure maturity vary by region. Large cloud providers also adjust H100 pricing based on reserved capacity agreements and enterprise contracts. As global AI demand continues growing, regional GPU shortages may temporarily increase hourly rental rates.
Global cloud regions offering enterprise H100 GPU infrastructure services
3.2. H100 PCIe vs H100 SXM
H100 PCIe and H100 SXM GPUs have different performance capabilities and deployment requirements. H100 SXM models generally provide higher bandwidth and better scaling efficiency because they support advanced interconnect technologies such as NVLink and HGX architectures. Consequently, SXM-based instances usually cost more than PCIe deployments. Enterprises training large language models or multi-node AI systems often prefer SXM infrastructure for improved distributed training performance.
3.3. On-demand, reserved, and spot pricing
Cloud providers typically offer multiple pricing models for H100 infrastructure depending on workload flexibility and commitment duration. On-demand pricing provides maximum flexibility but usually has the highest hourly rates. Reserved instances lower long-term costs by requiring contractual commitments, while spot pricing offers discounted rates using excess infrastructure capacity. However, spot instances may be interrupted when demand increases, making them less suitable for critical production workloads.
3.4. Single GPU vs multi-GPU instances
Multi-GPU instances often improve training efficiency for large AI workloads but also increase infrastructure complexity and total operational costs. Distributed workloads require additional networking bandwidth, synchronization overhead, and orchestration management. For example, large language model training may require clusters containing eight or more H100 GPUs operating simultaneously. This works because distributed training significantly accelerates computation across massive AI datasets.
3.5. Networking, storage, and data transfer costs
GPU pricing alone does not include storage consumption, network traffic, or data transfer charges. Large AI workloads frequently move massive datasets between cloud regions, storage layers, and inference pipelines. As a result, networking and storage costs may become substantial during long-term training operations or production inference deployments. Enterprises should evaluate the complete infrastructure stack when estimating total AI project expenses.

AI cloud infrastructure showing networking, storage, and data transfer cost layers
3.6. Multi-node networking and cluster scaling
Large AI models increasingly require multi-node GPU clusters connected through ultra-low-latency networking technologies. Multi-node scaling improves AI training performance but introduces additional costs related to synchronization, orchestration, and distributed networking infrastructure. Enterprises building large-scale generative AI systems often rely on specialized networking architectures to maintain training efficiency. Consequently, networking optimization becomes a critical component of enterprise AI cost management.
4. Hidden Costs Beyond the GPU Price
H100 infrastructure expenses extend beyond the GPU hardware or hourly rental price alone. Here are some hidden costs organizations should consider when planning enterprise AI infrastructure deployments.
4.1. Power and Cooling
H100 GPU clusters consume large amounts of electricity during AI training and inference workloads. Organizations often need advanced cooling systems and upgraded power infrastructure to maintain stable GPU performance.
For example, enterprises deploying multiple H100 GPUs may need liquid cooling systems and higher-capacity power distribution to support continuous AI operations.
4.2. Networking Infrastructure
Large-scale AI workloads require high-speed networking technologies such as InfiniBand and NVLink for efficient GPU-to-GPU communication. These networking systems can significantly increase infrastructure deployment costs.
For instance, AI clusters running distributed model training may require low-latency networking hardware to synchronize workloads efficiently across multiple GPU servers.

High-speed networking infrastructure supports distributed AI workloads across GPU clusters
4.3. Engineering and DevOps Effort
Managing GPU infrastructure requires skilled engineering teams to handle orchestration, monitoring, scaling, security, and workload optimization across AI environments. Operational management can become costly over time.
For example, enterprises running large AI platforms may require dedicated DevOps engineers to continuously monitor GPU performance and optimize infrastructure utilization.
4.4. Underutilized GPU Capacity
Idle or partially used GPUs can reduce cost efficiency across AI infrastructure environments. Poor workload scheduling and overprovisioned GPU resources often increase operational expenses unnecessarily.
For instance, organizations reserving GPU servers for occasional AI workloads may experience low utilization rates while still paying full infrastructure costs.

Underutilized GPU infrastructure can significantly reduce AI cost efficiency
4.5. Monitoring and Operations
AI infrastructure environments require continuous monitoring, logging, security management, and workload analytics to maintain stable and reliable operations. Monitoring systems also help improve resource efficiency.
For example, enterprises operating GPU clusters often use centralized monitoring platforms to track GPU health, workload performance, and infrastructure stability in real time.
5. H100 Cost by Workload Type
Different AI workloads consume GPU resources differently even when the hourly H100 rate remains unchanged. The following examples illustrate how workload characteristics may affect overall AI infrastructure costs.
5.1. H100 Cost for Training foundation models
Training foundation models is the most GPU-intensive workload, often requiring multiple H100 GPUs running continuously for extended periods. Costs are primarily driven by GPU-hours, along with storage and networking resources.
In these situations, GPU Virtual Machine helps organizations access scalable H100 infrastructure for large-scale AI training without investing in dedicated hardware. With $2.54 an hour, businesses can rent a GPU H100 with advanced specifications like 192GB RAM, 16 cores CPU, and 3TB Local Storage NVMe from FPT AI Factory.
5.2. H100 Cost for Fine-tuning Models
Fine-tuning typically requires fewer GPU resources than full model training. Costs depend on model size, dataset volume, and training duration, making it a more cost-efficient option for customizing pre-trained models.
Organizations often prioritize flexible GPU access to support iterative model improvements without maintaining dedicated infrastructure. GPU Virtual Machine provides scalable compute resources that allow teams to accelerate fine-tuning workloads while optimizing infrastructure costs and resource utilization.
5.3. H100 Cost for AI Inference
AI inference workloads focus on serving trained models in production. Total H100 costs depend on API request volume, latency requirements, and utilization efficiency, with always-on deployments potentially costing $2 – $8 per GPU/hour.
Many businesses running AI inference services face operational overhead from continuously managing GPU infrastructure, scaling resources, and maintaining availability. In these situations, Serverless Inference helps organizations deploy AI inference workloads more efficiently through managed serverless infrastructure while reducing operational complexity and improving scalability.
5.4. H100 Cost for Computer vision & HPC
Computer vision and high-performance computing (HPC) workloads often involve image processing, video analytics, scientific simulations, engineering applications, and large-scale data analysis. GPU requirements can vary significantly depending on workload complexity, data size, and processing frequency.
GPU Container from FPT AI Factory can help teams deploy and manage these GPU-intensive workloads more efficiently through containerized environments that simplify scaling and resource management.
6. H100 vs A100 vs H200: Cost and Performance Considerations
Enterprises evaluating AI infrastructure often compare different NVIDIA GPU generations based on cost, performance, efficiency, and workload suitability. Here is a table comparing H100, A100, and H200 GPUs.
| Criteria | A100 | H100 | H200 |
| GPU generation | Ampere | Hopper | Hopper Next |
| Performance level | High | Very high (2 – 4x faster than A100) | Extremely high (~1.2 – 1.5x faster than H100) |
| Memory capacity | Up to 80GB | Up to 80GB HBM3 | Up to 141GB-class HBM3e |
| Typical cost range | Lower (~$1 – $3/hour cloud) | Higher (~$2 – $8/hour) | Highest (~$4 – $12/hour) |
| Availability | Broad availability | Limited but growing | Emerging availability |
| Power efficiency | Good | Improved (~20 – 30% better than A100) | Advanced |
| Training efficiency | Strong | Excellent (30 – 50% faster training) | Exceptional |
| Inference efficiency | Strong | Excellent | Very high |
| Best workload fit | Traditional AI training | Generative AI and LLMs | Massive AI models |
| Cost-efficiency consideration | Lower upfront cost | Better performance scaling | Premium high-end deployment |
| When to choose | Budget-sensitive AI projects | Enterprise generative AI | Cutting-edge AI scaling |
A100 GPUs remain cost-effective for many enterprise AI workloads requiring stable large-scale compute. However, H100 and H200 platforms deliver stronger performance efficiency, with up to 2–4x speed improvement, for modern generative AI and transformer models. This performance gain can reduce total training time by 30–60%, which may lower overall operational costs despite higher hourly pricing.
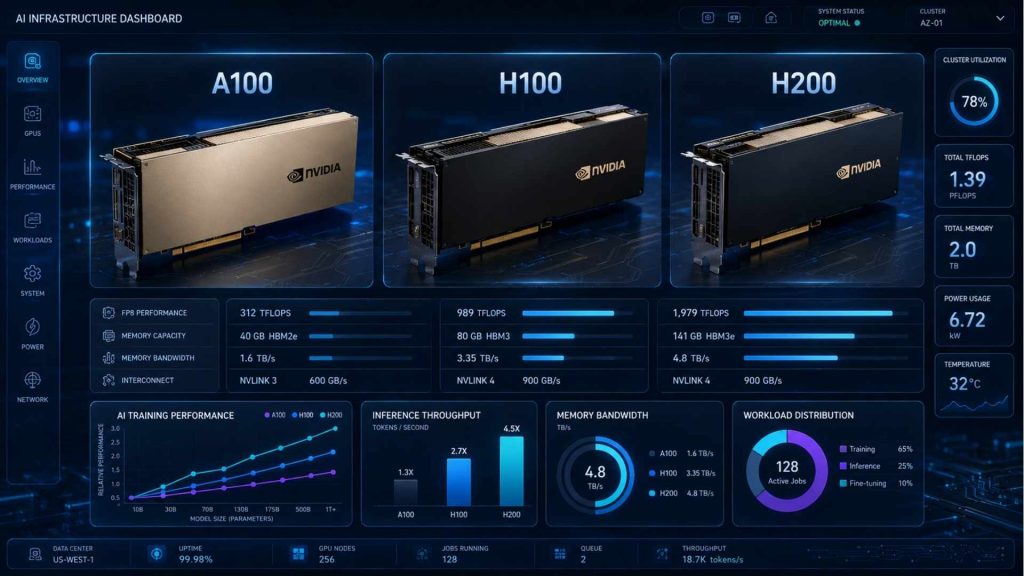
Comparison between NVIDIA A100, H100, and H200 AI infrastructure platforms
7. How to Estimate Your H100 Total Cost
Accurately estimating H100 infrastructure expenses requires evaluating both direct GPU pricing and broader operational costs across the AI lifecycle. Here are some important steps organizations should follow when calculating total AI infrastructure cost.
- Estimate required GPU-hours: Organizations should calculate expected GPU runtime across training, fine-tuning, inference, and experimentation workloads. Total GPU-hours often provide a more realistic cost estimate than hourly pricing alone.
- Choose GPU type and instance size: Different workloads may require H100 PCIe, SXM, or multi-GPU cluster configurations. Selecting oversized infrastructure can unnecessarily increase operational expenses.
- Compare on-demand, reserved, and spot pricing: Pricing models significantly affect long-term infrastructure economics. Reserved and spot pricing may reduce costs when workloads are predictable or fault-tolerant.
- Add storage and data transfer costs: Large AI workloads frequently generate significant storage and networking expenses. Enterprises should include these operational costs when evaluating total infrastructure budgets.
- Include engineering and monitoring effort: AI operations require orchestration, monitoring, security management, and infrastructure optimization expertise. Operational staffing costs can become substantial in large deployments.
- Calculate cost per training run or inference volume: Cost-per-output metrics often provide more useful business insights than raw infrastructure pricing. Organizations can better optimize efficiency by measuring training and inference economics directly.
- Compare total project cost, not only hourly price: The cheapest hourly GPU rate may not produce the lowest total infrastructure expense. Efficient scaling, orchestration, and workload utilization often have a greater impact on long-term cost efficiency.
A comprehensive cost estimation strategy helps enterprises improve infrastructure planning and reduce operational inefficiencies across AI deployments. As AI workloads become more distributed and dynamic, accurate forecasting becomes increasingly important for maintaining scalable AI operations.

Enterprise AI infrastructure cost estimation dashboard analyzing GPU-hours and workload efficiency
8. Optimizing H100 Infrastructure Costs for Enterprises
Organizations deploying H100 infrastructure increasingly focus on workload efficiency and operational optimization to reduce long-term AI expenses. Here are some key strategies enterprises use to optimize H100 infrastructure costs.
- Improve GPU utilization: Higher utilization rates help reduce idle infrastructure expenses across AI environments. For training, fine-tuning, and experimentation workloads, enterprises can use FPT AI Factory GPU Virtual Machine from $6.99/hour.
- Use workload scheduling intelligently: Organizations can prioritize non-critical workloads during lower-cost pricing windows such as spot instance availability. This helps reduce unnecessary infrastructure spending.
- Adopt containerized AI environments: Containerized orchestration improves workload portability, dependency management, and scaling flexibility. Better workload isolation also increases operational efficiency.
- Optimize model architecture: Smaller or optimized AI models may reduce training and inference costs substantially. Efficient architectures often improve both performance and infrastructure economics.
- Monitor infrastructure continuously: Real-time analytics help organizations detect underutilized resources and operational bottlenecks. Monitoring also improves forecasting accuracy and cost governance.
- Use managed inference platforms when appropriate: For variable inference workloads, FPT AI Factory Serverless Inference helps teams integrate AI models via API without managing infrastructure, reducing operational overhead and lowering 5 times GPU costs than hyperscalers.
These optimization strategies help organizations improve scalability while maintaining operational efficiency across enterprise AI deployments. Long-term cost optimization increasingly depends on orchestration quality, workload efficiency, and infrastructure management maturity rather than hardware pricing alone.
9. FAQs
9.1. Is it cheaper to buy or rent H100 GPUs?
Buying H100 GPUs usually requires high upfront investment and infrastructure costs, while cloud rental offers more flexible pricing. Many businesses prefer renting for scalable or short-term AI workloads.
9.2. Is H100 better than A100 for cost efficiency?
H100 provides stronger AI training and inference performance than A100, but the total cost is also higher. Cost efficiency depends on workload scale, utilization rates, and AI infrastructure requirements.
9.3. How can businesses reduce H100 cloud costs?
Businesses can reduce H100 cloud costs by improving GPU utilization, using reserved or spot pricing, optimizing workloads, and scaling infrastructure more efficiently across AI environments.
In summary, H100 GPUs are important to support modern AI infrastructure, large-scale model training, inference workloads, and high-performance computing environments. However, total H100 cost depends on multiple factors, including infrastructure scale, GPU utilization, deployment architecture, and operational efficiency.
As AI adoption continues to grow, organizations need GPU infrastructure that can support demanding workloads while maintaining performance, scalability, and cost efficiency. For enterprises with customized AI requirements, large-scale deployments, or GPU-intensive workloads, FPT AI Factory provides enterprise-grade H100 infrastructure, technical consultation, detailed pricing, and tailored deployment solutions to support AI development and production at scale. Contact through the official contact form.
Contact Information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore Related Articles:
A100 vs H100: Which GPU is better for AI workloads?


