
As enterprise AI adoption continues to accelerate, organizations are increasingly evaluating whether RAG alone can deliver the level of accuracy, consistency, and domain-specific behavior required for production environments.
This blog presents a practical framework for determining when LLM fine-tuning should be applied, with a focus on real-world use cases, architectural trade-offs, and production considerations.
Key Differences Between RAG and Fine-tuning
LLM optimization strategies generally fall into three layers: prompt engineering, RAG, and fine-tuning. Each addresses a different dimension of model performance.
Prompt engineering improves how instructions are structured. RAG enhances responses by supplying external knowledge and contextual data at inference time. Fine-tuning, in contrast, adapts the model’s response behavior itself, enabling greater consistency, domain alignment, and output control.
In simple terms, RAG focuses on giving the model the right information, while fine-tuning focuses on shaping how the model responds to that information.
- RAG enriches responses with retrieved knowledge and supporting context.

2. Fine-tuning optimizes response behavior, including tone, structure, consistency, and domain-specific patterns.
What does fine-tuning actually do?
Fine-tuning is often misunderstood as a way to make models “memorize more knowledge.” In practice, its primary value lies in stabilizing response behavior and improving consistency in production environments. It is particularly effective for:
- Enforcing structured outputs such as JSON, templates, and workflow formats
- Standardizing evaluation criteria across audits, reviews, and compliance checks
- Maintaining consistent tone, style, and communication quality in customer-facing interactions
However, fine-tuning is not always the right starting point. When the core issue is missing or frequently changing information such as internal policies, FAQs, or enterprise documents, a RAG-based approach is typically more effective and easier to maintain. Fine-tuning also depends heavily on data quality, meaning poorly structured or noisy datasets often lead to unstable results rather than meaningful improvements.
A Practical Framework for Choosing Between RAG and Fine-tuning
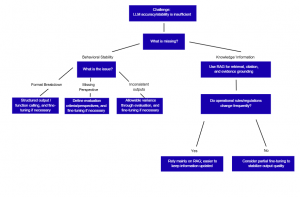
The most effective way to determine the right approach is to first identify the underlying source of the problem. The following framework maps common production issues to their likely causes and the most practical initial response strategy.
| Symptoms | Cause | Recommended Approach | Suitability for Fine-tuning |
| Unable to answer using up-to-date or internal knowledge | Lack of knowledge | RAG (retrieval, citation, and evidence-based grounding) | Low |
| Inconsistent responses across repeated prompts | Inconsistent output patterns | Evaluation → Root cause analysis (where does the variability occur?) | Moderate to high |
| Unstable structured outputs (JSON, CSV, templates) | Weak adherence to format constraint | Format enforcement / structured outputs / function calling | High |
| Missing evaluation criteria in audits or compliance workflows | Weak reasoning patterns | Explicit definition of evaluation criteria → evaluation → reinforcement | High |
| Inconsistent tone, politeness, or brand voice | Unstable style | Style constraints → apply fine-tuning if necessary | Moderate to high
|
| Frequent hallucinations | Insufficient grounding / leading bias | RAG + Enforced citation + refusal handling design | Low to moderate |
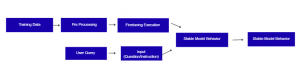
In practice, the following decision flow can serve as a useful starting point
High-impact Enterprise Use Cases for Fine-tuning
The following examples highlight practical enterprise scenarios where fine-tuning delivers significant value.
Use Case 1: Improving Reliability of Structured Outputs
- Challenge
Invalid JSON outputs, missing keys, and inconsistent data types causing downstream workflow instability.
- Approach
Apply structured output techniques such as function calling and, where necessary, fine-tuning to improve formatting consistency and output reliability.
- Objective
Ensure stable and predictable behavior in production workflows.
Use Case 2: Standardizing Evaluation and Review Quality
- Challenge
Inconsistent evaluation standards across audits, compliance reviews, and assessment workflows.
- Approach
Define explicit evaluation criteria, assess outputs against those standards, and apply fine-tuning to reinforce more consistent reasoning patterns.
- Objective
Improve consistency and standardization across review processes.
Use Case 3: Maintaining Consistent Customer Communication
- Challenge
Variability in tone, politeness, and brand voice across customer-facing interactions.
- Approach
Train on curated response datasets and apply fine-tuning to improve communication consistency and brand alignment.
- Objective
Maintain stable, high-quality customer communication at scale.
Fine-tuning for Large-scale Document Understanding
To illustrate how fine-tuning can deliver value in production environments, the following case study highlights a large-scale document understanding workflow built around Donut (Document Understanding Transformer) and a training dataset exceeding 300GB.
Background of the case
- Client profile: A company with globally distributed development teams (headquartered in Japan)
- Objective: To read, understand, and extract information from forms and document images with a level of accuracy suitable for real-world business operations
- Challenge: The training dataset exceeded 300GB, making the design of the training infrastructure and cost optimization critical factors
Challenges
In document understanding workflows, the primary challenge is not knowledge retrieval, but behavioral consistency in how information is extracted, structured, and interpreted from complex documents.
As a result, retrieval alone is often insufficient. The workload requires tighter control over output behavior, including extraction accuracy, formatting consistency, and error handling, making it well-suited for fine-tuning.
Solution approach
To support large-scale training efficiently, the architecture separates data storage from training execution environments.
- Object storage was used to manage the 300GB+ training dataset
- GPU container environments were used to execute distributed fine-tuning workloads
This architecture enabled a more scalable and cost-efficient training pipeline for production-scale document understanding.

Key takeaways
- As training data scales, the design of storage, data transfer, and execution infrastructure often becomes more critical than the training process itself.
- Document understanding workloads also place greater emphasis on behavioral optimization than knowledge expansion, making them particularly well-suited for fine-tuning. In production environments, extraction reliability, structural consistency, and error resilience frequently matter more than raw model capability alone.
What Makes Fine-tuning Difficult in Practice?
Fine-tuning is rarely just a matter of training a model and deploying it into production. In practice, the most challenging aspects often lie in data quality, evaluation design, iterative improvement workflows, and operational management. Key considerations typically include:
- Training data design, including edge cases, positive and negative examples, formatting consistency, and noise reduction
- Evaluation design, such as defining quality standards and ensuring reproducible assessment workflows
- Iterative improvement cycles involving failure analysis, dataset refinement, retraining, and re-evaluation
- Operational design, including monitoring, update frequency, RAG integration, and cost optimization
Without properly addressing these areas, systems that perform well during PoC frequently encounter reliability and scalability issues in production environments. In many cases, incorporating “ideal responses” into supervised QA-style datasets also leads to more stable and better-aligned model behavior.
Simplifying AI Development with FPT AI Factory
With FPT AI Factory, key fine-tuning workflows can be performed through a fully no-code experience, including:
- Training data creation
- Model fine-tuning
- Model evaluation and testing
In conventional environments, fine-tuning typically requires users to prepare development environments on local PCs or virtual machines, configure dependencies, and write scripts in languages such as Python to execute training workflows.
FPT AI Factory simplifies this process by providing an integrated platform where even users without programming expertise can perform fine-tuning, evaluate model performance, and validate outputs through an intuitive no-code interface. This significantly lowers the operational barrier for organizations looking to accelerate AI adoption and experimentation.
Service Overview
FPT AI Factory is a GPU-native AI platform designed to accelerate the entire AI development lifecycle, from model training and fine-tuning to inference and deployment.
Built for enterprise-scale AI workloads, the platform provides immediate access to high-performance GPU infrastructure along with integrated AI development tools, enabling organizations to develop, optimize, and scale AI applications more efficiently.
- Japan Region: https://ai.fptcloud.jp/
- Vietnam Region: https://ai.fptcloud.com/
Free Trial Program
As of February 13, 2026, new users are eligible to receive USD 100 in promotional credits, enabling up to 30 days of hands-on access to FPT AI Factory at no cost. This program is designed to help developers and enterprises quickly evaluate GPU infrastructure, fine-tuning workflows, and AI deployment capabilities in a production-ready environment.
Summary
RAG is primarily designed to enhance information retrieval by supplying models with relevant external knowledge at inference time. Fine-tuning, by contrast, is intended to optimize model behavior, improving response consistency, domain adaptation, formatting control, and output reliability across specific tasks.
When evaluating whether RAG or fine-tuning is the right approach, the most effective methodology is to diagnose prolems systematically in the following order:
- Symptom → 2. Root Cause → 3. Solution
Rather than applying fine-tuning by default, organizations should first identify whether the issue originates from insufficient knowledge retrieval, response behavior, data quality, or operational design. This approach enables more efficient AI system design while reducing unnecessary complexity and cost.


