
Building a machine learning model is only the beginning, running it reliably in production is the real challenge. So, what is MLOps? MLOps (Machine Learning Operations) bridges this gap by standardizing how models are developed, deployed, and continuously improved. In this guide, FPT AI Factory will explore the MLOps lifecycle, key principles, and benefits, along with practical ways to accelerate workflows using solutions like AI Studio’s Model Testing service for training, experimentation, and deployment.
1. What is MLOps?
MLOps (Machine Learning Operations) is a set of practices that turns machine learning from experimentation into a reliable production system. It unifies model development, deployment, and operations into a continuous, automated, and governed lifecycle.
Unlike traditional software, ML systems are data-dependent and non-deterministic. This means performance can degrade over time as data changes. MLOps addresses this by treating data, models, and pipelines as versioned, testable, and deployable assets, similar to code in DevOps but with added complexity.
At its core, MLOps enables:
- End-to-end automation (data → training → deployment → retraining)
- Reproducibility across experiments and environments
- Continuous monitoring for drift, performance, and reliability
- Tight integration with CI/CD, extended to include data and models (CI/CD/CT)
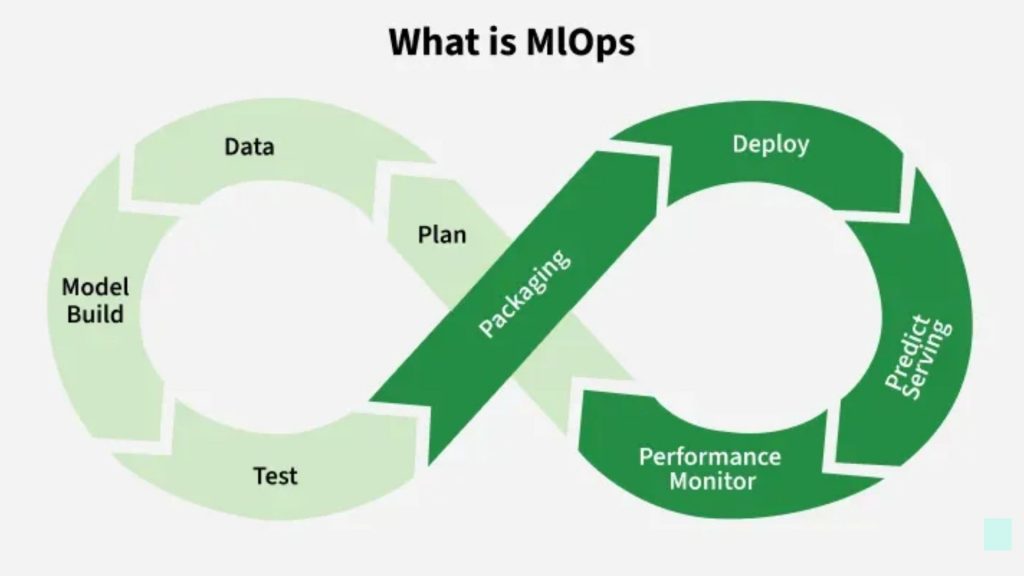
MLOps unifies data, model development, deployment, and monitoring into an automated, continuous production lifecycle for reliable ML systems.
2. How does ML relate to MLOps?
Machine Learning (ML) and MLOps are two parts of the same pipeline but with different responsibilities. ML focuses on building models—training, tuning, and optimizing performance, while MLOps focuses on deploying, running, and maintaining those models in production.
ML typically stops at a trained model, but real-world systems require more: deployment, monitoring, retraining, and version control. MLOps extends ML into a full lifecycle by automating these steps and ensuring models stay accurate as data changes.
The key difference is perspective. ML is model-centric (accuracy, algorithms), while MLOps is system-centric (pipelines, infrastructure, monitoring). Together, they turn isolated experiments into scalable, production-ready ML systems.
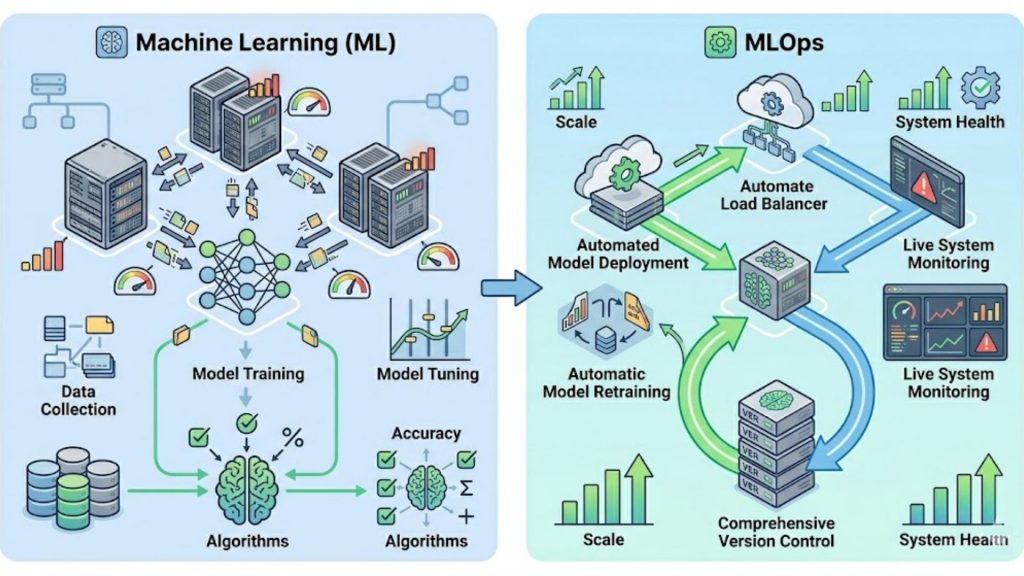
MLOps and Machine Learning has different process and fuctions
3. Benefits of MLOps
MLOps is not just about automation, it fundamentally changes how ML systems are built, deployed, and scaled. For teams already familiar with ML, the real value lies in reducing operational friction, improving reliability, and enabling continuous learning systems.
3.1. Increase Efficiency
MLOps eliminates repetitive, manual steps across the ML lifecycle by standardizing pipelines and environments. Instead of rebuilding workflows for each experiment, teams can reuse modular components (data pipelines, training scripts, deployment configs).
This leads to:
- Less time spent on environment setup and debugging
- Faster experiment iteration cycles
- Reduced dependency on individual contributors
Example: A team running ~50 experiments/week without MLOps may spend 30–40% of time on setup and coordination. With automated pipelines and experiment tracking, this overhead can drop below 10%, allowing more focus on model improvement rather than infrastructure.
3.2. Improve Model Accuracy and Performance
In production, model performance degrades due to data drift, concept drift, and changing user behavior. MLOps introduces continuous monitoring and retraining pipelines to address this.
This enables:
- Early detection of accuracy drops (e.g., via real-time metrics)
- Automated retraining triggered by data changes
- Consistent evaluation across model versions
Example: A recommendation system with no retraining may lose 10–20% CTR over a few months due to shifting user preferences. With MLOps, retraining pipelines can run daily or weekly, maintaining stable performance and even improving metrics over time.
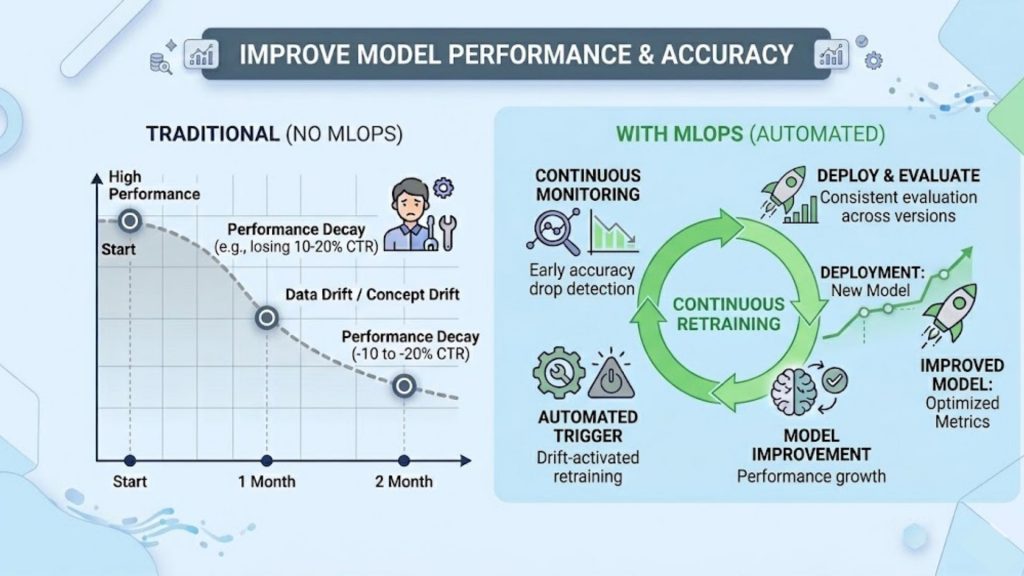
MLOps helps improve model accuracy and performance by enabling continuous training, monitoring, and optimization throughout the model lifecycle.
3.3. Faster Time to Market
MLOps integrates CI/CD practices into ML workflows (often extended to CI/CD/CT), enabling rapid transition from experimentation to deployment.
This results in:
- Shorter release cycles (from weeks → days or hours)
- Automated validation and testing before deployment
- Faster iteration on new models and features
Example: Without MLOps, deploying a model might take 2–4 weeks due to manual testing and integration. With automated pipelines, the same process can be reduced to a few hours, allowing teams to quickly respond to business needs (e.g., launching a new pricing model).
3.4. Scalability and Governance
As the number of models grows, managing them manually becomes infeasible. MLOps introduces centralized control through model registries, versioning systems, and governance frameworks.
This enables:
- Managing hundreds or thousands of models simultaneously
- Full traceability (data → model → deployment)
- Compliance with regulatory and security requirements
Example: A fintech company running 100+ risk models needs to track which dataset and parameters were used for each decision. With MLOps, every model version is logged and auditable, making it possible to explain decisions and meet regulatory audits without manual reconstruction.
4. The MLOps Lifecycle: End-to-End
A modern Machine Learning system is not just about building a good model, it’s about managing the entire lifecycle from raw data to continuous improvement in production. This is where the MLOps lifecycle comes in.
Instead of a one-time pipeline, MLOps operates as a continuous feedback loop, where each stage feeds into the next and evolves over time. The lifecycle can be divided into four interconnected cycles: Data, Model, Development, and Operations.
4.1. Data Cycle
The Data Cycle is the starting point of every ML system. No matter how advanced your algorithm is, poor-quality data will always lead to poor results.
This cycle begins with data ingestion, where data is collected from multiple sources such as databases, APIs, user interactions, logs, or IoT devices. Once collected, the data must go through validation and cleaning to remove duplicates, handle missing values, and ensure consistency in schema and format.
After cleaning, the next step is data transformation and feature engineering. This is where raw data is converted into meaningful features that a model can learn from. These features are often stored in a feature store, allowing teams to reuse them across training and production environments.
One of the biggest challenges in this cycle is data drift, where the statistical properties of data change over time. If not monitored, this can silently degrade model performance in production.
To manage this effectively, organizations should implement:
- Data versioning to track changes over time
- Data lineage to understand where data comes from
- Automated data pipelines to ensure consistency and scalability
A key insight here is that in real-world systems, data quality matters more than model complexity. Strong data practices often deliver more impact than experimenting with new algorithms.
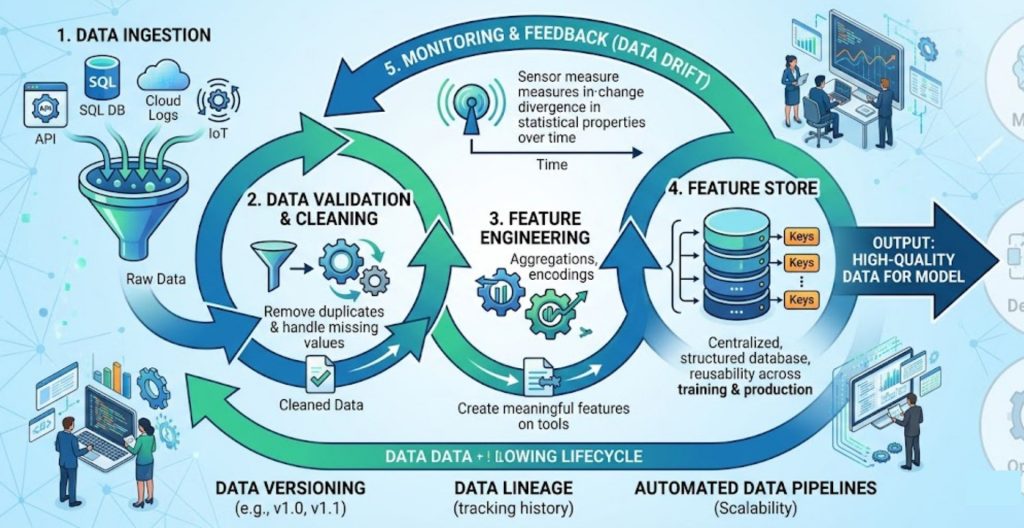
The data cycle establishes a reliable foundation for machine learning by ensuring data quality, consistency, and adaptability.
4.2. Model Cycle
The Model Cycle focuses on building, evaluating, and managing machine learning models. This is where the “intelligence” of the system is created.
The process typically starts with model selection, where data scientists choose the appropriate algorithm based on the problem, ranging from traditional models like regression or tree-based methods to deep learning or large language models.
Next comes training, where the model learns patterns from the prepared data. After training, the model is evaluated using various metrics such as accuracy, precision, recall, or F1-score, depending on the use case.
To improve performance, teams often perform hyperparameter tuning, experimenting with different configurations to find the optimal setup. Each experiment should be tracked carefully to ensure reproducibility.
For large language models, parameter-efficient methods such as LoRA (Low-Rank Adaptation) and QLoRA are widely used to reduce training costs while maintaining performance. These techniques enable fine-tuning large models without updating all parameters, making them efficient for large-scale training and deployment workflows in MLOps systems.
Managing multiple versions of models is also critical. This is usually handled through a model registry, where models are stored along with their metadata, metrics, and version history.
In practice, platforms like AI Studio Model Testing of FPT AI Factory can significantly simplify this cycle. They allow individuals and businesses to:
- Train models directly on cloud infrastructure
- Run multiple experiments efficiently
- Compare model performance across different datasets
- Reduce the need for complex local setups
The biggest challenge in this cycle is maintaining consistency and reproducibility, especially when experiments grow in scale. This is why automation and tracking are essential.
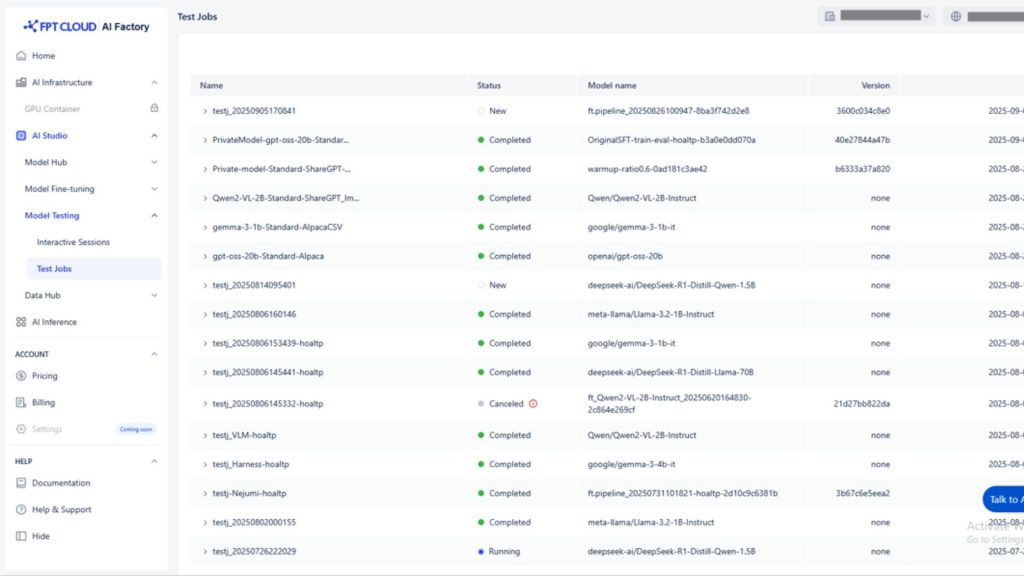
AI Studio Model Testing interface showing experiment tracking and job management (Source: FPT AI Factory)
4.3. Development Cycle
The Development Cycle is where collaboration happens between data scientists, machine learning engineers, and software developers. It ensures that models are not only accurate but also production-ready.
This cycle includes code versioning, typically using Git, so that every change in the codebase is tracked. It also involves experiment tracking, where each training run is logged with its parameters, datasets, and results.
Unlike traditional software development, testing in ML systems goes beyond code. It includes:
- Data validation tests
- Model performance tests
- Integration tests across pipelines
This is where model testing becomes especially important. A model with high accuracy in a controlled environment may fail in real-world scenarios due to bias, instability, or unseen data patterns.
Tools like Model Testing from FPT AI Factory provide a structured way to evaluate models before deployment. They help teams:
- Test models against diverse datasets
- Detect issues such as bias or performance degradation
- Validate robustness under different conditions
Another critical aspect of this cycle is building CI/CD pipelines for ML, which automate testing, integration, and deployment processes. This ensures that updates to data, code, or models can be delivered quickly and reliably.
What makes this cycle unique is that it combines principles from both DevOps and Data Science, requiring a balance between experimentation and engineering discipline.
4.4. Operations Cycle
The Operations Cycle is where machine learning models are deployed and start generating real business value. However, deployment is not the end, it’s just the beginning of continuous monitoring and improvement.
Once a model is deployed (typically as an API or batch process), it must be continuously monitored. This includes tracking:
- Model performance over time
- Changes in input data (data drift)
- Changes in relationships between inputs and outputs (concept drift)
Monitoring should also extend to business-level metrics, ensuring that the model is actually delivering value, not just performing well technically.
If performance drops, the system should trigger retraining pipelines, sending the process back to the Model Cycle. This creates a continuous feedback loop that keeps the model up to date.
Other important practices in this cycle include:
- Logging and observability for debugging and analysis
- Alerting systems to detect anomalies early
- Scalable infrastructure to handle production workloads
- Safe deployment strategies such as A/B testing or canary releases
The goal of the Operations Cycle is not just stability, but adaptability ensuring that the system evolves as data and business needs change.
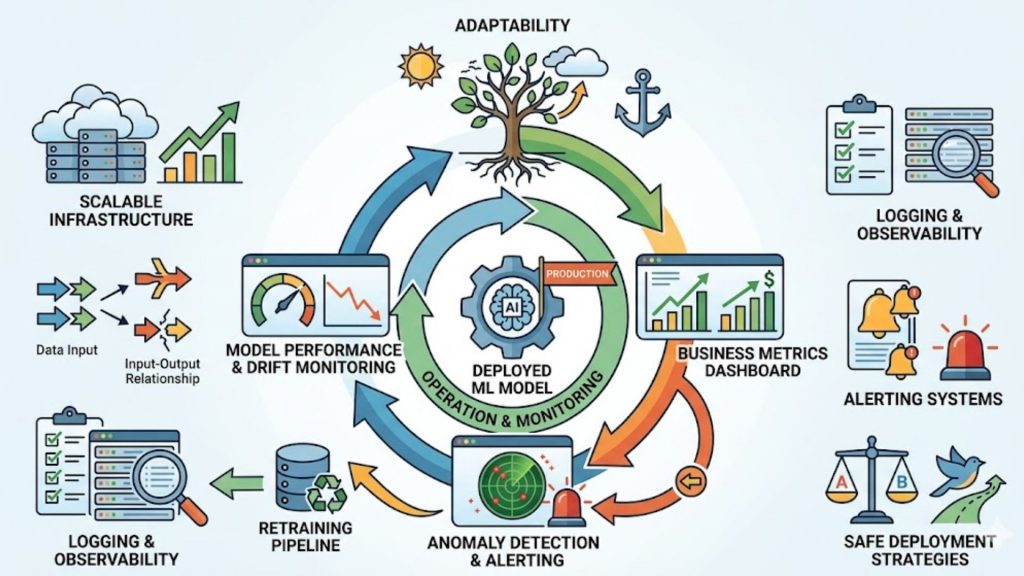
The operations cycle in production, showing continuous monitoring, feedback, and improvement to maintain performance and business value.
>> Explore more: The Importance of Cloud Computing in DevOps: Detailed Guide
>> Explore more: What Is GPU Computing and How Does It Work? A Complete Guide
5. Key Principles of an MLOps Strategy
To implement MLOps effectively at scale, organizations need more than just tools, they need a clear set of principles to guide how teams build, deploy, and maintain machine learning systems.
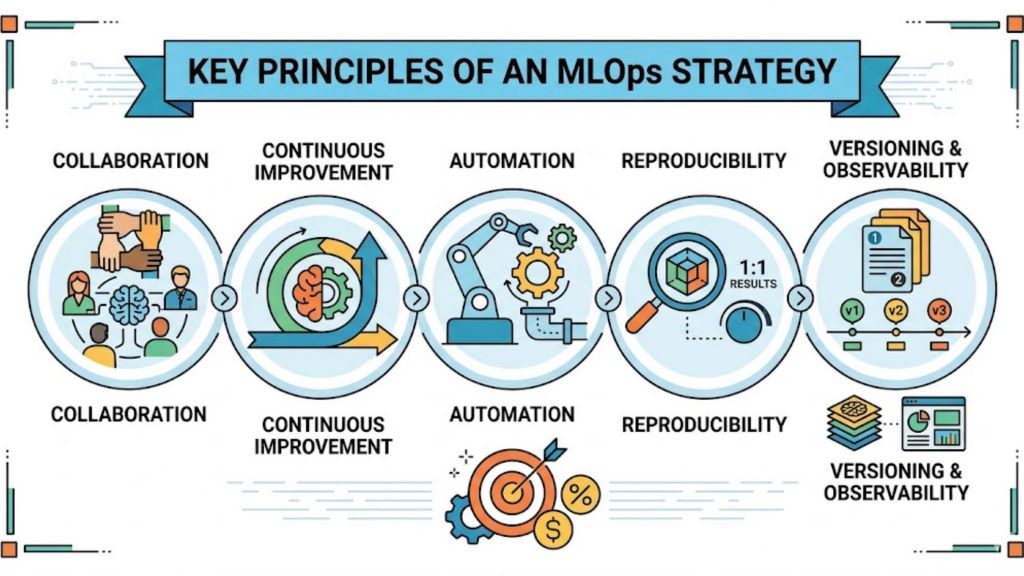
- Collaboration is the foundation, ensuring data scientists, ML engineers, developers, and business teams work closely together so models are aligned with real-world needs instead of being developed in isolation.
- Continuous improvement is essential because models naturally degrade as data and user behavior change. Instead of being “finished” after deployment, models must be regularly retrained and refined based on new data and feedback.
- Automation makes this process scalable by reducing manual work in data processing, training, testing, and deployment. It also improves speed, consistency, and reliability across different environments.
- Reproducibility ensures that experiments can be repeated with the same results by tracking data, code, parameters, and environments. This is important for debugging issues and validating model performance.
- Versioning helps manage changes across datasets, features, models, and pipelines. It allows teams to compare different versions, understand performance shifts, and safely roll back when needed.
- Monitoring and observability ensure models stay reliable in production by tracking performance, detecting data drift, and identifying issues early so teams can respond quickly.
In short, these principles “collaboration, continuous improvement, automation, reproducibility, versioning, and monitoring” work together to turn machine learning from an experimental process into a reliable, scalable system that continuously delivers value.
Key principles help ensure that MLOps workflows are consistent, scalable, and able to deliver long-term business value.
6. Frequently Asked Questions
6.1. Is MLOps the same as DataOps?
No, MLOps and DataOps are not the same, although they are closely related. DataOps focuses on managing and improving data pipelines, ensuring data is clean, reliable, and available for use, while MLOps covers the entire machine learning lifecycle, including data, model training, deployment, and monitoring. In simple terms, DataOps handles the data layer, and MLOps builds on top of it to deliver end-to-end ML systems.
6.2. Do I need a dedicated MLOps engineer?
You don’t always need a dedicated MLOps engineer at the beginning, especially for small projects where data scientists or developers can manage basic workflows. However, as your system grows in complexity, with multiple models, frequent updates, and production requirements, a dedicated role becomes important to handle automation, deployment, monitoring, and scalability. Tools like FPT AI Studio Model Testing can help reduce this burden early on by simplifying training and testing without heavy infrastructure.
6.3. What’s the difference between MLOps and ModelOps?
MLOps and ModelOps differ mainly in scope. MLOps covers the full lifecycle of machine learning systems, from data preparation to deployment and continuous improvement, while ModelOps focuses specifically on managing models in production, ensuring they perform well, remain compliant, and deliver business value. In many cases, ModelOps is considered a subset of MLOps with a stronger emphasis on governance and operational performance after deployment.
MLOps is not just about deploying models, it’s about building a continuous, reliable system where data, models, and operations work together seamlessly. The real advantage doesn’t come from having the most complex model, but from how well you can run, monitor, and improve it over time.
By adopting MLOps, organizations move faster, scale confidently, and turn AI into real business impact, not just experiments. To get started or optimize your MLOps journey, solutions like AI Studio Model Testing can help you train, test, and deploy models more efficiently without heavy infrastructure. New users receive $100 in free credits under the Starter Plan, available immediately upon login with no upfront cost. Contact FPT AI Factory to explore how MLOps can accelerate specific business AI strategies.
Contact information
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more articles:
Transfer Learning vs. Fine-Tuning: A Comprehensive Guide
What is JupyterHub? Characteristic and practical application


