
Pre-trained models are transforming the way businesses build and deploy AI – offering a powerful shortcut to high-performance machine learning without starting from scratch. Understanding how pre-trained models work helps organizations reduce development time, cut costs, and achieve superior results. At FPT AI Factory, we provide cutting-edge AI infrastructure and solutions that empower businesses to harness the full potential of pre-trained models within their AI development workflows.
| Key Takeaway
A pre-trained model is an AI model that has already learned patterns from large datasets and can be reused for related tasks. Instead of building a model from scratch, teams can use it directly, fine-tune it with domain-specific data, or deploy it for inference. This helps reduce training time, lower data and compute requirements, and accelerate AI development across NLP, computer vision, multimodal AI, and enterprise applications. |
1. What is a pre-trained model?
A pre-trained model is an AI model that has already been trained on a large dataset before being used or adapted for a specific task. Instead of learning from zero, it starts with knowledge captured during its initial training process. Examples of common pre-trained models include:
- BERT: Widely used for NLP tasks such as text classification, search, and question answering.
- GPT: Commonly used for content generation, chatbots, summarization, and coding assistance.
- T5: Designed for text-to-text tasks such as translation, summarization, and rewriting.
- ResNet: Frequently used for image classification and computer vision applications.
- YOLO: Optimized for real-time object detection in applications such as manufacturing inspection and autonomous systems.
- CLIP: Supports multimodal understanding by connecting text and image representations.
Pre-trained models can be used directly for general tasks such as text classification, summarization, translation, question answering, image classification, or object detection. They can also be fine-tuned with domain-specific data to improve performance for specialized use cases such as customer support, healthcare, legal analysis, coding, or enterprise copilots.
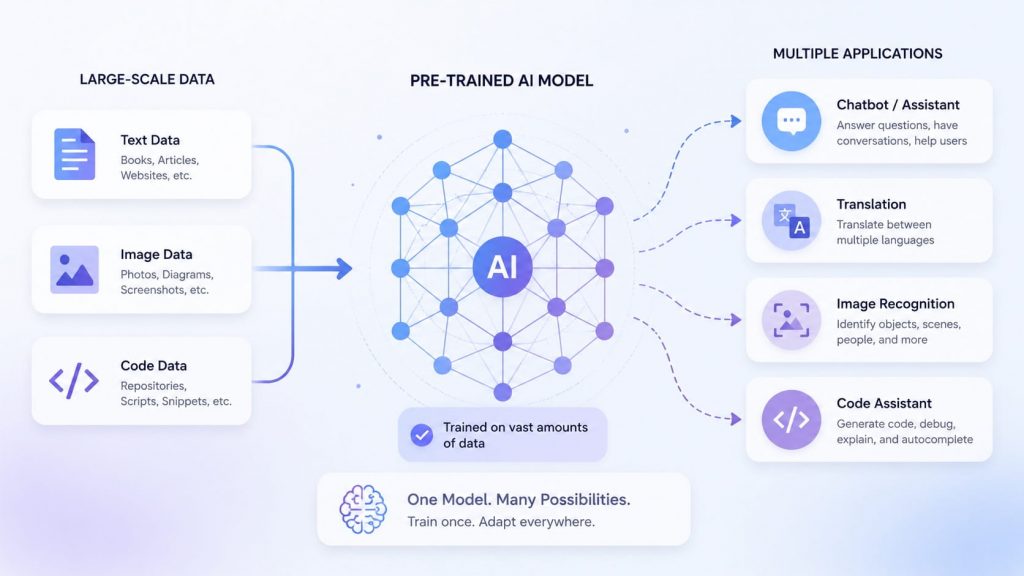
A pretrained AI model is a deep learning system, built on neural network principles
2. Pre-training vs fine-tuning vs inference
When working with pre-trained models, it is important to distinguish between pre-training, fine-tuning, inference, and transfer learning. These concepts are closely related, but they describe different stages in how an AI model is trained, adapted, and used in real-world applications.
| Concept | Simple meaning | Example |
| Pre-training | The model learns general patterns from large datasets before being used for a specific task. | A language model learns from large text datasets to understand grammar, context, and common knowledge. |
| Fine-tuning | The pre-trained model is further trained on smaller, task-specific data to improve performance. | A chatbot model is fine-tuned on customer support conversations to answer product questions better. |
| Inference | The trained model is used to generate outputs or predictions from new input data. | A summarization model receives a long report and creates a short summary. |
| Transfer learning | A broader approach where knowledge from one task is reused for another related task. | An image model trained on general photos is reused for defect detection in manufacturing. |
In short, pre-training builds the model’s general knowledge, fine-tuning adapts it to a specific task, and inference is when the model is used in production. Transfer learning is the broader method that makes this reuse possible.
3. How does a pre-trained model work?
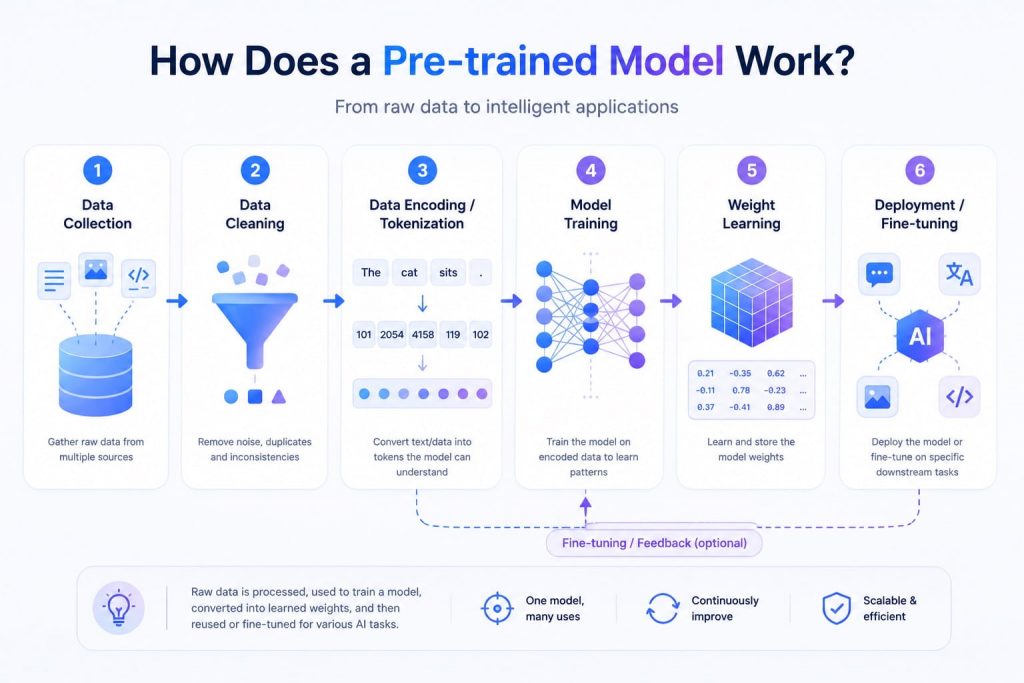
A pre-trained model goes through a full training cycle, collecting and preprocessing data, feeding it into the model, measuring loss, optimizing parameters, and validating performance, until satisfactory results are achieved. Here is a breakdown of how the process works from start to finish:
- Data collection & preprocessing: Training begins with curating vast datasets from diverse sources such as web crawls, journals, Wikipedia, and code repositories. The data is then cleaned through filtering, de-identification, and balancing to remove noise, biases, and harmful content.
- Tokenization or data encoding: After cleaning, the input data is converted into numerical representations that the model can process. For text models, this is usually done through tokenization. For image, audio, or multimodal models, the data is encoded into model-readable formats through other preprocessing methods.
- Architecture selection & training: The model architecture is chosen based on the target task. For example, transformer architectures are widely used for NLP tasks due to their self-attention mechanism, while diffusion models are commonly used in text-to-image generation.
- Weight learning: During training, the model adjusts its internal parameters, or weights, to reduce prediction errors. These weights capture statistical patterns from the training data and become the reusable knowledge base of the pre-trained model.
- Transfer Learning vs Fine Tuning: Rather than starting from scratch, developers can take models that have already learned general features and fine-tune them on smaller, domain-specific datasets. Fine-tuning is one of several types of transfer learning, an umbrella term for techniques that adapt pre-trained models for new uses.
- Deployment: By storing knowledge in large parameters and fine-tuning on specific tasks, the rich knowledge encoded in those parameters can benefit a wide variety of downstream tasks, from natural language processing and image classification to code generation and multimodal AI.
A pre-trained model goes through a full training cycle, collecting and preprocessing data
>>> Explore more: Continual Pretraining: How It Works and When to Use
>>> Explore more: How to Deploy AI Model: A Step-by-Step Guide 2026
4. Pre-trained model vs model trained from scratch
Choosing between a pre-trained model and building one from scratch is one of the most consequential decisions in any AI project. The table below breaks down the key differences across the criteria that matter most in practice.
| Criteria | Pre-Trained Model | Model Trained From Scratch |
| Data requirement | Needs less data because the model already learned general patterns. | Needs a large, high-quality dataset to learn from the beginning. |
| Compute cost | Lower to moderate, especially for fine-tuning or inference. | Very high, especially for large models that require powerful GPUs. |
| Training time | Faster because the model only needs adaptation for most use cases. | Slower because the model must learn everything from scratch. |
| Time to deployment | Shorter, often suitable for quick testing and faster launch. | Longer, usually requiring months of training, testing, and optimization. |
| Flexibility | Good for common tasks, but less ideal for highly niche domains. | High, with full control over architecture, data, and training process. |
| Required expertise | Lower, since many models are already tested and documented. | High, requiring strong ML, data, and infrastructure expertise. |
| Best-fit use cases | Common AI tasks such as text classification, summarization, translation, image recognition, object detection, and chatbots. | Proprietary or highly specialized tasks where existing models are not accurate enough. |
In short, pre-trained models are better when teams need speed, lower cost, and faster deployment. Models trained from scratch are better when the use case is highly specific, the team has enough data and compute resources, and full model control is required.
5. When should you fine-tune a pre-trained model?
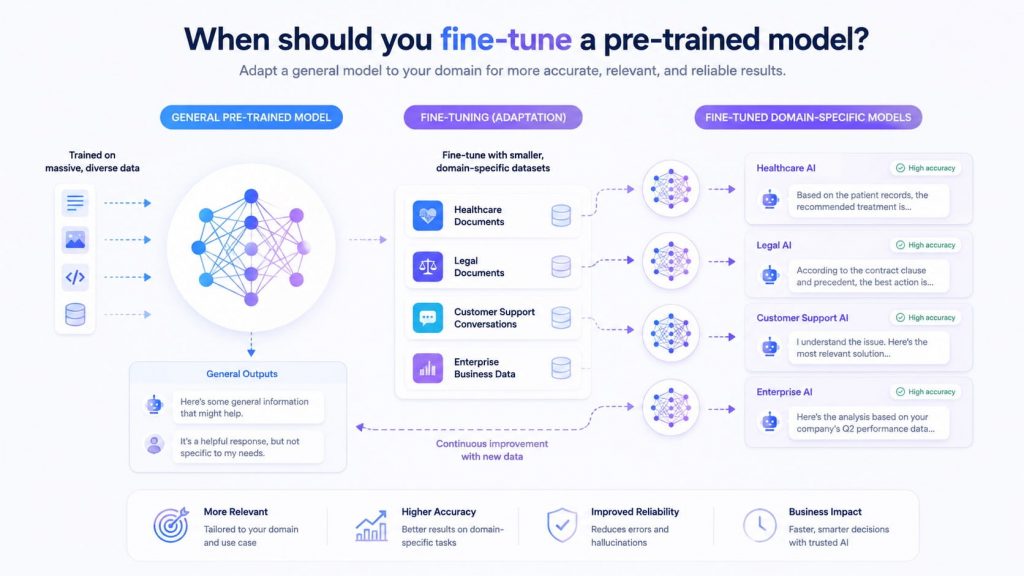
You should fine-tune a pre-trained model in situations where the original model’s general knowledge is not sufficient for your specific task or domain. In particular, fine-tuning is appropriate when:
- You need domain-specific accuracy: Fine-tuning helps the model better understand specialized terminology, patterns, and context in fields such as healthcare, legal, finance, or enterprise operations.
- Your available dataset is limited: Instead of building a model from zero, you can fine-tune a pre-trained model with a smaller, task-specific dataset.
- The base model gives generic or inaccurate results: If the model works but fails to meet your accuracy, relevance, or consistency requirements, fine-tuning can improve task-specific performance.
- You need a specific output style or behavior: Fine-tuning is useful when the model must follow a preferred tone, format, response structure, or business rule. For large language models, comparing prompt engineering and fine-tuning can help determine whether instruction design is enough or model adaptation is needed.
- You want faster customization: Fine-tuning is usually faster and more cost-efficient than training a model from scratch because the model already has reusable knowledge.
You should fine-tune a pre-trained model in situations where the original model’s general knowledge is not sufficient
6. Common use cases of pre-trained models
Pre-trained models are no longer just a research convenience – they are the engine behind some of the most impactful AI applications in production today. From processing financial documents to detecting tumors in medical scans, their range of real-world deployment spans nearly every industry.
6.1 Off-the-shelf AI applications
The fastest way to deploy AI is to use a pre-trained model exactly as it is – no fine-tuning required. Pre-trained large language models have made significant advances, excelling in tasks like question answering, summarization, and machine translation. These capabilities are now readily accessible via model hubs and APIs, enabling teams to ship working AI features in days rather than months.
Text classification
Text classification is one of the most widely used NLP tasks. In recent years, a variety of text classification techniques based on pre-trained language models have emerged, facilitating their application across diverse fields – from sentiment analysis and spam detection to topic categorization and regulatory compliance screening.
In financial services, pre-trained NLP models are commonly used to support compliance screening, document classification, transaction monitoring, and internal knowledge search. Instead of reviewing every document or transaction manually, teams can use these models to identify patterns, flag potential risks, and prioritize cases for human review.
Summarization
Summarization is another area where pre-trained models deliver immediate business value. Models such as BART, T5, and instruction-tuned variants can condense long reports, articles, meeting transcripts, or policy documents into shorter summaries, helping teams review information faster.
Translation
Translation has also matured into a production-grade capability. Modern pre-trained language models can preserve context more effectively than older rule-based systems, making them useful for multilingual customer support, documentation, and internal communication.
Question answering
Question answering systems built on pre-trained models are now embedded in enterprise search, customer portals, and knowledge management tools. These systems help users retrieve answers from large document collections without manually searching through files.
For organizations looking to move quickly, accessing a curated library of production-ready pre-trained models can significantly reduce time-to-value. FPT AI Factory Model Hub is a solution that provides enterprises with ready-to-deploy models across NLP, vision, and multimodal tasks. Inside, this enables teams to integrate AI capabilities directly into their workflows without the overhead of building or sourcing models from scratch.
Pre-trained large language models have made significant advances
6.2 Fine-tuned domain applications
While off-the-shelf models cover a broad range of general tasks, fine-tuning unlocks the full potential of pre-trained models for specialized domains.
Customer support assistants
Customer support assistants are among the most commercially deployed applications. Pre-trained models such as BERT or GPT can be fine-tuned on a specific domain, such as customer service inquiries, to provide accurate responses. For example, a financial services company may use these models to build a chatbot that understands customer inquiries related to account balances, transaction history, or investment options.
>> Explore more: What is LoRA? A Complete Beginner’s Guide
Healthcare and clinical NLP
Healthcare and clinical NLP are growing application areas for fine-tuned pre-trained models. Domain-specific models such as BioBERT and ClinicalBERT can be adapted for tasks like named entity recognition in clinical notes, adverse drug reaction detection, medical record summarization, and information extraction from healthcare documents.
In real-world healthcare settings, NLP systems are often used to analyze clinical notes, support triage workflows, summarize patient records, and assist with operational planning. However, these applications typically require strict validation, privacy controls, and expert oversight before deployment.
Legal NLP
Legal NLP is another high-value domain where fine-tuned models replace expensive manual review. Legal teams use fine-tuned pre-trained models to extract compliance requirements from contracts, screen communications for regulatory violations, and classify clauses across large document sets, tasks that previously required specialized attorneys reviewing documents line by line.
Code assistants
Code assistants such as GitHub Copilot and similar tools are built on large pre-trained language models fine-tuned on code repositories. These systems help developers autocomplete functions, identify bugs, and generate boilerplate code across dozens of programming languages. These systems help developers autocomplete functions, identify bugs, generate boilerplate code, and improve productivity across different programming languages.
Internal enterprise copilots
Internal enterprise copilots are emerging as one of the most strategic use cases, where companies fine-tune pre-trained models on proprietary documents, internal wikis, and communication history to create AI assistants that understand their specific domain, terminology, and processes.

Fine-tuning unlocks the full potential of pre-trained models for specialized domains
Explore more:LoRA vs QLoRA: Efficient Fine-Tuning techniques for LLM
Explore more: What Is MLOps? The Guide to Machine Learning Operations
6.3 Computer vision and multimodal tasks
Beyond language, pre-trained models have become the foundation of modern computer vision, powering applications from quality control on factory floors to autonomous navigation.
Image classification
Image classification relies heavily on pre-trained convolutional and transformer architectures. Pre-trained models like ResNet, introduced by Microsoft Research, are widely used for general image classification, object detection, and feature extraction, with deep architectures up to 152 layers that progressively extract low-level to high-level features. These models can be adapted to various domains, from medical imaging to autonomous driving.
Object detection
Object detection has advanced dramatically in recent years. Self-driving cars use computer vision tasks like object detection to navigate safely and avoid obstacles, recognizing pedestrians, other vehicles, potholes, and road hazards. In medical imaging, object detection models can automatically identify key features in X-rays, MRIs, CT scans, and ultrasounds with high accuracy, reducing workload and improving diagnostic efficiency.
For real-time object detection, the YOLO family of models remains widely used because of its speed and practical deployment advantages. Different YOLO versions are commonly applied in use cases such as manufacturing inspection, traffic monitoring, retail analytics, and safety systems.
Vision-language and segmentation models
Vision-language and segmentation models are also expanding multimodal AI capabilities. These systems combine visual and text understanding, enabling applications such as visual question answering, image-grounded search, prompt-based segmentation, and document image analysis.
In retail, vision-language models are being used to power visual product search. In manufacturing, they enable natural-language queries over live camera feeds for quality inspection, capabilities that would have required months of custom development just a few years ago.

Pre-trained models have become the foundation of modern computer vision
7. Benefits of using pre-trained models
Using pre-trained models brings significant advantages in machine learning, especially when building AI systems quickly and efficiently. This approach not only improves performance but also reduces the overall complexity of development.
- Faster development and reduced training time: Pre-trained models eliminate the need for full training cycles, cutting development time from months to days or weeks.
- Better performance and accuracy: Since they are trained on large, high-quality datasets, these models already capture useful features, leading to more accurate and reliable results.
- Lower data requirements: They can achieve strong performance even with smaller datasets, making them ideal when labeled data is limited or expensive to collect.
- Reduced computational cost: Training from scratch requires significant computing power, while pre-trained models reuse existing knowledge, saving resources and infrastructure costs.
- Transfer learning flexibility: A single pre-trained model can be adapted to multiple related tasks, enabling reuse across different applications and domains.
- Proven and reliable architectures: Many pre-trained models are already tested, benchmarked, and widely used, which reduces risk and improves stability in real-world applications.
8. Challenges and limitations of pre-trained models
While pre-trained models offer speed and efficiency, they are not a perfect solution for every use case. Understanding their limitations is essential to avoid over-reliance and to decide when additional customization or alternative approaches are necessary.
- Limited domain adaptability: Models trained on general-purpose datasets may struggle in highly specialized domains, yielding less accurate or irrelevant outputs.
- Bias and fairness issues: Pre-trained models can inherit biases from their training data, leading to skewed or unfair predictions if not carefully evaluated.
- Lack of transparency: Many models operate as “black boxes,” making it difficult to interpret how they make decisions, especially in critical applications.
- Data privacy and security concerns: When using external APIs or third-party pre-trained models, teams need to review how business data is processed, stored, and protected, especially in regulated industries.
- Dependency on original training data: The quality and scope of the initial dataset heavily influence performance, and this cannot always be fully controlled by the end user.
- Fine-tuning complexity: Adapting a model to a specific task may still require expertise, computational resources, and careful parameter tuning.
- Model size and resource demands: Some pre-trained models are large and require significant memory and processing power to deploy effectively.
Large pre-trained models may require significant GPU memory and compute resources, especially for high-volume or low-latency applications. For teams evaluating deployment infrastructure, understanding what AI inference is can help clarify how pre-trained models are served in real-world systems.
To help you get started without upfront commitment, FPT AI Factory offers a Starter Plan that includes $100 in free credits for new users to explore the platform over 30 days. Once you register, the full $100 credit is instantly available right after login – no setup steps or approval needed – so you can begin experimenting with pre-trained models immediately.
If you are an enterprise or organization with requirements for fine-tuning, customization, or large-scale deployment of pre-trained models, please reach out to FPT AI Factory through the official contact form to receive dedicated consultation and tailored solutions.
 Understanding their limitations is essential to avoid over-reliance
Understanding their limitations is essential to avoid over-reliance
In summary, understanding pre-trained models helps businesses better evaluate how modern AI capabilities can be adopted efficiently, from deploying off-the-shelf NLP applications to fine-tuning domain-specific solutions in healthcare, legal, and enterprise workflows. With pre-trained models as the foundation, organizations can significantly reduce development time, lower costs, and bring AI-powered products to market faster.
If you’re ready to explore pre-trained models or want to experience their capabilities through a flexible, enterprise-ready AI platform, now is a great time to get started. Contact FPT AI Factory to receive consultation immediately!
Contact information
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore related articles:
What Is Data Infrastructure? Key Components and How to Build It


