
Understanding what is training data is essential in machine learning, as it determines how AI systems learn patterns and generate accurate outputs from real-world information. At FPT AI Factory, this foundation is critical for building scalable AI solutions, where the quality and structure of data directly impact model performance, reliability, and deployment success.
1. What is Training Data?
Training data is a collection of examples used to teach machine learning models how to recognize patterns and perform specific tasks. These examples can come in different formats such as text, images, audio, video, or structured data, depending on what the AI system is designed to learn.
By analyzing this data, the model learns relationships and patterns that help it make predictions or decisions on new, unseen inputs. The better the training data represents real-world situations in terms of quality, diversity, and accuracy, the more reliable and effective the AI model becomes.
For example, in a chatbot like KLM Royal Dutch Airlines’s BlueBot, training data includes thousands of real customer conversations about flight changes, baggage, and refunds. Each interaction is structured into input–response pairs, such as a user asking to change a flight and the correct reply explaining rebooking policies and fees. By learning from these labeled interactions (e.g., intent and key details like dates), the model can understand requests and generate accurate, context-aware responses.

Training data helps AI models learn patterns and make predictions
2. Why does training data quality matter in AI?
The performance of an AI model is directly influenced by the quality of its training data. Poor-quality data leads to biased, inaccurate, or unreliable outputs. Key quality factors include:
- Completeness: The dataset should contain enough information for the model to learn effectively. Missing data can lead to gaps in understanding and weaker predictions.
- Consistency: Data should follow a uniform format without conflicts or contradictions, helping the model learn stable patterns.
- Accuracy: Correct and reliable data is essential because incorrect inputs will directly lead to wrong outputs from the model.
- Timeliness: Data should reflect current conditions, as outdated information can reduce model relevance in real-world use cases.
- Relevance: The data must match the problem the AI is solving so the model learns useful and meaningful patterns instead of unrelated signals.
- Label Integrity: In supervised learning, labels must be correct and consistent. Incorrect labeling can cause misclassification and reduce model reliability.
When these factors are well maintained, the model learns from clean, meaningful data instead of noise, resulting in more accurate and reliable AI performance, whether it is fine-tuning or GPU computing.

High-quality training data ensures accurate, reliable, and unbiased AI performance
3. Types of Training Data
Training data can appear in different forms depending on how it is created and how the model is expected to learn from it. Each type comes with its own advantages and challenges in data preparation and model training.
3.1. Labeled vs. Unlabeled Data
Training data can be categorized based on whether it includes predefined answers or not. This distinction affects how the model learns and how much human preparation is required before training. Common types include:
- Labeled data: Data where each input is paired with a correct answer, such as an image tagged as “cat” or a customer review labeled as “positive.” It is commonly used in supervised learning, where the model learns from clear examples.
- Unlabeled data: Raw data without predefined answers, such as a folder of images, text documents, or transaction records with no assigned category. It is often used in unsupervised learning, where the model identifies patterns and structures on its own.
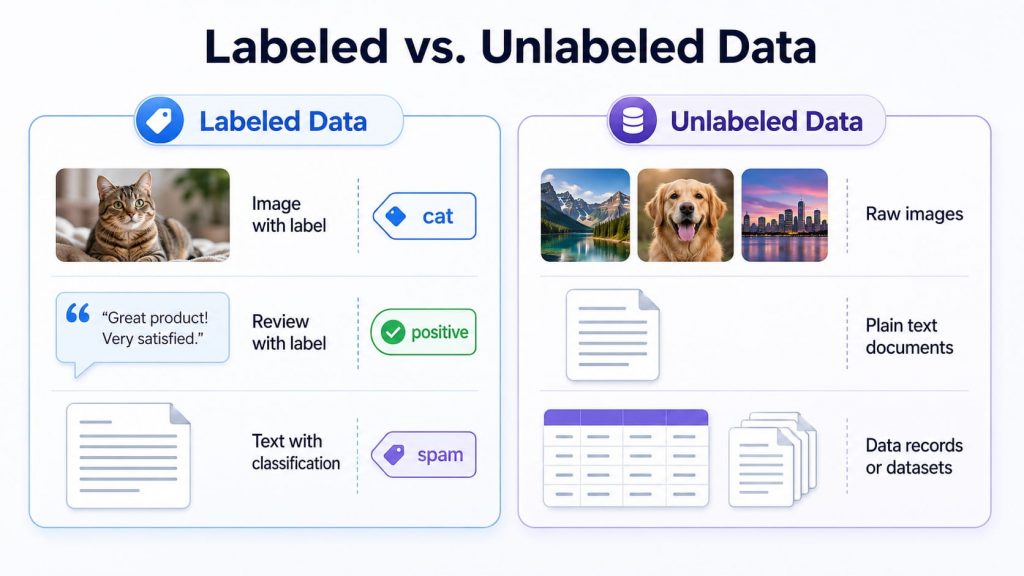
Labeled data gives models clear answers, while unlabeled data helps them learn from raw inputs.
3.2. Structured vs. Unstructured Data
Training data can also be grouped by how it is organized. Some datasets follow a fixed format, while others appear in more flexible and complex forms. Common types include:
- Structured data: Data organized in rows, columns, or predefined fields, such as spreadsheets, databases, CRM records, or transaction logs. It is easier to search, filter, and process because the format is consistent.
- Unstructured data: Data that does not follow a fixed structure, such as emails, images, audio files, videos, PDFs, and social media posts. It often contains rich information but requires more advanced AI techniques to process and understand.
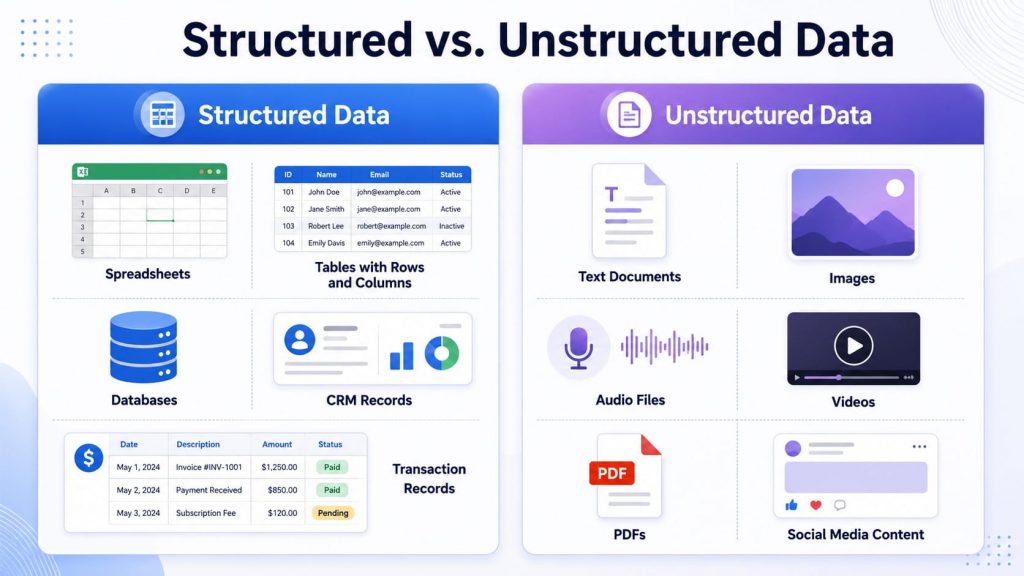
Structured data follows fixed formats, while unstructured data includes more flexible content like text, images, and audio.
3.3. Synthetic Data vs. Real Data
Another way to classify training data is by how it is created. Some data comes directly from real-world environments, while other data is artificially generated to support model development. Common types include:
- Synthetic data: Artificially created data designed to simulate real-world information. It is often used when real data is limited, sensitive, expensive to collect, or difficult to access.
- Real data: Data collected directly from actual environments such as users, systems, sensors, transactions, or business operations. It reflects real-world behavior more accurately and is important for building models that perform reliably in production.
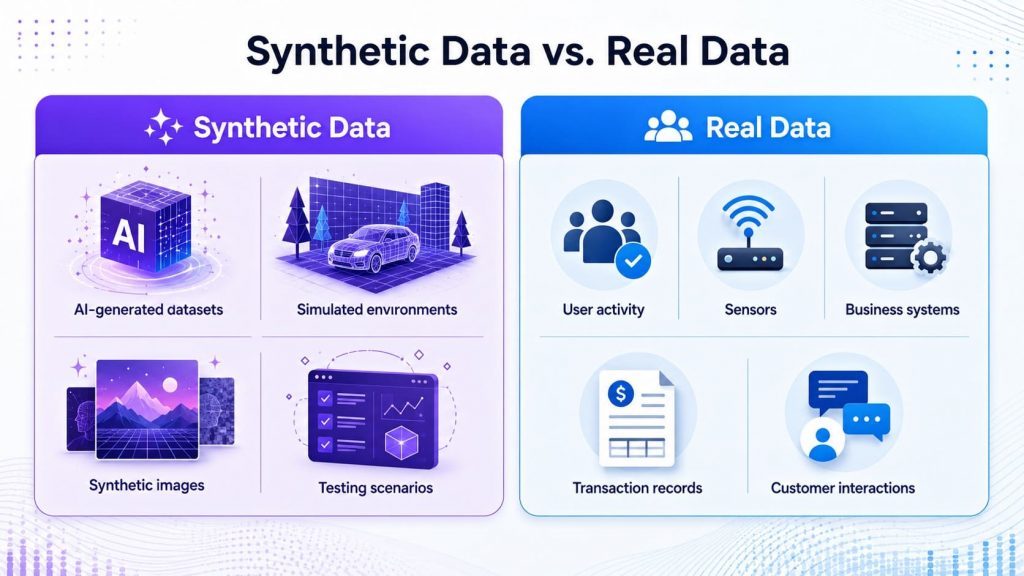
Synthetic data is generated artificially, while real data comes from actual users, systems, or environments.
3.4. Training Data for Large Language Models (LLMs)
Large language models require massive and diverse training datasets to learn language patterns, reasoning ability, and contextual understanding. Unlike traditional machine learning systems that often rely on structured tables or labeled records, LLMs are trained on large volumes of text and multimodal content from many different sources. Common types of training data for LLMs include:
- Web text: Publicly available online content such as articles, websites, forums, and documentation that helps models learn general language patterns and real-world knowledge.
- Books: Long-form written content that helps models understand narrative structure, domain knowledge, and complex reasoning.
- Code datasets: Programming repositories and technical documentation that support code generation, debugging, and software-related tasks.
- Synthetic instruction datasets: Artificially generated examples that teach models how to follow prompts, answer questions, summarize content, or complete task-based instructions.
- RLHF datasets: Human feedback data used in reinforcement learning from human feedback, helping models produce responses that are more useful, safe, and aligned with user expectations.
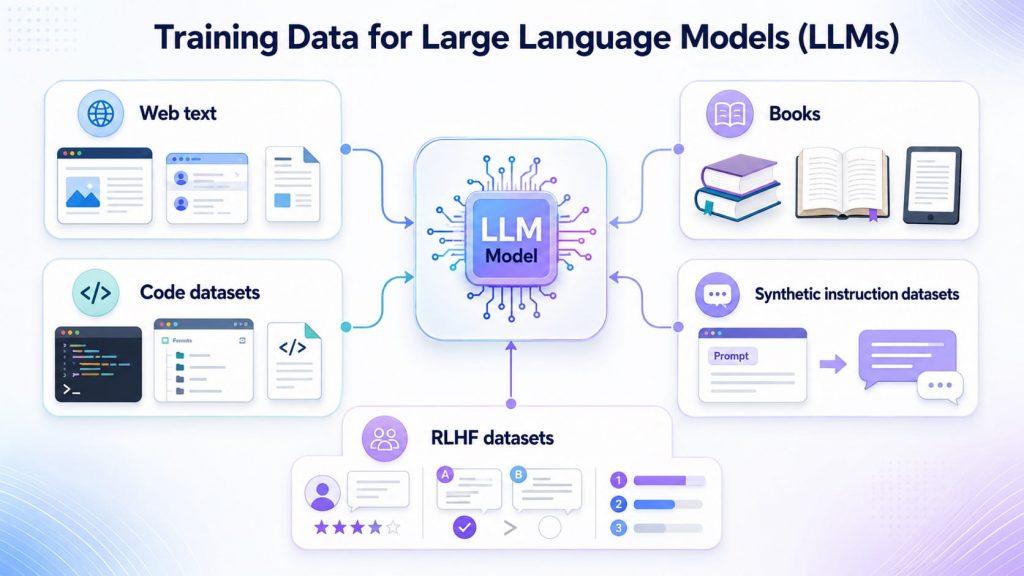
LLMs learn from diverse data sources such as web text, books, code, instructions, and human feedback.
4. How Does Training Data Fit into the AI Pipeline?
Before a model can learn effectively, training data needs to be carefully prepared through several steps. Each stage focuses on improving data quality so the model can learn accurate and meaningful patterns.
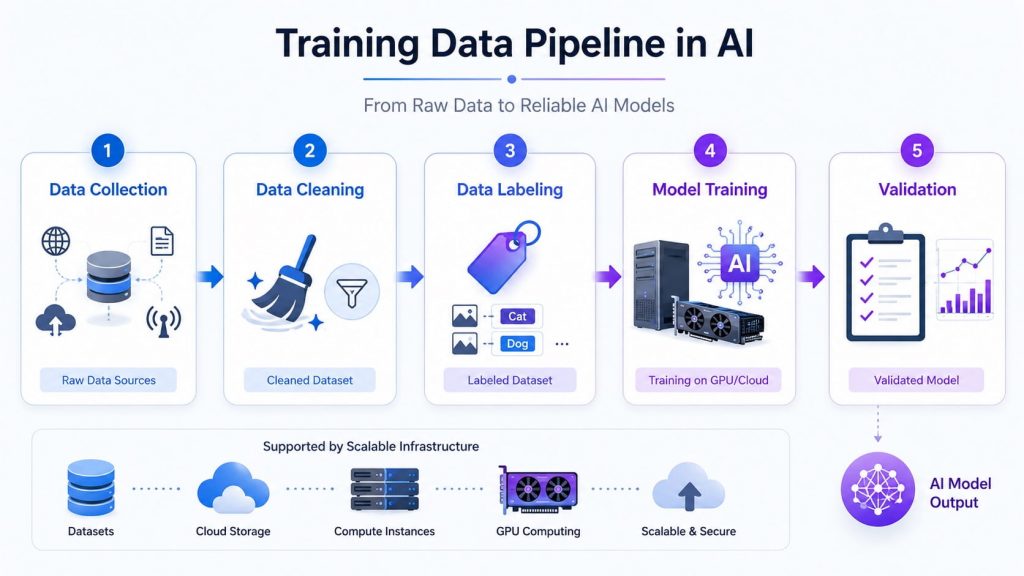
Training data moves through collection, cleaning, labeling, model training, and validation before becoming a reliable AI model output.
4.1 Data Collection
The process begins with gathering data from different sources such as applications, business systems, sensors, or public datasets. At this stage, having a clear goal helps ensure the data you collect is relevant and useful for the problem you want to solve.
4.2 Data Cleaning
Raw data is rarely perfect. You’ll often find missing values, duplicate entries, or inconsistent formats. Cleaning is the step where you fix these issues, such as removing errors, standardizing formats, and making sure the dataset is usable. This step might feel tedious, but it has a huge impact on model accuracy later on.
4.3 Data Labeling
If your project uses supervised learning, the next step is labeling the data. This means assigning the correct answer to each input, like tagging an image or classifying a piece of text. The model relies heavily on these labels to learn correctly, so even small mistakes here can lead to poor results.
4.4 Model Training
Once the data is prepared, the model is trained by learning patterns and relationships from the dataset through repeated iterations. During this process, data is often refined by selecting relevant features and converting it into formats the model can process, such as numerical representations. At this stage, having the right AI infrastructure is essential to efficiently handle large-scale data and support scalable, high-performance training.

Models learn patterns through iterative training, supported by scalable AI infrastructure (Source: FPT AI Factory)
4.5 Validation
After training, you need to check how well the model actually performs. This is done using a separate dataset that the model hasn’t seen before. It helps you understand whether the model can handle real-world data or if it has just memorized the training set.
>> Explore more: What Is Data Infrastructure? Key Components and How to Build It
5. Common Challenges in Training Data Collection
Even with a clear pipeline, collecting and preparing training data still comes with practical challenges. These issues can affect both model performance and the overall cost of building AI systems.
5.1 Data Labeling at Scale
As datasets grow, labeling becomes increasingly difficult to manage efficiently. The challenge is not only assigning labels, but also maintaining accuracy and consistency across large volumes of data.
Common issues include:
- High cost and time required for manual labeling
- Inconsistencies caused by different annotators
- Difficulty scaling while maintaining quality
In addition, large-scale datasets put significant pressure on computing resources during model training. Without sufficient GPU power, training can become slow and inefficient. This is where FPT AI Factory supports AI development with scalable cloud solutions:
- GPU Container: Supports LLM training, scalable AI inference, and offers high-performance workload through the benefits of cloud computing on GPU infrastructure.
- GPU Virtual Machine: Deploy, train, and scale AI models fast with full control and high-performance GPU infrastructure.
These services allow teams to run training workloads faster, scale resources as needed, and reduce the burden of managing infrastructure. In the near future, FPT AI Factory will also offer next-generation GPU HGX B300, with pre-order and consultation available via the GPU Virtual Machine page.

HGX B300 delivers high-performance AI training and inference on Blackwell Ultra architecture (Source: FPT AI Factory)
5.2 Data Privacy and Compliance
When working with training data, especially user-related information, legal and ethical considerations become critical. Key areas to focus on include:
- GDPR: Ensuring data is collected and used with proper consent and transparency
- Data protection: Applying security measures to prevent unauthorized access or data breaches
- Sensitive data: Managing personal or confidential information carefully, often requiring anonymization or restricted usage
5.3 Keeping Data Fresh
Data does not stay relevant forever. As user behavior, market conditions, or system environments change, older datasets may no longer reflect reality.
Some common challenges include:
- Data drift: The underlying patterns in data change over time, reducing model accuracy
- Data decay: Certain types of data, such as customer or business information, can quickly become outdated
- Continuous updates: Models need regularly refreshed data and monitoring to stay effective
Keeping training data up to date helps ensure that AI systems continue to produce reliable results instead of relying on outdated patterns.
>> Explore more: Container vs. Virtual Machine: What are the differences?
6. Frequently Asked Questions
6.1 What is the difference between training data and testing data?
Training data is used to teach a machine learning model by helping it learn patterns and relationships from the data. Testing data, on the other hand, is a separate dataset used after training to evaluate how well the model performs on new, unseen inputs. This helps ensure the model can generalize effectively instead of simply memorizing the training data.
6.2 Can AI work without training data?
AI cannot work completely without data. Even when an AI system does not rely on traditional large-scale, human-labeled training datasets, it still needs some form of data, rules, examples, or input signals to function. For example, rule-based systems depend on predefined logic, while machine learning and generative AI models require training data to learn patterns, make predictions, and improve performance.
6.3 What does training data look like?
Training data can take many forms depending on the task the AI model is designed to perform. It may include text, images, audio, video, or numerical data. These can be structured, like tables and databases, or unstructured, such as emails, photos, or social media content.
6.4 What is a dataset in AI?
A dataset in AI is a collection of data used throughout the model development process. It is typically organized and prepared for different stages such as training, validation, and testing. This structure helps ensure the model learns effectively and performs reliably on new data.
Training data is the foundation of every AI system, and its quality determines how reliable and effective a model becomes in real-world scenarios. From data collection to model validation, each stage plays a critical role in shaping AI performance.
With FPT AI Factory, you can easily access scalable infrastructure to process and train AI models efficiently. You get $100 free credit just by logging in and using it immediately. For enterprise or large-scale customized needs, you can submit a request via the contact form of FPT AI Factory for dedicated consultation and solutions.
Contact information:
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more articles:


