
Overfitting and underfitting in machine learning are problems that affect how well a model performs on real-world data. Understanding the difference helps AI teams improve model accuracy, reduce training risks, and build more reliable applications. At FPT AI Factory, developers and enterprise teams can access an AI development ecosystem that supports the workflow from infrastructure to model testing
1. What is Overfitting?
For complex deep learning models, especially those built on transformer architecture in AI, overfitting happens when a machine learning model learns the training data too closely, including noise, outliers or small details that do not represent the wider pattern. As a result, the model performs very well on training data but fails to generalize to new or unseen data.
For example, imagine an AI model trained to classify cats and dogs using 10,000 training images. Most dog images in the training dataset accidentally contain green grass backgrounds, while many cat images are taken indoors. Instead of learning the actual visual features of cats and dogs, the model starts associating “grass” with dogs. During training, the model may achieve 98-99% accuracy because it memorizes these patterns. However, when users upload a photo of a dog inside a house, the model may incorrectly predict it as a cat because the background pattern is different from the training data.
1.1 Signs your model is overfitting
A model is likely overfitting when the gap between training performance and validation performance becomes too large. For example, training accuracy continues improving while validation accuracy plateaus or starts to decrease. Another common sign is loss divergence, where training loss continues to fall but validation loss rises after a certain number of epochs.
This pattern shows that the model is no longer learning useful general rules. Instead, it is becoming too specialized for the training dataset. Monitoring loss curves is important because training and validation loss can reveal whether the model is improving, plateauing or starting to generalize poorly.
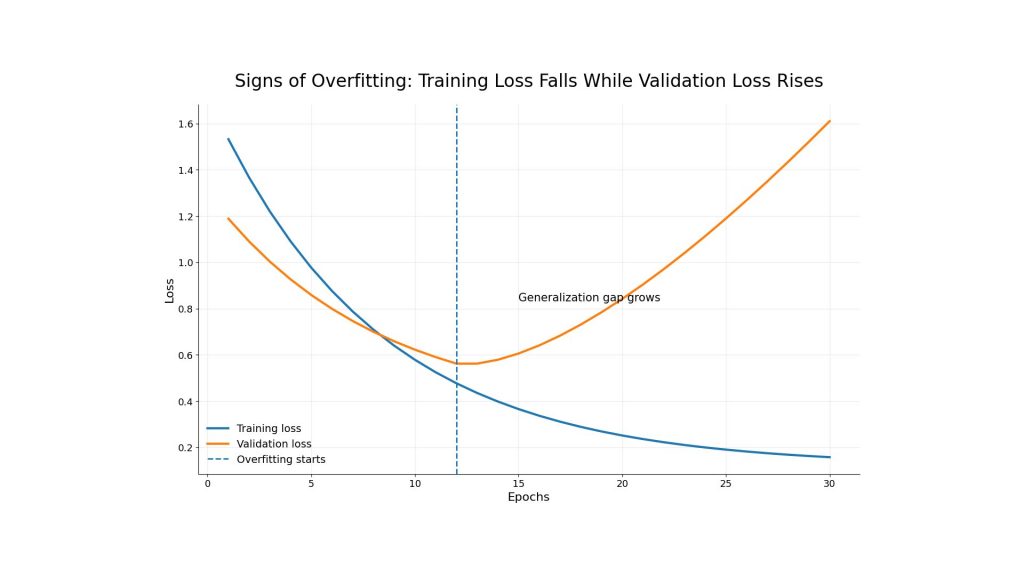
A line chart showing training loss decreasing while validation loss starts increasing after several epochs.
1.2 What causes overfitting?
Several factors can lead to overfitting, but the most common causes are model complexity, limited data, and weak regularization.
- Too complex model: A deep neural network or highly flexible algorithm may learn unnecessary details from the training data. When the model has too many parameters compared to the amount of data, it can memorize examples instead of learning general patterns.
- Too little data: Small datasets make it harder for the model to understand the full distribution of real-world cases. If the training set does not include enough variety, the model may perform poorly when it sees new inputs.
- No regularization: Regularization helps control model complexity. Without it, the model may continue optimizing training performance while losing the ability to generalize.
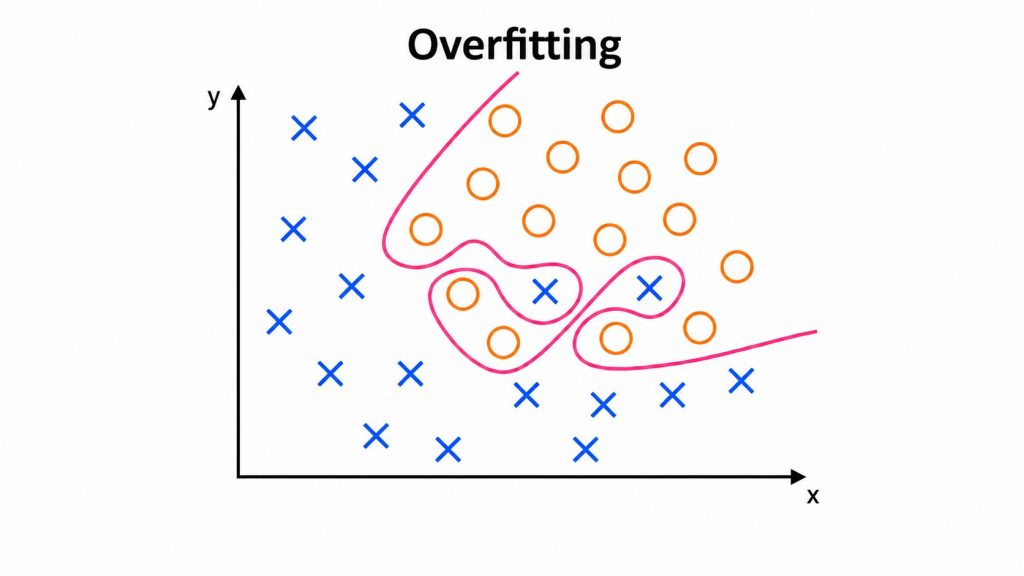
A model that is too complex memorizes noise instead of learning general patterns
2. What Is Underfitting?
Underfitting happens when a model is too simple to capture the real patterns in the data. Unlike overfitting, an underfitting model performs poorly on both training data and validation data. This can occur when the model architecture, feature representation, or training process is insufficient to capture the underlying patterns in the data.
An underfitted model occurs when the model does not have enough complexity or parameters to represent the relationships within the dataset. For example, when predicting house prices, the model should consider multiple factors such as house size, location, nearby amenities, property condition, and surrounding infrastructure. However, if the model only uses house size as the input feature, it cannot fully understand the real relationship between the data and the target outcome.
As a result, the predictions become inaccurate on both the training dataset and the testing dataset because the model oversimplifies the problem and ignores other important variables that strongly influence house prices. This condition is known as high bias, where the model makes stable but consistently incorrect predictions due to overly simplistic assumptions about the data.
2.1. Signs your model is underfitting
The clearest sign of underfitting is low performance across both training and validation datasets. Training accuracy is low, validation accuracy is also low, and both training loss and validation loss remain high. This means the model has not learned the training data well enough.
Another sign is that the model produces overly simple predictions. This occurs when a machine learning model is too limited to understand the main patterns in the data. As a result, the model cannot learn more complex relationships and often performs poorly on both the training dataset and new, unseen data.
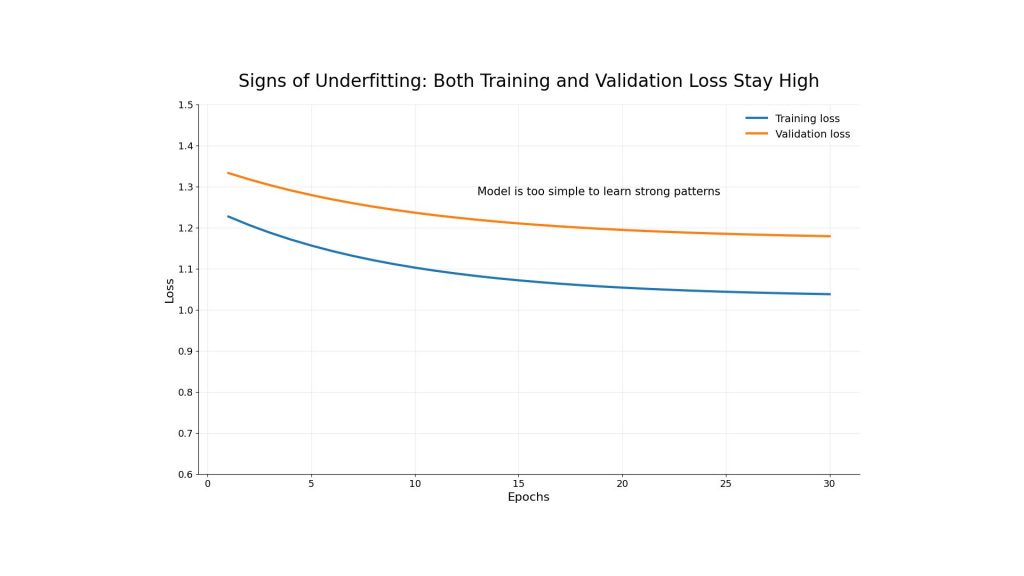
Underfitting in machine learning occurs when both training loss and validation loss remain high across epochs
2.2. What causes underfitting?
Underfitting can happen when the model does not have enough capacity, training time or useful features.
- A model may be too simple for the problem. For example, using a basic linear model for image recognition or natural language processing may not capture the complexity of the data. Underfitting can also happen when the model is trained for too few epochs, meaning it stops before learning meaningful patterns.
- Poor feature quality is another common reason. If the input data does not contain useful signals, even a strong model may fail to learn. In some cases, excessive regularization can also make the model too restricted, preventing it from fitting the data properly.
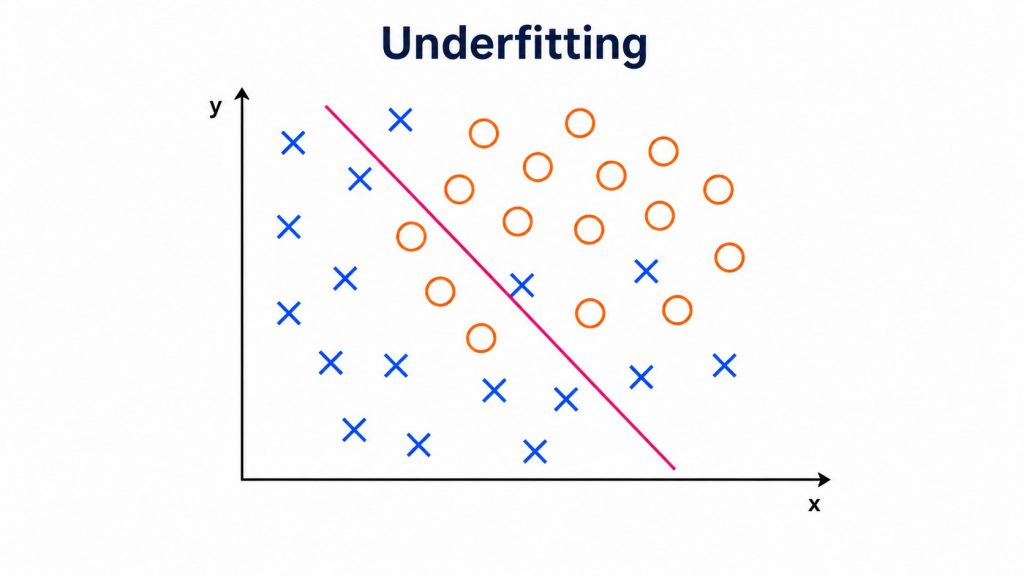
A model that is too simple fails to capture the true pattern of the data
3. Overfitting vs Underfitting: Key differences
Overfitting and underfitting are opposite problems, but both reduce model performance. Overfitting means the model learns too much from the training data, while underfitting means the model learns too little. Both issues are core challenges in building reliable AI systems because they affect how well models generalize to new data.
| Criteria | Overfitting | Underfitting |
| Model complexity | Too complex | Too simple |
| Training error | Low | High |
| Validation error | High | High |
| Generalization | Poor on unseen data | Poor on both seen and unseen data |
| Typical cause | Too many parameters, limited data, no regularization | Simple model, weak features, insufficient training |
| Common solution | Regularization, early stopping, more data | Increase complexity, train |
4. How to overcome Overfitting?
Overfitting can be reduced by improving how the model learns, how it is evaluated, and how the training process is controlled. The goal is not only to increase training accuracy but also to improve generalization. A model that generalizes well can perform more consistently on new data.
4.1. Regularization (L1, L2, Dropout)
Regularization limits model complexity by adding a penalty during training. L1 and L2 regularization are common methods that discourage the model from relying too heavily on certain parameters. Dropout is another technique often used in neural networks, in which some neurons are randomly deactivated during training to reduce dependence on specific paths.
The purpose of regularization is to help the model focus on stronger and more general patterns. However, it should be tuned carefully. Too little regularization may not prevent overfitting, while too much can lead to underfitting.
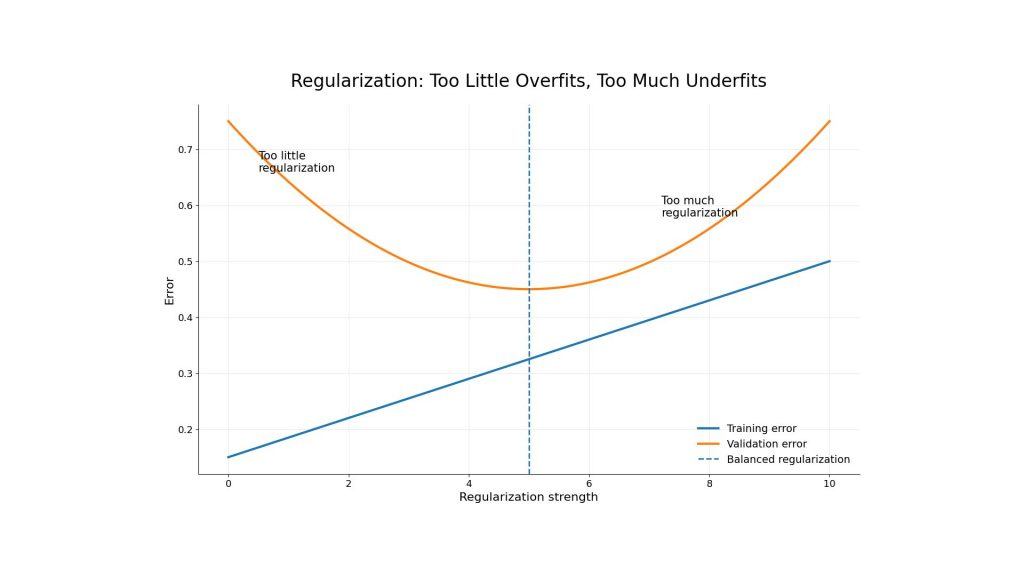
Regularization helps reduce overfitting by controlling model complexity, but excessive regularization may lead to underfitting
4.2. Early Stopping
Early stopping is one of the most practical ways to control overfitting. During training, the team monitors validation metrics such as validation loss, validation accuracy, precision, or recall. If the validation performance stops improving or starts getting worse, training can be stopped before the model overfits.
For example, a model may improve until epoch 15, but after that, training loss continues to drop while validation loss rises. This means the model is learning training-specific details instead of useful general patterns. Early stopping helps save computer resources and keeps the model closer to the point where validation performance is strongest.
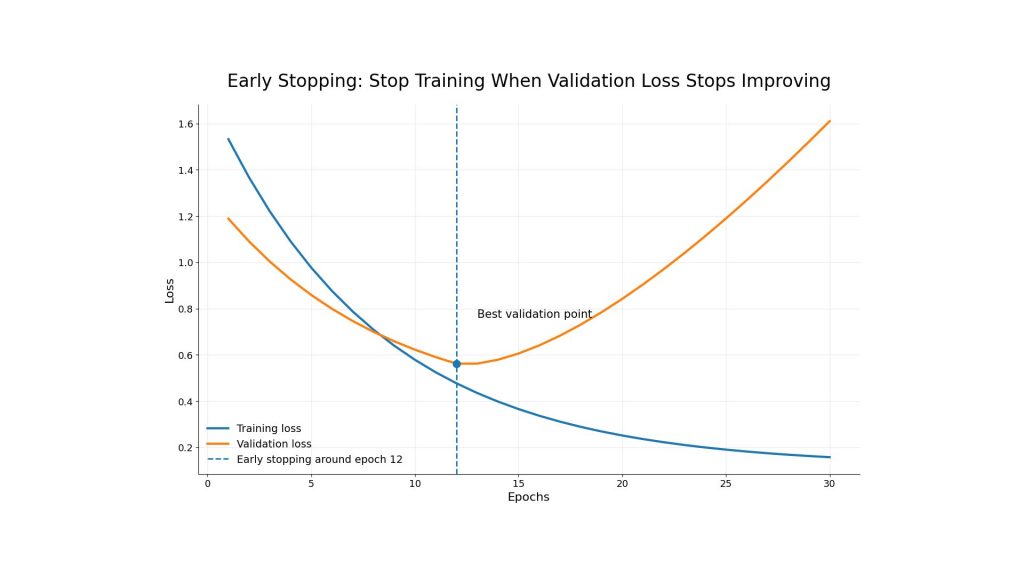
Early stopping prevents overfitting by stopping training when validation loss no longer improves
4.3. Data Augmentation
Data augmentation creates new training examples by transforming existing data. In computer vision, this may include rotating, cropping, flipping or adjusting brightness. In natural language processing, it may involve paraphrasing, back translation, controlled text generation, or synthetic instruction generation.
The benefit is that the model sees more diverse examples during training. This makes it harder for the model to memorize a narrow dataset and easier to learn stable patterns. Data augmentation is especially useful when collecting new data is expensive or time-consuming.
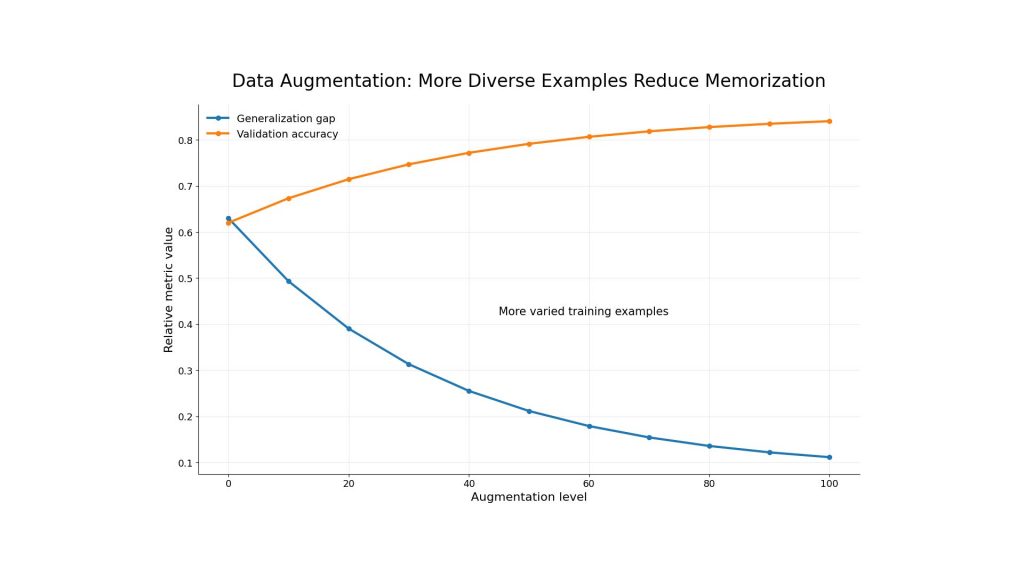
Data augmentation helps reduce overfitting by giving the model more diverse training examples
4.4. Cross-Validation
Cross-validation evaluates a model across multiple data splits instead of relying on one training-validation split. This gives teams a more reliable view of performance and reduces the risk of making decisions based on a lucky or unlucky validation set.
Overfitting often happens when teams lack structured experiment tracking and evaluation processes. In AI production workflows, cross-validation is often combined with experiment tracking systems and automated evaluation pipelines to compare model versions consistently across different training runs and configurations. This helps teams monitor model performance more systematically, identify potential overfitting issues, and select the most suitable model for deployment. Platforms such as FPT AI Factory integrate Model Testing as part of its AI Studio workflow, helping teams evaluate fine-tuning models in a more structured and automated way.
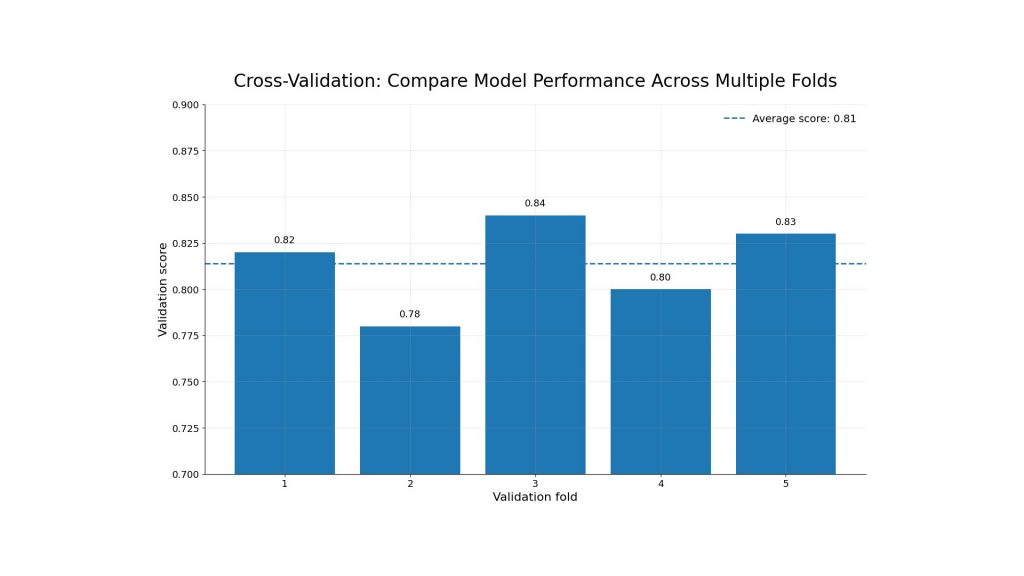
Cross-validation improves model evaluation by testing performance across multiple data splits
4.5. Simplify the Model
Another way to reduce overfitting is to simplify the model. This can mean reducing the number of layers, decreasing the number of parameters, pruning unnecessary features or choosing a less flexible algorithm. A simpler model may perform slightly worse on training data, but it can perform better on new data.
The right level of simplicity depends on the problem. For simple tabular datasets, a smaller model may work well. For complex tasks such as image generation, speech recognition or large language model adaptation, teams may need a larger model with stronger monitoring, regularization, and validation workflows.
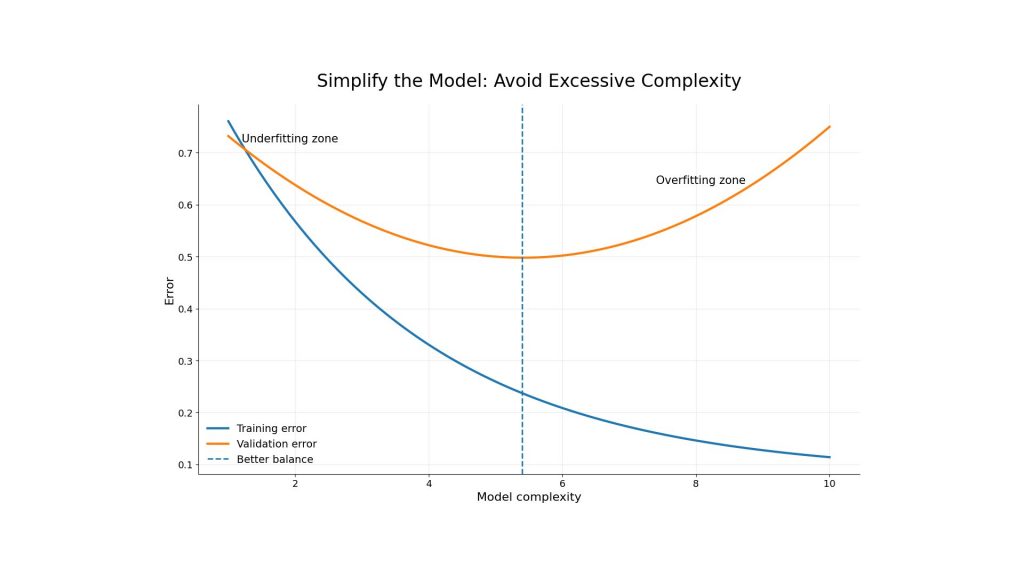
Simplifying the model can reduce overfitting by finding a better balance between complexity and validation error
5. How to Fix Underfitting
Underfitting requires a different approach. Instead of reducing complexity, teams usually need to help the model learn more from the data. This may involve increasing model capacity, training for longer or improving features.
5.1. Increase model complexity
If the model is too simple, increasing complexity can help. For example, a basic linear model may be replaced with a tree-based model, ensemble method or neural network. In deep learning, teams may add more layers, more units or a more suitable architecture.
However, complexity should be increased gradually. A model that becomes too complex may move from underfitting to overfitting. The best approach is to test several configurations and compare validation performance carefully.
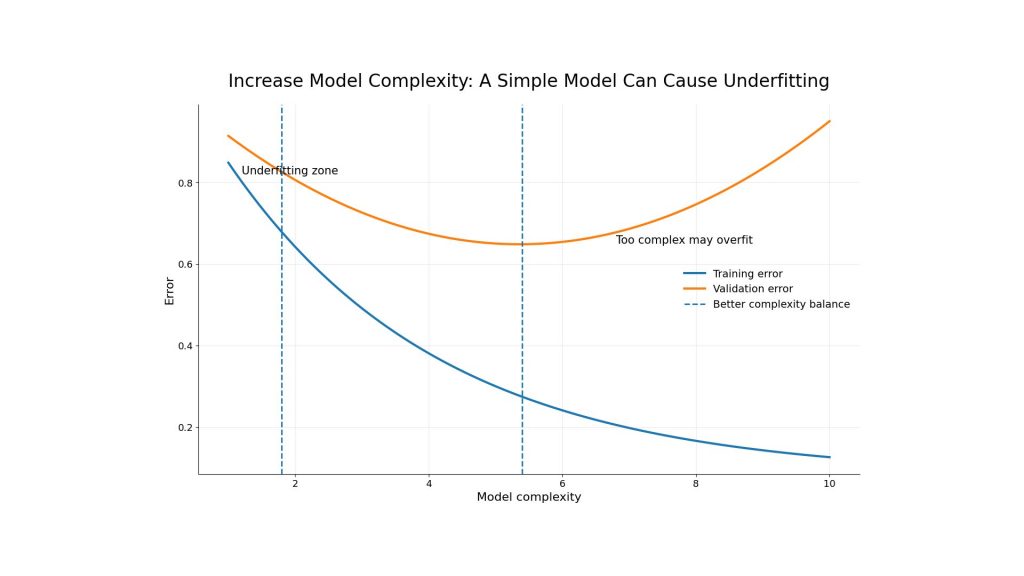
Increasing model complexity can reduce underfitting by helping the model capture more meaningful patterns, but excessive complexity may lead to overfitting
5.2. Train longer / More Epochs
Sometimes a model underfits because it has not trained long enough. Increasing the number of epochs allows the model to continue learning patterns from the data. This is common when training deep learning models, especially in early experiments.
Still, more epochs should come with validation monitoring. If training continues after validation performance stops improving, the model may start overfitting. This is why early stopping and metric tracking are important even when the goal is to fix underfitting.
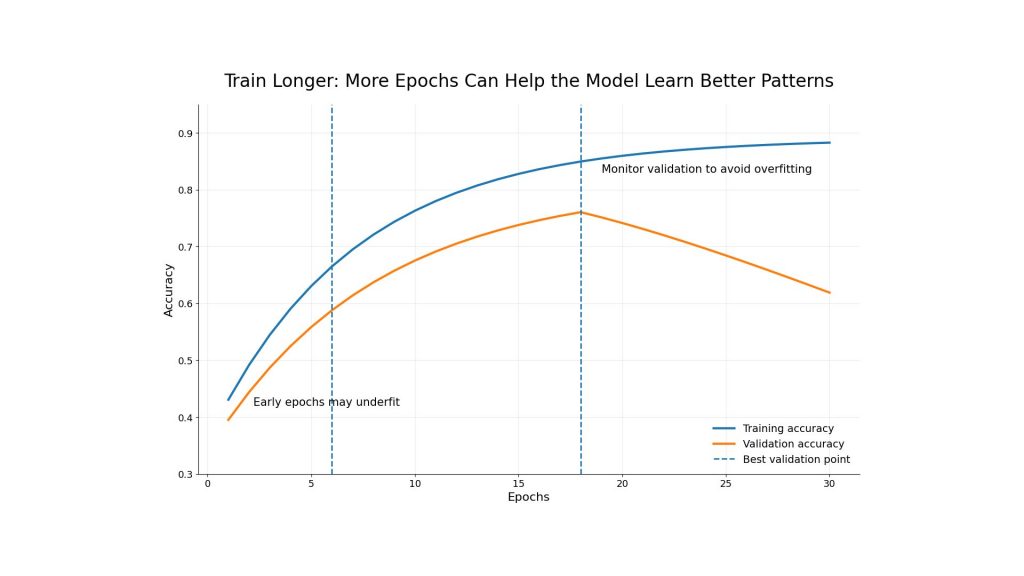
Training for more epochs can improve model learning and reduce underfitting, but validation performance should still be monitored to avoid overfitting
5.3. Feature Engineering
Feature engineering improves the quality of input data. For tabular data, this may include creating ratios, grouping categories, handling missing values or encoding time-based patterns. For text or image data, it may involve better preprocessing, embeddings or domain-specific transformations.
Good features help the model find useful signals more easily. In many machine learning projects, better features can improve performance more than simply changing the algorithm. This is especially true when the original data contains noise or lacks a clear structure.
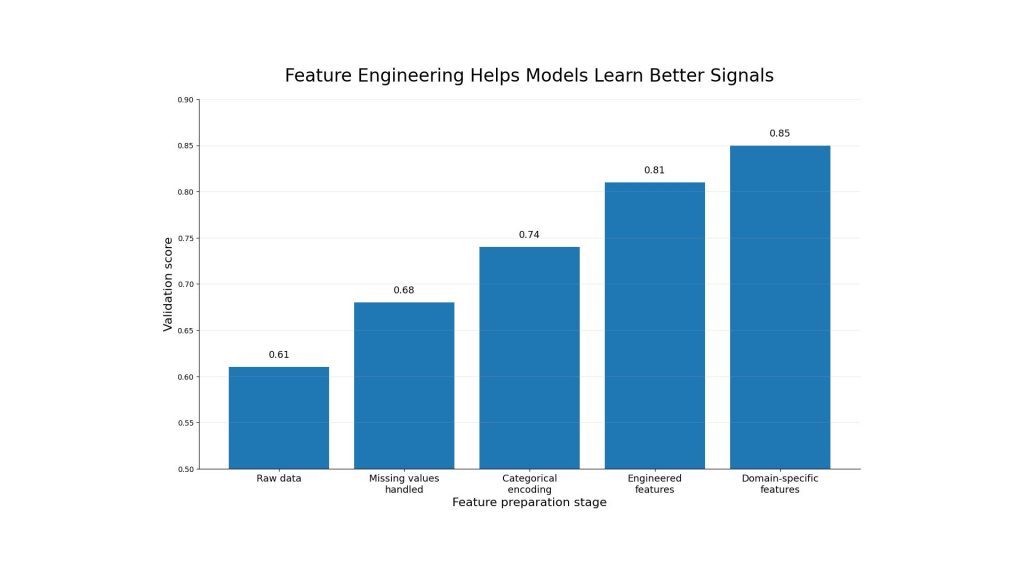
Feature engineering helps reduce underfitting by improving input quality and making useful patterns easier for the model to learn
5.4. Reduce Regularization
If regularization is too strong, the model may become overly restricted. This can stop it from fitting the training data properly and lead to underfitting. Reducing L1 or L2 penalties, lowering dropout rates or relaxing model constraints can help the model learn more.
The key is balance. Regularization should reduce unnecessary complexity without blocking useful learning. Teams should test different levels and compare training and validation results before deciding.
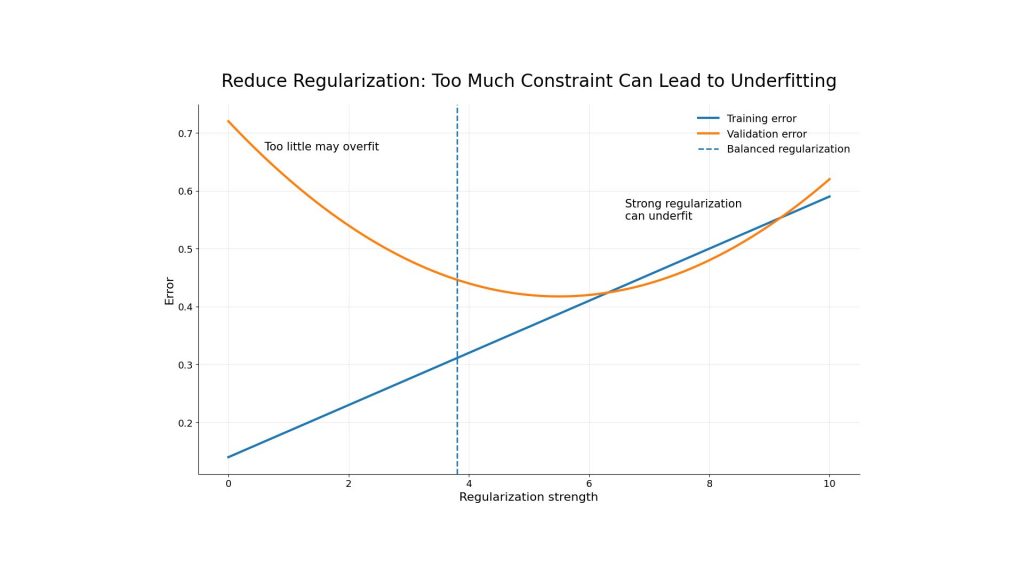
Reducing overly strong regularization can help a model learn more effectively and fix underfitting
5.5. Add more data
Adding more data can help both underfitting and overfitting, depending on the situation. For underfitting, more data can provide broader examples and stronger signals. For overfitting, more data can reduce the risk of memorizing a narrow training set.
The quality of data matters as much as quantity. If new data is noisy, mislabeled, or irrelevant, it may not improve the model. Teams should check data distribution, labels, and preprocessing before using more data in training.
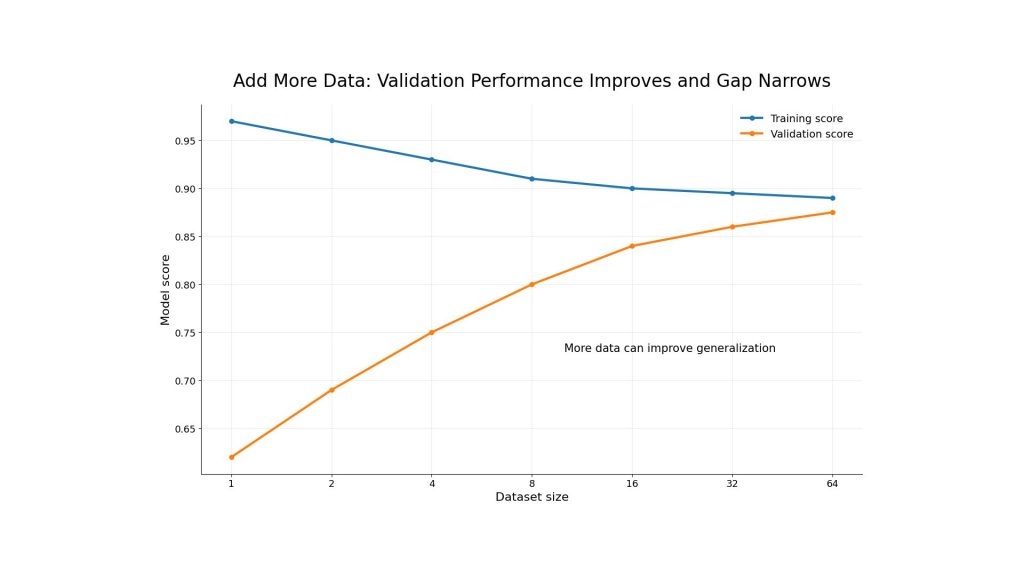
Adding more quality data can improve generalization and reduce the gap between training and validation performance
6. What is the Bias-Variance Tradeoff?
The bias-variance tradeoff explains why overfitting and underfitting happen. Bias refers to error from overly simple assumptions. A high-bias model may underfit because it cannot capture the true pattern. Variance refers to sensitivity to small changes in training data. A high-variance model may overfit because it reacts too strongly to training-specific details.
A good model balances bias and variance. It should be complex enough to learn meaningful relationships but not so complex that it memorizes noise. In real projects, this balance is achieved through careful model selection, validation, regularization, data quality checks, and repeated testing.
For example, imagine building a model to predict student exam scores. The actual score may depend on multiple factors such as study hours, attendance, sleep quality, previous academic performance, and stress level.
- If the model only uses study hours to predict the score, it becomes too simple and cannot capture the real relationship between the data and the outcome. The predictions will be inaccurate for both training and testing data. This represents high bias (underfitting).
- On the other hand, if the model memorizes every small detail from the training dataset, including unusual cases or random noise such as “a student wore a red shirt during the exam,” the model may achieve extremely high accuracy on training data but fail on new students. This represents high variance (overfitting).
A well-balanced model considers the important factors without memorizing irrelevant noise. As a result, it can generalize better and produce more accurate predictions on unseen data. This balance between avoiding underfitting and overfitting is known as the Bias-Variance Tradeoff.
After a model reaches a better balance between bias and variance, teams need to test how it performs in real applications. Serverless Inference allows teams to integrate AI models into agents and applications via API, with OpenAI-compatible APIs and 20+ model options.

A balanced bias-variance tradeoff helps models generalize better before being tested and deployed in real applications through Serverless Inference
Overfitting happens when a model learns the training data too closely and fails on new data. Underfitting happens when a model is too simple or poorly trained to learn meaningful patterns. The best solution is to monitor training and validation metrics, improve data quality, test different configurations, and choose the right balance between bias and variance.
FPT AI Factory supports developers, data scientists, and enterprise teams across the AI development lifecycle, from GPU infrastructure to AI Studio tools and inference deployment. New users can get $100 in credits to explore our ecosystem for 30 days. For businesses or organizations that need customized or large-scale AI deployment, contact FPT AI Factory through the official contact form for consultation.
Contact information
- Hotline: 1900 638 399
- Email: support@fptcloud.com
Explore more:
What Is AI Infrastructure? Key Components and How It Works
Transfer Learning vs. Fine-Tuning: Key Differences Explained


